- The paper demonstrates that the ring allreduce architecture significantly outperforms PS and P2P by efficiently overlapping computation and communication.
- The study employs analytical models and experiments using TensorFlow and Horovod with the MNIST dataset to benchmark latency and throughput.
- The findings highlight RA's scalability and optimal bandwidth usage, suggesting promising directions for mitigating network congestion in distributed training.
This essay discusses the comparative performance analysis of distributed machine learning architectures used for training deep learning models. The study focuses on evaluating the communication bottlenecks in three parallel training architectures: Parameter Server (PS), Peer-to-Peer (P2P), and Ring Allreduce (RA). It further analyzes their impact on the computation cycle time and scalability using synchronous Stochastic Gradient Descent (SGD).
Introduction to Distributed Training Architectures
Deep Neural Networks (DNNs) have made significant advances in a variety of tasks but require substantial computational resources and large datasets. Distributed training frameworks have been developed to leverage multiple nodes for efficient training. These frameworks must efficiently coordinate state and parameter sharing, imposing challenges in consistency, fault tolerance, and communication overhead.
The PS architecture involves workers that pull model parameters from a server, perform computations, and send updates back to the server. In contrast, the P2P model combines worker and server processes, facilitating local model updates and inter-peer exchanges. In the RA architecture, a ring-based communication pattern is employed, ensuring that gradients are efficiently shared among workers without centralized servers.
Figure 1: Deep Neural Networks.
The study addresses the performance of PS, P2P, and RA architectures through both analytical and empirical approaches. Analytical models estimate computation and communication times involved in training:
- Parameter Server Architecture: Known for potential communication bottlenecks due to centralized server architecture, PS performance degrades when a high number of workers concurrently update parameters, leading to server congestion.
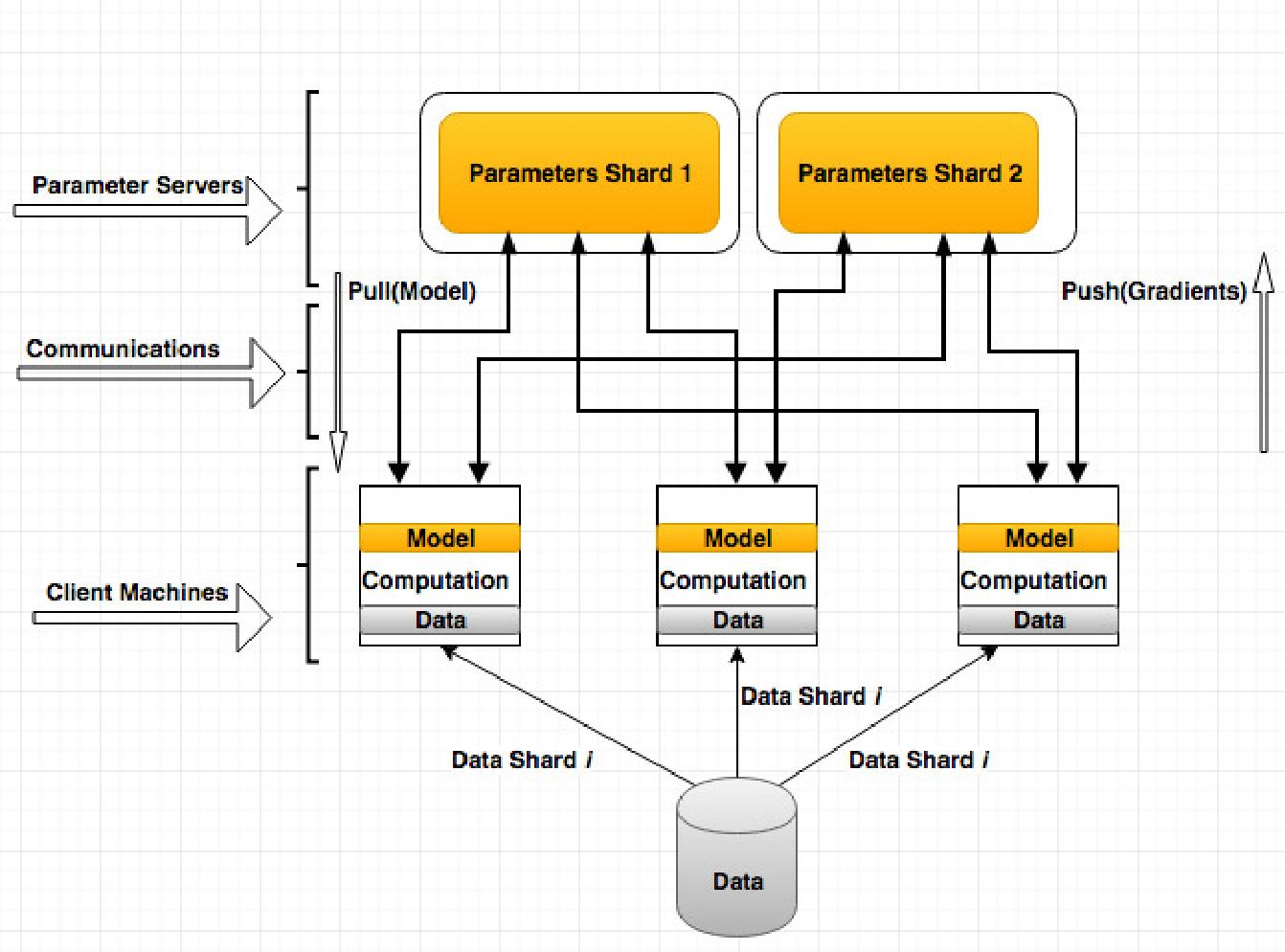
Figure 2: PS Architecture.
- Peer-to-Peer Architecture: P2P systems benefit from localized model updates but still suffer from network latency when gradients need to be synchronized across nodes.
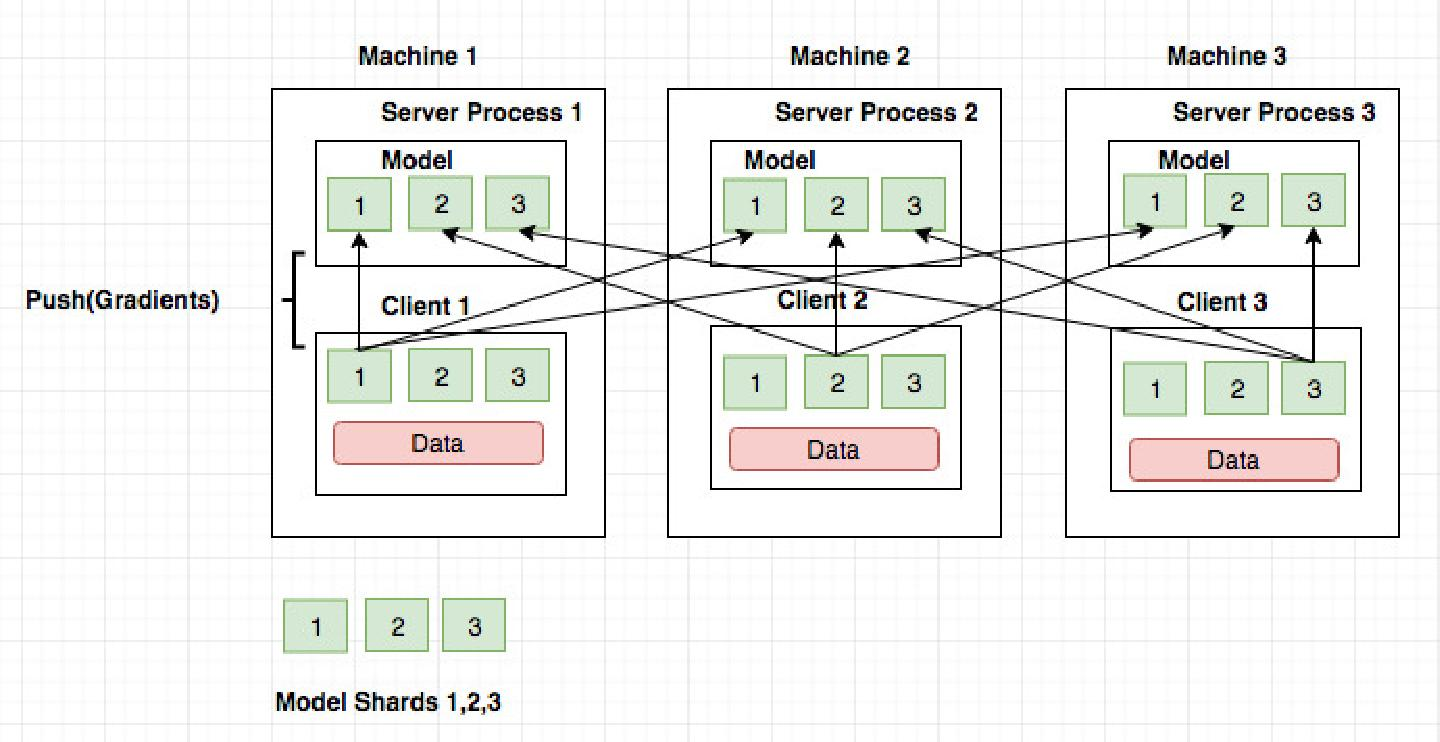
Figure 3: P2P based Architecture.
