- The paper introduces HyperGAN, a GAN-based model that generates diverse neural network parameters using a novel mixer and adversarial regularization.
- It achieves competitive performance on tasks like MNIST and CIFAR-10 while improving uncertainty estimation and defense against adversarial attacks.
- Ablation studies confirm that removing key components like the mixer or discriminator significantly reduces network diversity and initial performance.
Introduction
The paper presents HyperGAN, a novel generative model designed to create diverse and performant neural network parameters. HyperGAN significantly enhances the creation of neural network ensembles by generating a distribution of parameters without relying on restrictive priors or extensive training sets of pre-trained models. The model integrates a new component called the "mixer," which projects prior samples into a latent space to create correlated dimensions necessary for generating individual layers. This facilitates the construction of large, diverse neural network ensembles efficiently.
HyperGAN Architecture
HyperGAN uses a generative adversarial network (GAN) framework to generate neural network parameters. It consists of a sampler drawing samples from a multivariate Gaussian distribution, a mixer transforming these samples into correlated latent vectors, and multiple generators converting each latent vector into layer-specific parameters.
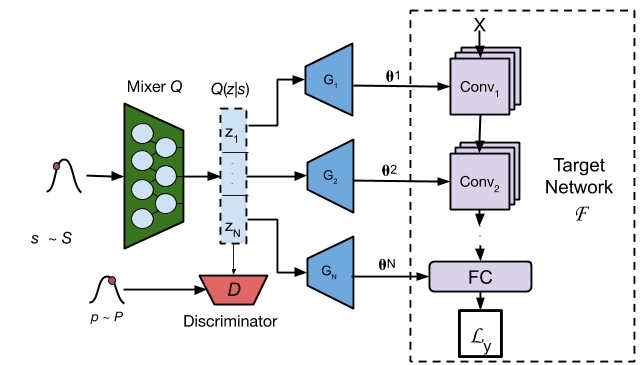
Figure 1: HyperGAN architecture. The mixer transforms s∼S into latent codes {z1,…,zN}. The generators transform each qi into parameters for the matching layer in the target network. The discriminator forces Q(z∣s) to be well-distributed and close to P.
The key components and their roles are as follows:
- Mixer: Introduces correlations into independent samples from a Gaussian distribution, creating N distinct vectors for each network layer.
- Generator: Converts correlated latent vectors into parameters for individual layers.
- Discriminator: Ensures the mixed latent space closely matches a prior distribution, preventing mode collapse and enhancing diversity.
The efficacy of HyperGAN is evaluated across multiple tasks, demonstrating competitive classification accuracy with networks generated from stochastic ensembles. On datasets like MNIST and CIFAR-10, HyperGAN achieves performance on par with or better than traditional ensembles and other state-of-the-art methods like APD, MNF, and MC Dropout.
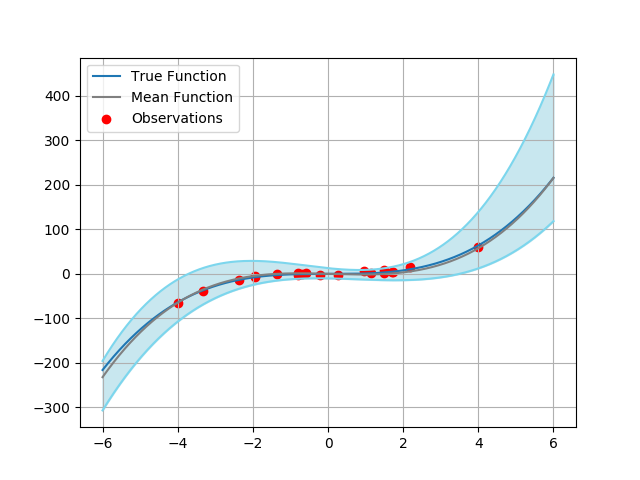
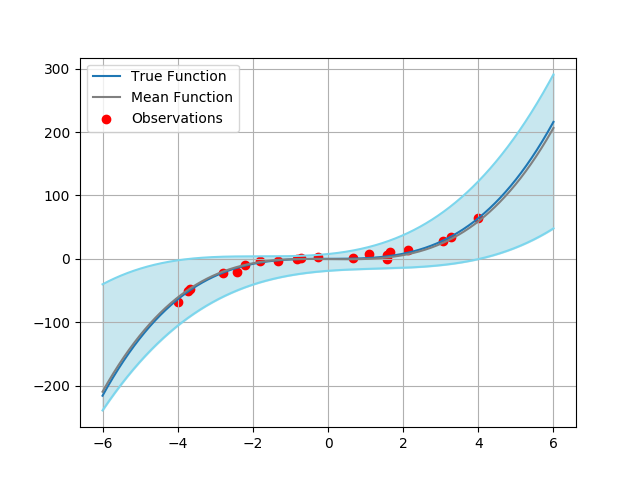
Figure 2: Results of HyperGAN on the 1D regression task. From left to right, we plot the predictive distribution of 10 and 100 sampled models from a trained HyperGAN. Within each image, the blue line is the target function x3, the red circles show the noisy observations, the grey line is the learned mean function, and the light blue shaded region denotes ±3 standard deviations.
HyperGAN's capacity to maintain diversity is particularly noteworthy due to the mixer and adversarial regularization. Experiments show that HyperGAN-generated networks exhibit higher variance in layer parameters compared to traditional methods, contributing to robustness and superior generalization.
Uncertainty Estimates and Robustness
HyperGAN excels in uncertainty estimation, notably on out-of-distribution data and adversarial examples. By analyzing predictive entropy, HyperGAN's ensembles display superior performance in distinguishing inliers from outliers, as illustrated with notMNIST and CIFAR-10 anomaly detection tests.
