- The paper introduces BlazeFace, a neural network that achieves sub-millisecond face detection on mobile GPUs by leveraging a lightweight feature extractor and an optimized GPU-friendly anchor scheme.
- The model demonstrates up to 1000+ FPS and 98.61% average precision on flagship devices, outperforming conventional methods like MobileNetV2-SSD.
- BlazeFace supports real-time AR pipelines by delivering accurate facial keypoints and expression classification with enhanced stability via a tie resolution strategy.
BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
Introduction
The paper presents BlazeFace, a neural network model specifically designed for face detection on mobile GPUs. Unlike conventional detection frameworks, BlazeFace achieves remarkable inference speeds ranging from 200 to 1000+ FPS on high-end devices. This performance makes BlazeFace highly suitable for augmented reality (AR) pipelines where precise face detection is critical for tasks such as facial keypoint estimation, expression classification, and face region segmentation.
Architectural Innovations
BlazeFace introduces multiple architectural innovations:
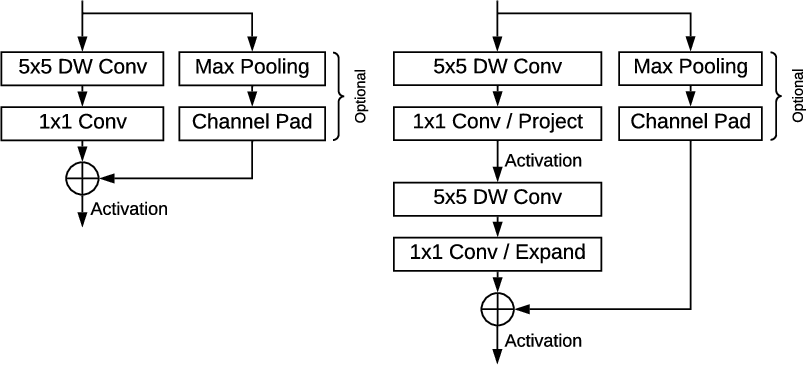
- Lightweight Feature Extractor:
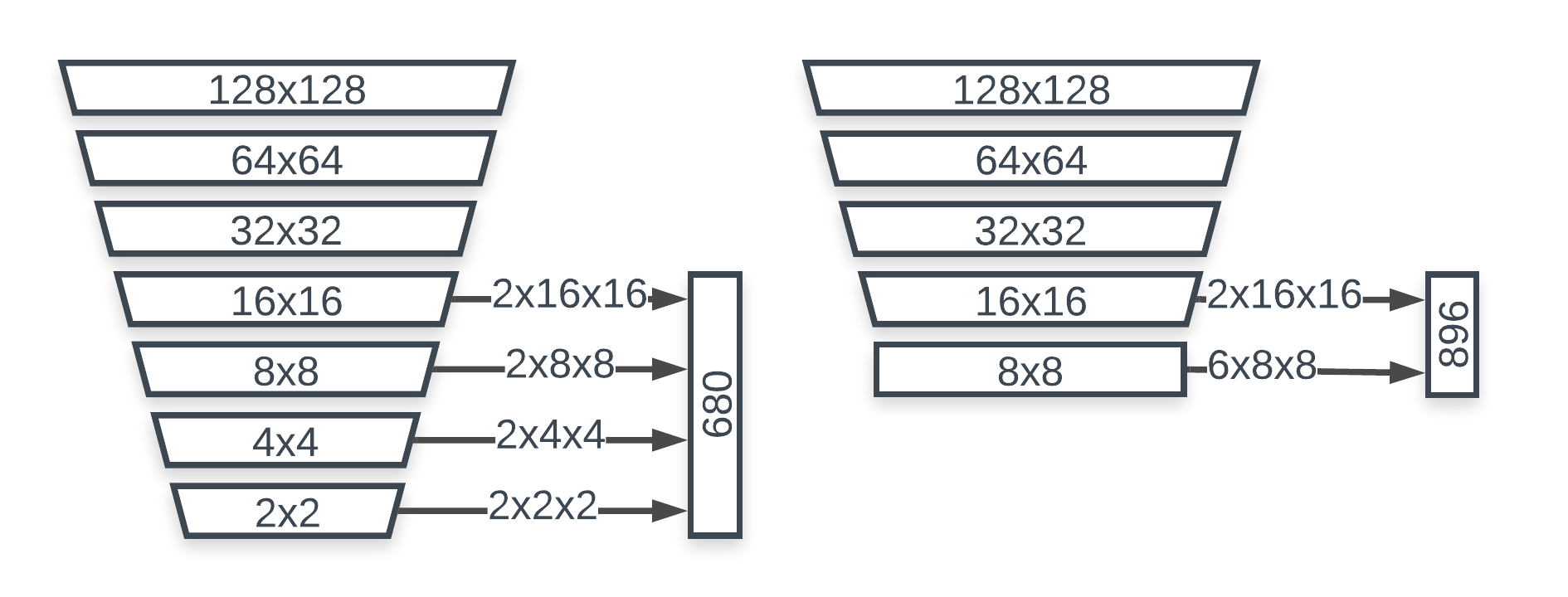
- GPU-friendly Anchor Scheme:
- Tie Resolution Strategy:
- BlazeFace employs a blending strategy that averages overlapping predictions, optimizing prediction stability over time and replacing traditional non-maximum suppression. This was demonstrated to enhance accuracy by 10% and reduce jitter by 30-40%.
Through extensive evaluations performed on several flagship mobile devices, BlazeFace demonstrates significant advancements over existing models. On an Apple iPhone XS, this model performs inference at 0.6 ms, a substantial improvement over comparable models like MobileNetV2-SSD, which runs at an average of 2.1 ms. The average precision (AP) for BlazeFace reaches 98.61%, indicating superior detection capabilities while maintaining minimal computational overhead.
Applications in AR Pipelines
The effectiveness of BlazeFace was tested in downstream AR applications. By specializing in face detection, BlazeFace efficiently provides the bounding faces and keypoints, crucial for precise facial alignment in 2D/3D facial keypoint extraction and expression classification. The model enhances subsequent face-specific computations by delivering rotated and centered face crops, reducing the invariance requirement for task-specific models.
(Figure 3)
Figure 3: Application pipeline example demonstrating BlazeFace's output juxtaposed with subsequent task-specific processing.
This efficient pipeline is vital for real-time AR applications, as it ensures precise tracking capabilities with minimal latency.
Conclusion
BlazeFace represents a pivotal step toward real-time face detection on mobile platforms by leveraging optimizations tailored for GPU inference. Its high performance, achieved through innovative architectural adjustments, not only benefits AR applications but also extends to various other domains requiring rapid and reliable face detection. The model sets a new standard in balancing speed and accuracy, facilitating broader adoption in embedded systems and mobile AR solutions. Future developments could explore further architectural refinements and adapt BlazeFace to encompass additional face attributes, enhancing its applicability across a wider spectrum of applications.