- Ring Allreduce Architecture: RA architecture exhibits superior performance as it decouples network usage from the number of workers, achieving high throughput and scalable communication.
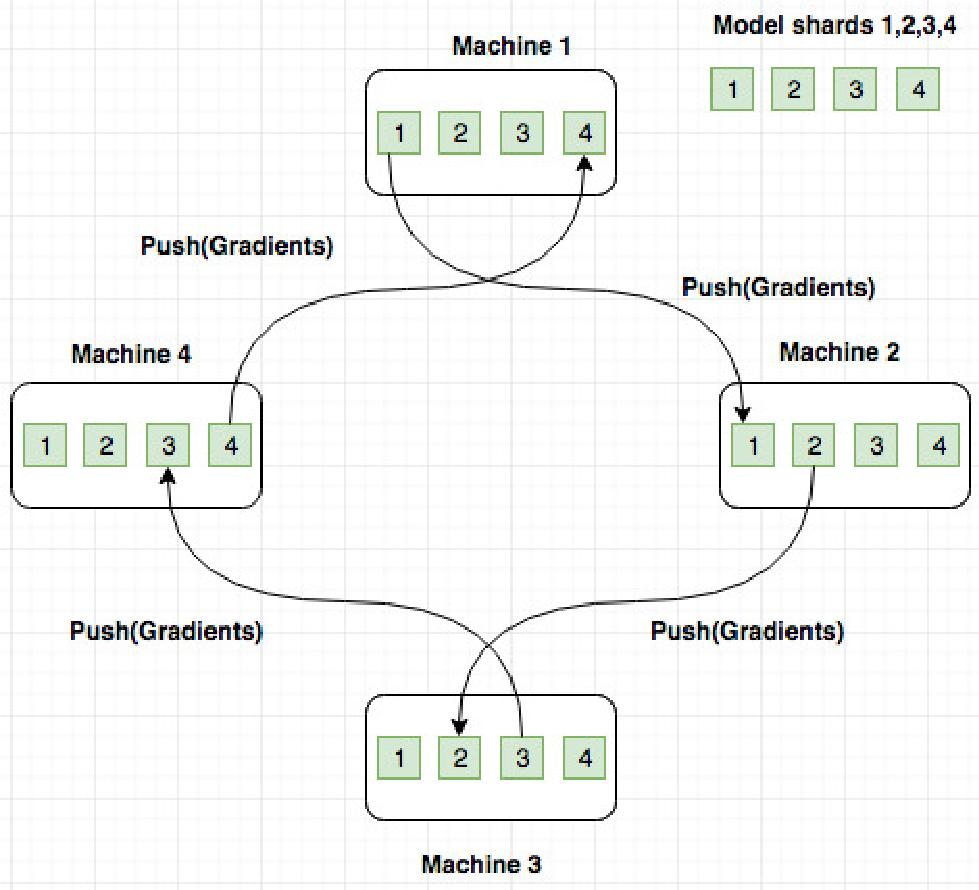
Figure 4: RA Architecture.
Experimental Evaluation
The paper conducts experimental evaluations using TensorFlow and Horovod frameworks, with the MNIST dataset as a benchmark. The study measures throughput (training samples per second) and latency for various configurations:
- Parameter Server (PS): 1PS systems suffer from high latency due to shared bandwidth limitations. Increasing the number of parameter servers to 2PS and 4PS slightly alleviates congestion but does not substantially increase throughput due to inherent communication centralization.
