Rethinking Model Size for Efficient Training and Inference of Transformers
The paper, Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers, presents a compelling examination of model size in the context of training efficiency, particularly focusing on Transformer models for NLP tasks. The research challenges the conventional paradigm where models are trained to convergence within resource constraints, advocating instead for training significantly larger models that are halted early, followed by compression to balance inference costs.
Summary of Findings
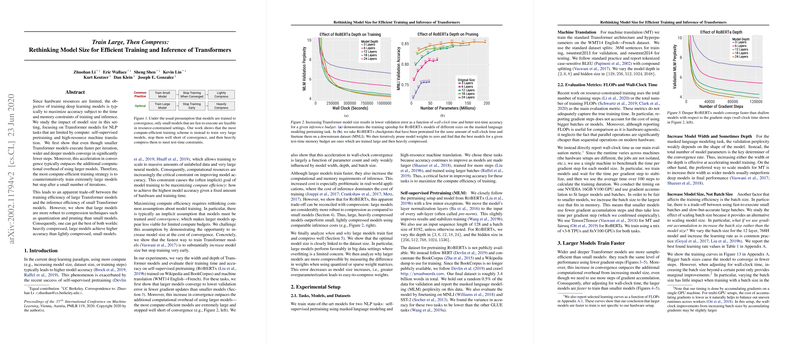
The authors systematically analyze the impact of model size on both the computational efficiency of training and the performance of inference. Their empirical results reveal that wider and deeper Transformer models converge faster in terms of gradient steps compared to smaller ones. Intriguingly, this accelerated convergence often surpasses the computational overhead incurred by running larger models, leading to faster training in terms of wall-clock time.
A crucial insight from this paper is that larger models, although seemingly more demanding in inference due to their initial size, exhibit greater resilience to compression techniques like quantization and pruning. This robustness implies that heavily compressed large models can maintain or even surpass the accuracy of lightly compressed smaller models while incurring similar inference costs.
Key Results
The paper presents several noteworthy results:
- Convergence and Computational Efficiency: Larger models achieve lower validation errors with fewer training iterations, offsetting the higher per-iteration computational cost. This efficiency suggestively contradicts the traditional assumption that only small models are feasible for training under limited compute resources.
- Compression Robustness: When comparing RoBERTa models subjected to both quantization and pruning, larger models consistently showed a smaller drop in accuracy after compression. Consequently, larger heavily compressed models offered superior accuracy within specific memory and compute budgets compared to smaller models.
- Parameter Count and Model Shape: The analysis highlighted that parameter count predominantly influences the convergence speed rather than model width or depth alone. This finding supports a strategy of increasing model size holistically rather than focusing on individual architectural attributes.
Implications and Future Directions
From a practical standpoint, this research advocates for a paradigm shift in how models are trained given fixed computational budgets. By embracing a strategy of training large models and subsequently leveraging compression, practitioners can achieve efficiencies that reconcile high training performance with manageable inference costs.
The paper opens several avenues for future research, notably exploring the theoretical underpinnings of why larger models exhibit improved compression resilience. Additionally, investigating the role of overfitting in more distinct settings, such as low-data regimes, could further elucidate when and why larger models outperform smaller counterparts. This work also suggests potential applications beyond NLP, including computer vision, where similar computational and performance trade-offs exist.
In conclusion, the paper effectively shifts a critical component of modern machine learning pipeline—emphasizing that training larger models optimally, terminating their training at the right juncture, and smartly compressing their architecture can yield significant computational and performance advantages. As machine learning systems continue to scale, such insights are invaluable for both theory-driven exploration and practically efficient model deployment.