- The paper's main contribution is a detailed tutorial that unifies LSTM-RNN notation and corrects common errors in earlier studies.
- It explains how LSTM overcomes the vanishing gradient problem using Constant Error Carousel and gated memory mechanisms.
- The tutorial also discusses training complexities and various LSTM extensions, providing a robust foundation for further neural network research.
Tutorial on Long Short-Term Memory Recurrent Neural Networks (LSTM-RNN)
Introduction
The paper "Understanding LSTM -- a tutorial into Long Short-Term Memory Recurrent Neural Networks" provides an elaborate tutorial on LSTM-RNNs, a type of dynamic classifier renowned for handling long-term dependencies in sequential data. Situating itself as a supplementary pedagogic tool, the work brings together historical iterations of LSTM-RNNs, exposing the prevailing errata across publications, offering an improved, error-reduced exposition with unified notation. The authors aim to demystify the architectural and algorithmic elements of LSTM networks that contribute to their impressive capability in handling prolonged dependencies beyond typical RNNs' reach.
The Perceptron and Its Limitations
The perceptron is posited as the fundamental building block of neural networks, operating with weighted inputs and a threshold mechanism that dictates its activation. Perceptrons can only model linearly separable functions.
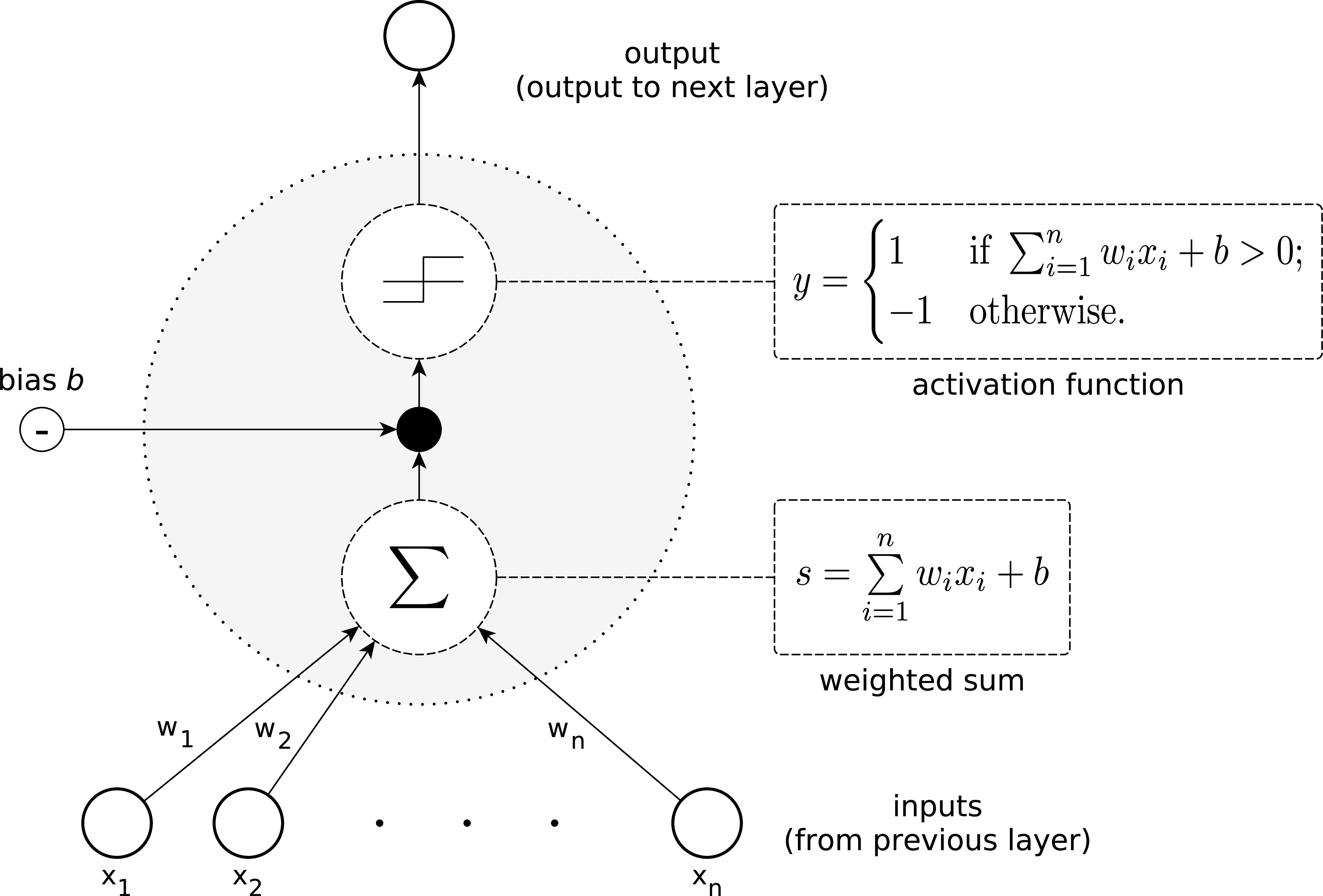
Figure 1: The general structure of the most basic type of artificial neuron, called a perceptron. Single perceptrons are limited to learning linearly separable functions.