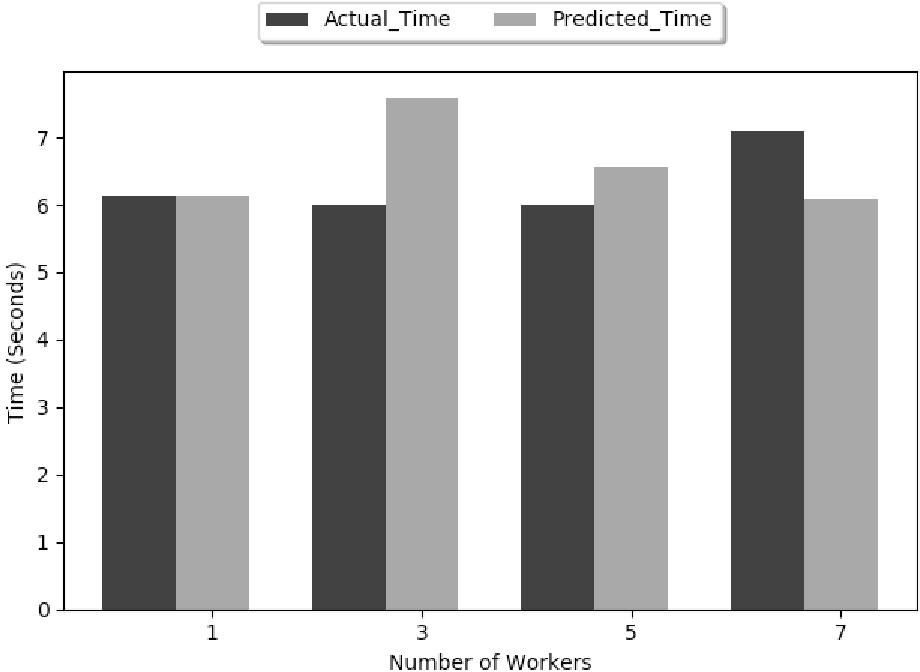
Figure 5: Estimated epoch time for 1PS.
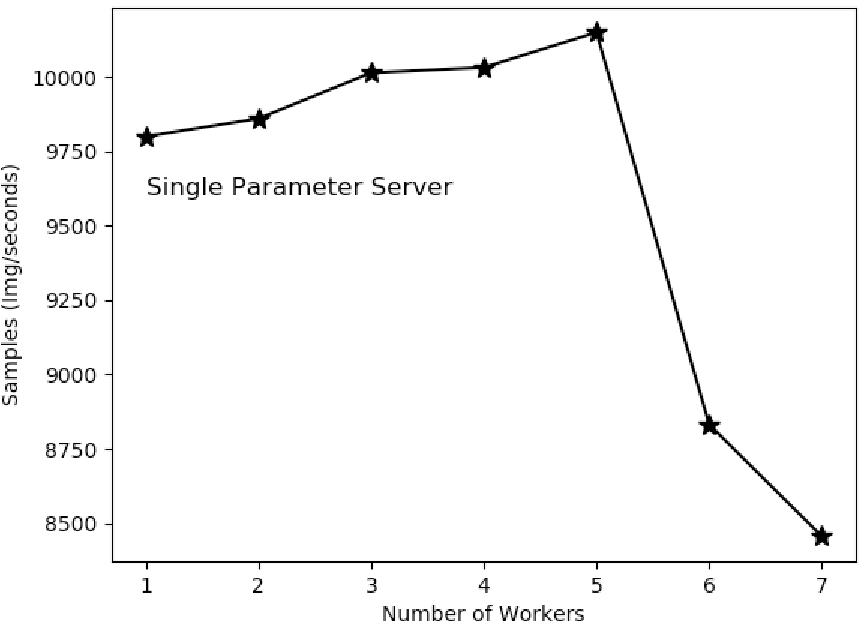
Figure 6: Measured training throughput of 1PS.
- Peer-to-Peer (P2P): Improved over PS due to distributed communication but limited by network saturation when scaling beyond certain nodes.