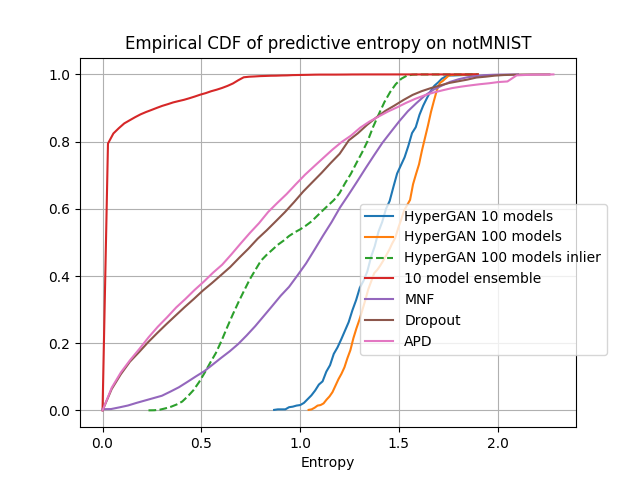
Figure 3: Empirical CDF of the predictive entropy of all approaches on notMNIST. One can see the entropy of HyperGAN models are significantly higher than baselines.
In adversarial settings, HyperGAN effectively identifies examples that transfer poorly across diverse models, offering resilience against both FGSM and PGD attacks. The diversity of generated ensembles facilitates detection of adversarial instances by maintaining high predictive entropy, enhancing defensive capabilities.
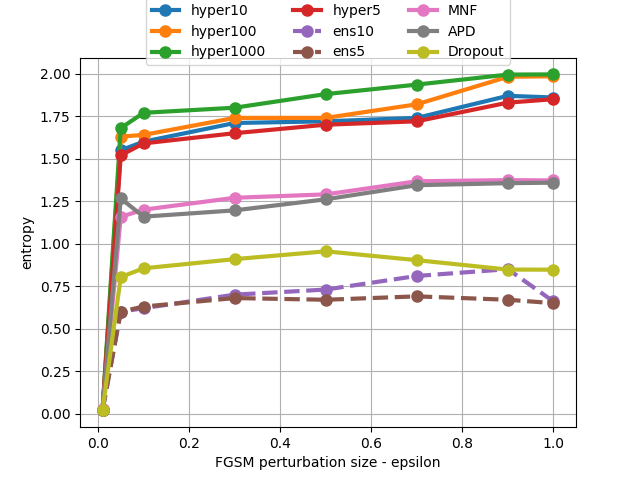
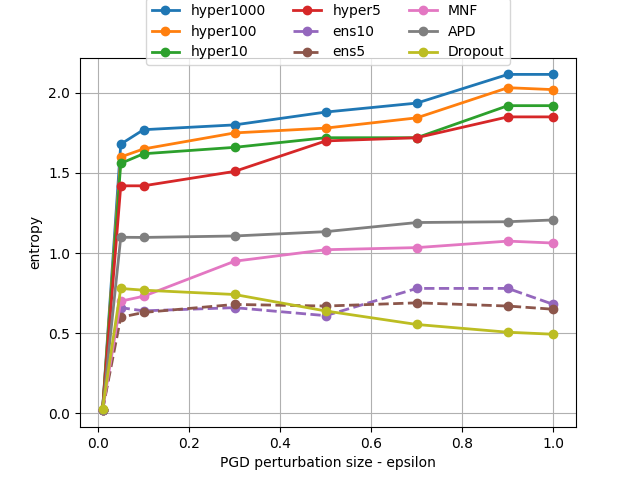
Figure 4: Entropy of predictions on FGSM and PGD adversarial examples. HyperGAN generates ensembles that are far more effective than standard ensembles even with equal population size. Note that for large ensembles, it is hard to find adversarial examples with small norms e.g. ϵ=0.01.
Ablation Studies
Ablation studies on HyperGAN emphasize the necessity of both the mixer and adversarial regularization for maintaining network diversity. Removing the mixer reduced the model's initial performance, while the absence of the discriminator decreased diversity, demonstrating each element's integral role in the architecture.
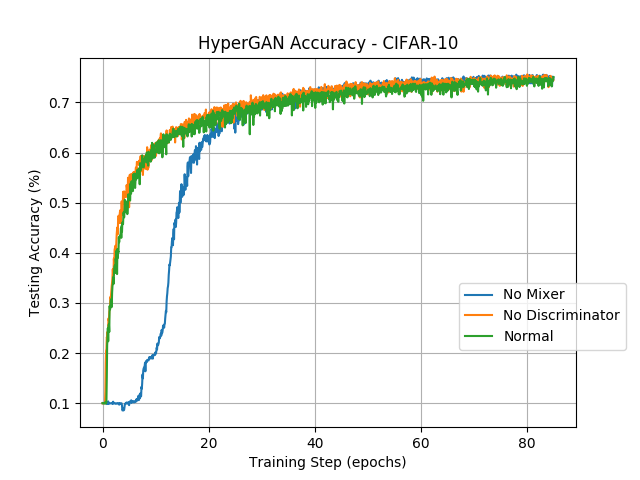
Figure 5: Study of HyperGAN accuracy on CIFAR-10, with normal HyperGAN, without the mixer, and without the discriminator, respectively. Each test converges to similar accuracy but the variant without the mixer stumbles significantly in the beginning.
Conclusion
HyperGAN offers an efficient, scalable method for generating diverse, performant neural network parameters, excelling in classification tasks, uncertainty estimation, and robustness to adversarial examples. Its novel use of a mixer and adversarial regularization paves the way for further advancements in meta learning and ensemble-based approaches, potentially influencing broader AI application domains. Future work could explore early stopping strategies and extend HyperGAN's architectural innovations to more sophisticated learning paradigms.