However, perceptrons' potential is extended through networks where neuron outputs are processed through non-linear functions like the sigmoid threshold unit (Figure 2), enabling the network to handle non-linear decision boundaries.
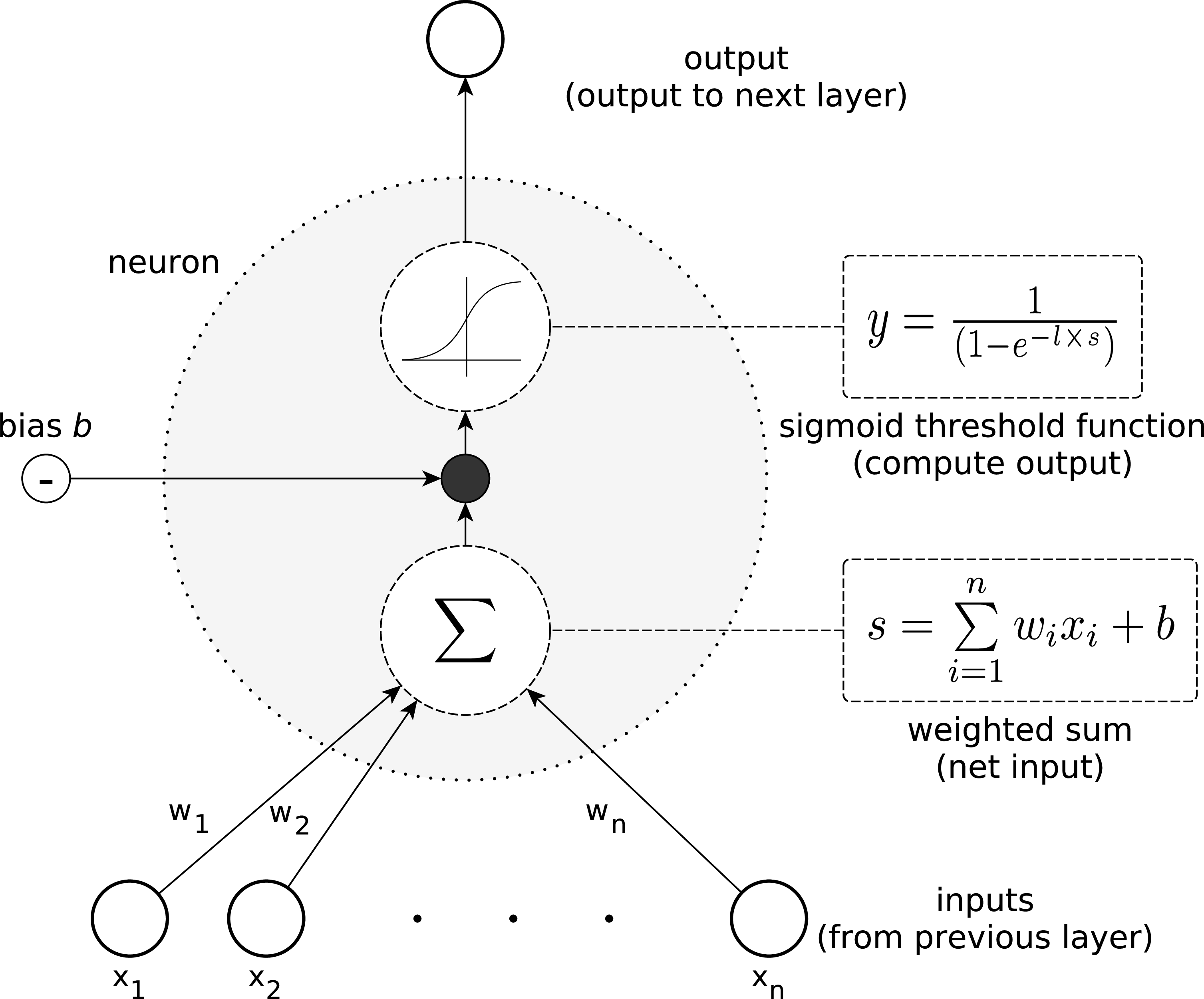
Figure 2: The sigmoid threshold unit is capable of representing non-linear functions. Its output is a continuous function of its input, which ranges between 0 and 1.