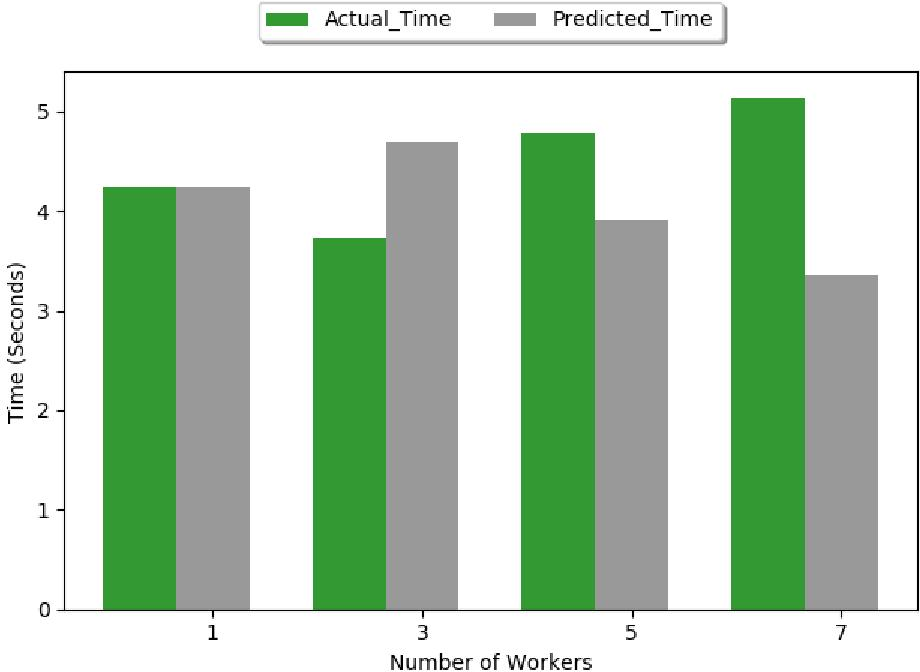
Figure 7: Estimated epoch time for P2P system.
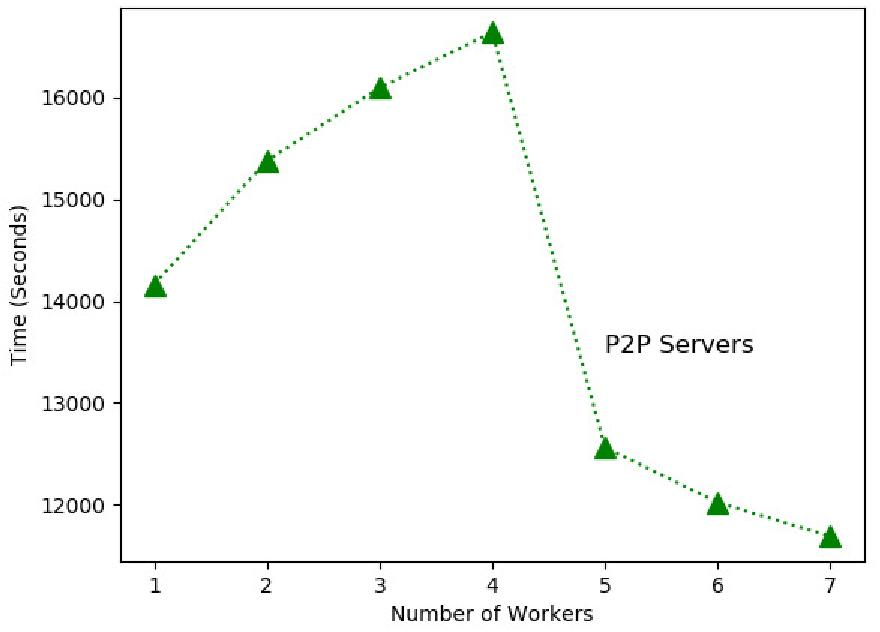
Figure 8: Measured training throughput of P2P system.
- Ring Allreduce (RA): RA outperforms both PS and P2P in terms of both latency and throughput, effectively overlapping computation with communication due to its decentralized nature.
