- The paper introduces a unified transformer framework that simultaneously recognizes sign glosses using CTC loss and translates them into natural language.
- It employs spatial embeddings from CNNs and word embeddings with positional encoding to effectively capture visual and textual information.
- Evaluations on the PHOENIX14T dataset demonstrate substantial improvements, notably more than doubling BLEU-4 scores over previous methods.
Introduction
The paper "Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation" presents an innovative approach to tackle the dual tasks of sign language recognition (SLR) and sign language translation (SLT). The authors propose a novel transformer-based architecture that enables the simultaneous training of both tasks, achieving significant improvements in performance over existing methods. This integrated model leverages the power of Connectionist Temporal Classification (CTC) loss for aligning sign glosses without relying on ground-truth timing information.
The core contribution of the paper is the introduction of the Sign Language Transformers, which jointly address the recognition and translation of sign language in an end-to-end fashion. The architecture comprises two primary components:
- Sign Language Recognition Transformer (SLRT): This model focuses on generating gloss sequences from input video frames, utilizing a stack of transformer encoder layers. By applying CTC loss, the SLRT is capable of learning temporal dependencies between frames without explicit alignment labels.
- Sign Language Translation Transformer (SLTT): The SLTT takes the spatio-temporal representations learned from the SLRT and translates them into spoken language sentences. The translation is accomplished using an autoregressive transformer decoder, which predicts sequences one word at a time based on learned contextual embeddings.
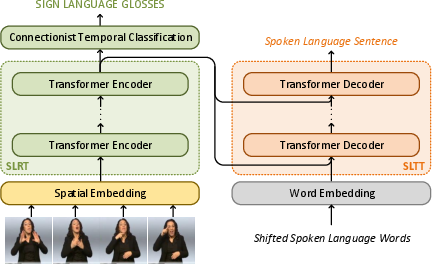
Figure 1: An overview of our end-to-end Sign Language Recognition and Translation approach using transformers.
Spatial and Word Embeddings
To effectively encode the visual and textual information, the authors employ distinct embedding strategies:
- Spatial Embeddings: Video frames are processed through pre-trained CNNs which deliver dense feature representations crucial for capturing the visual nuances of signing. Batch normalization and ReLU activation are applied to these features to enhance learning performance.
- Word Embeddings: Input sentences are transformed into word embeddings using a linear layer initialized and learned from scratch. Positional encodings supplement both spatial and word embeddings to impart temporal ordering, critical for transformer architectures devoid of recurrent components.
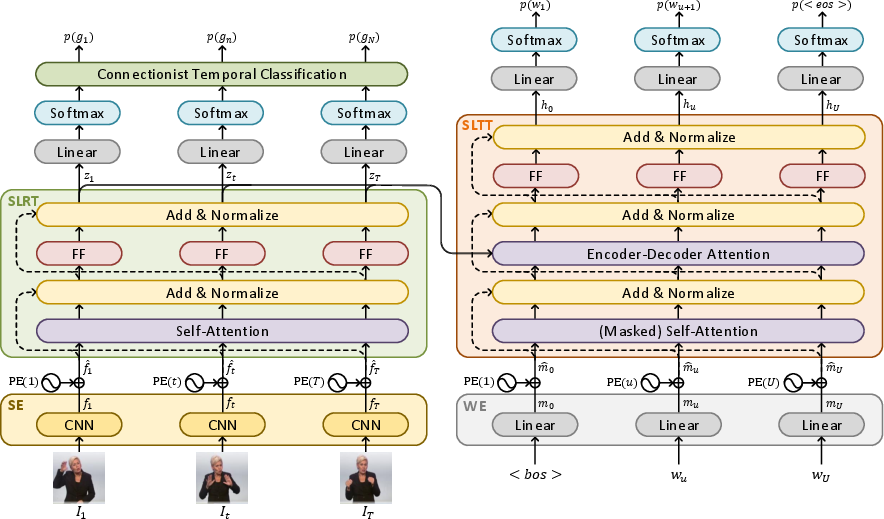
Figure 2: A detailed overview of a single layered Sign Language Transformer. \ (SE: Spatial Embedding, WE: Word Embedding , PE: Positional Encoding, FF: Feed Forward)
Evaluation and Results
The proposed method was evaluated on the PHOENIX14T dataset, notable for its comprehensive gloss and translation annotations in German sign language recognition. The Sign Language Transformers reported state-of-the-art results, particularly demonstrating substantial gains in translation tasks. When translating from video directly to text (Sign2Text), and even in the combined Sign2(Gloss+Text) task, the transformers more than doubled the BLEU-4 score of previous methods.
Significance and Future Directions
The results underscore the effectiveness of jointly learning SLR and SLT within a unified model. The insights gained from the research pave the way for future developments in automatic sign language translation systems, with potential applications extending to real-time communication aids. Future work as proposed by the authors involves expanding the capability of the models to better utilize the multi-channel nature of sign language by explicitly modeling facial, manual, and non-manual components.
Conclusion
"Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation" presents a transformative approach to bridging the semantic gap between sign language videos and spoken language. By effectively integrating recognition and translation tasks, the work sets a high standard in sign language processing, achieving unprecedented performance and providing valuable directions for future research.