LSTM Networks: Addressing RNN Limitations
RNNs, with their recurrent connections, enable some degree of memory by processing inputs over time steps. However, they suffer from the vanishing gradient problem, inhibiting them from learning dependencies beyond ten time steps.
This limitation is comprehensively addressed by the LSTM architecture, which introduces memory blocks containing cells with Constant Error Carousel (CEC) mechanisms and regulated access through input/output gates (Figure 3). The CEC architecture ensures a constant gradient flow, preventing vanishing gradients and retaining memory over 1,000 time steps.
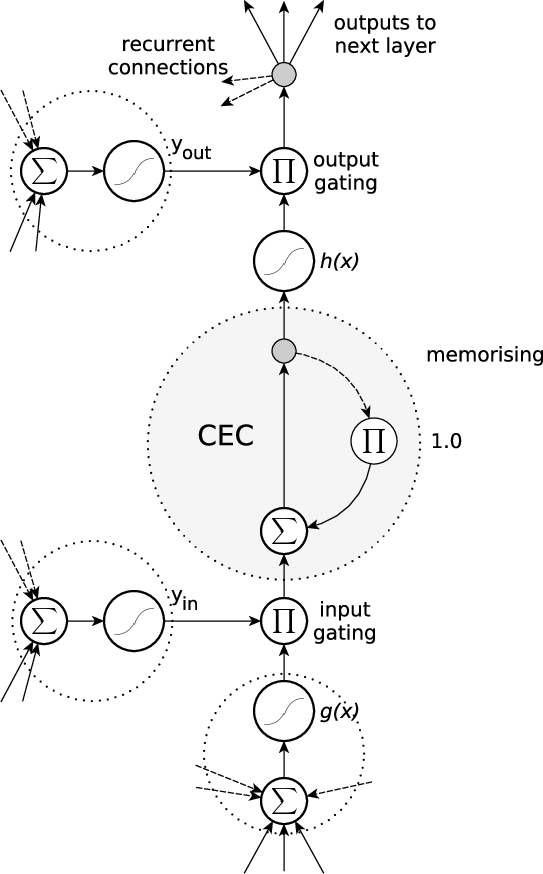
Figure 3: A standard LSTM memory block with a recurrent self-connection (CEC) and weight of '1'. The state of the cell is denoted as sc. Read and write access is regulated by the input gate, yin, and the output gate, yout. The internal cell state is calculated by multiplying the result of the squashed input, g, by the input gate result, yin, and then adding the state of the last time step, sc(t−1). Finally, the cell output is calculated by multiplying the cell state, sc, by the activation of the output gate, yout.
Training and Complexities
The training of LSTM networks leverages both BPTT and RTRL algorithms. While BPTT is utilized for components post-cell, the computation within memory blocks utilizes RTRL due to the requirement of handling the continuous state transitions without discrete updates typical of BPTT.
The complexity of training is crucially dependent on the network topology—specifically, the number of memory blocks and internal connections—which dictates computational demands.
Extensions and Variants
Research subsequently offered various LSTM adaptations: bidirectional LSTM (BLSTM) for handling sequences from both directions and attention mechanisms for improving the processing of complex sequences. Additionally, grid LSTM extends the conventional LSTM into multidimensional grids, augmenting its capability to handle spatial data, while the Gated Recurrent Unit (GRU) offers an alternative architecture with reduced complexity and potentially superior performance on certain tasks.
Applications and Future Directions
LSTM networks have found application in cognitive tasks such as speech and handwriting recognition, and more recently, machine translation. Beyond these, LSTM's adaptability allows modeling in diverse fields like protein structure prediction and network intrusion detection. As architectures like GRU and attention-based approaches advance, they challenge the LSTM's dominance, promising further evolutions in the architectural design space.
In summary, the tutorial elucidates from theory to practice the architectural and functional underpinnings of LSTMs, fostering a deeper understanding among machine learning researchers and practitioners. Its grounded historical account, combined with practical exploration, offers a solid foundation for those engaged in advancing neural network technologies.