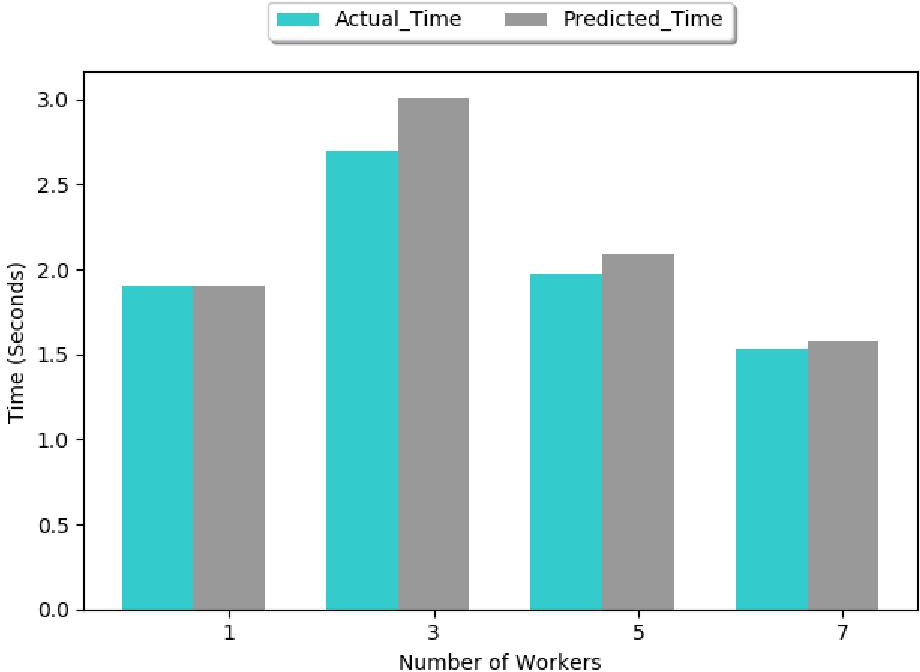
Figure 9: Estimated epoch time for RA.
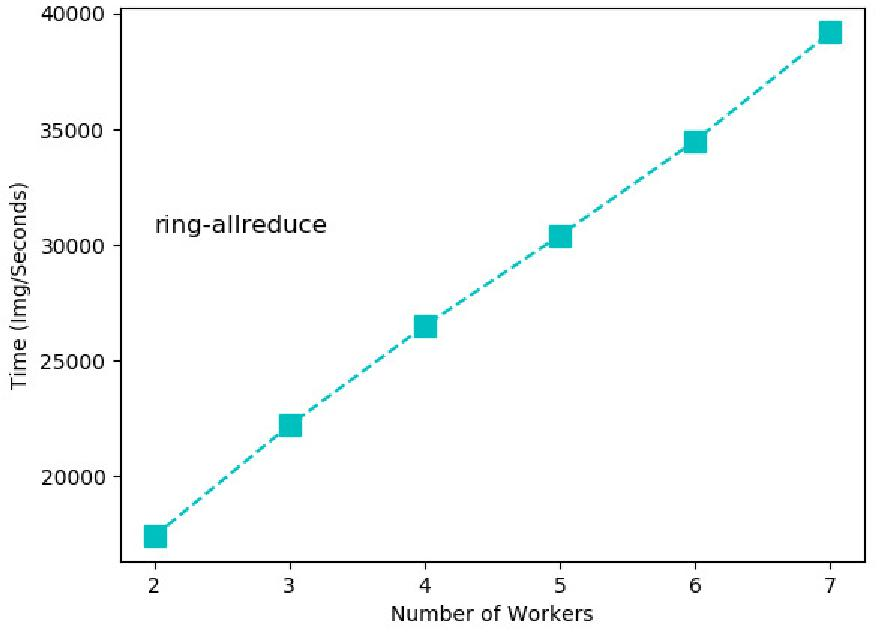
Figure 10: Measured training throughput of RA.
Implications and Future Work
The RA architecture demonstrates a performance advantage in distributed deep learning tasks due to its efficient use of bandwidth and overlap of compute and communication phases. While PS suffers from network congestion, P2P is constrained by synchronization complexities. Future research could focus on reducing network congestion and optimizing computation-communication trade-offs, facilitating improved scalability and performance in distributed DNN training systems.
Conclusion
In conclusion, the comparative analysis reveals substantial performance disparities among different distributed machine learning architectures. RA's optimal bandwidth usage and inherent scalability make it a preferable choice for large-scale DNN training, while PS and P2P systems require careful configuration to mitigate communication bottlenecks. This work informs better choices in architectural design and tuning for practitioners deploying distributed machine learning systems.

