- The paper shows that domain randomization on synthetic datasets achieves a 25% mAP improvement in object detection.
- Methodology uses a modified Gazebo plugin to generate diverse textures and scenes for training the SSD detector.
- Results indicate that fixed viewpoint configurations yield higher precision compared to varied viewpoints in synthetic training.
Applying Domain Randomization to Synthetic Data for Object Category Detection
The paper "Applying Domain Randomization to Synthetic Data for Object Category Detection" (1807.09834) investigates the application of domain randomization to enhance object category detection methods using synthetic data. This essay will summarize the major contributions, results, and implications of the research presented.
Introduction and Background
The challenge of training deep learning-based object detection models lies in requiring large, annotated datasets, which are often challenging and costly to produce. Traditional approaches rely on pre-trained models on large datasets like COCO or ImageNet, followed by domain adaptation. However, this paper proposes the use of domain-randomized synthetic datasets, which can offer a significant performance boost over conventional fine-tuning.
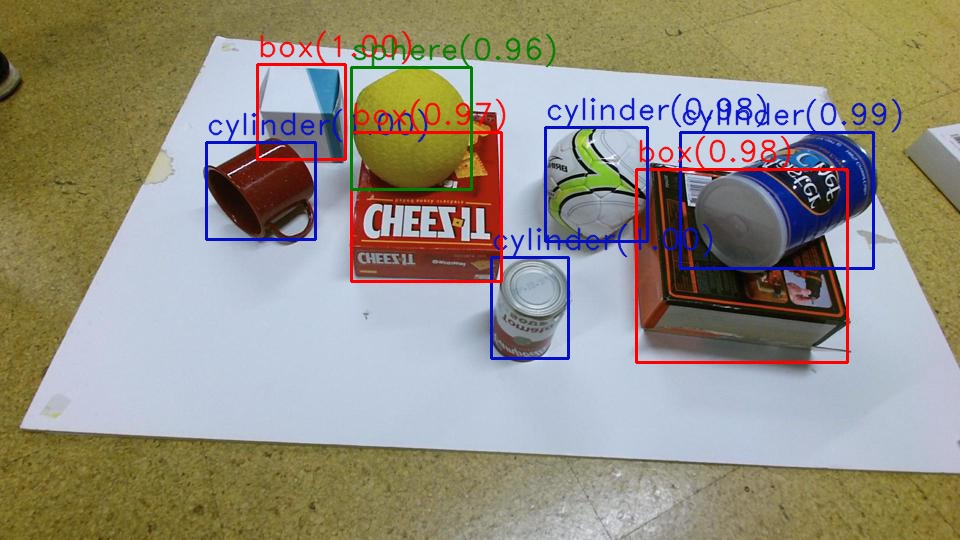
Figure 1: An example image from the test set, annotated by the object detector. Annotations are red for boxes, blue for cylinders, and green for spheres.
The study specifically focuses on categories involving shapes such as cylinders, spheres, and boxes detected via the Single Shot Multibox Detector (SSD). Employing a Gazebo simulator plugin, the authors generate synthetic scenes by significantly varying visual parameters, thus facilitating robust model training that can generalize well to real-world conditions.
Methodology
The methodology centers on a comprehensive experimental setup that includes the generation of synthetic datasets with varied camera poses and textures. The SSD network, particularly with a MobileNet base, is trained on these synthetic datasets and subsequently tested on real-world data. The research also involves modifications to the Gazebo plugin to optimize synthetic scene generation, effectively doubling scene rendering speed.

Figure 2: Example synthetic scene employing all 4 texture patterns. Labelled by the plug-in. The ground has a flat color, box has gradient, cylinder has chess, and sphere has Perlin noise.
Key components include:
- Domain Randomization: Introducing variability in camera angles, lighting, and textures to create a diverse training set.
- Gazebo Enhancements: Improvements to the plugin that increase the efficiency of texture application and scene composition.
Experiments and Results
The experiments span training with datasets where the viewpoint is static versus those where it varies, each comprising 30k images. The results are benchmarked using mean Average Precision (mAP) and show that domain randomization, even without photo-realism, significantly enhances detection capabilities when a limited set of real data is available for fine-tuning.
Key Findings:
- Synthetic datasets enable an impressive 25% improvement in mAP over the conventional fine-tuning baseline.
- Fixed viewpoint configuration in synthetic data leads to better performance compared to varied viewpoint setups. This suggests that while viewpoint variability might enhance robustness, it could reduce precision when the real-world testing set doesn't match the synthetic set's variability.
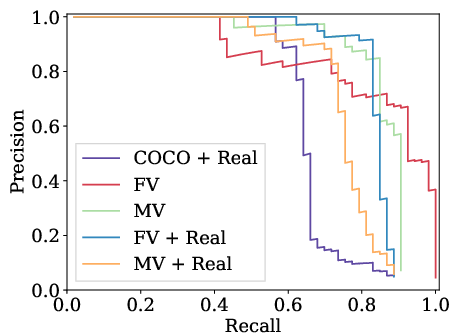
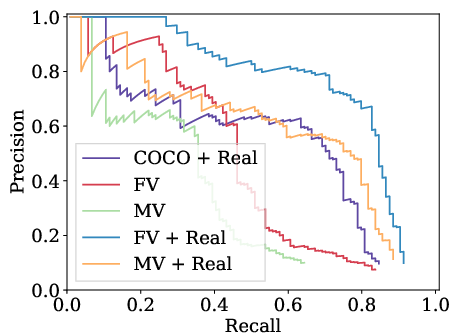
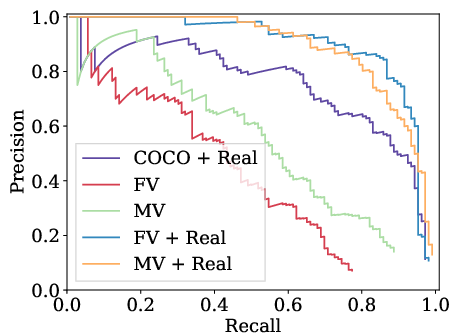
Figure 3: Precision-recall curves of different variants of the detectors. For abbreviations refer to Fig.~\ref{fig:ap_30k
Ablation Study:
An ablation study quantifies the impact of individual texture components, highlighting Perlin noise as crucial for achieving high mAP scores, while flat colors contribute the least.
Implications and Future Work
The research has solid implications for efficiently training object detection models where domain-specific data is scant. With robotics as a significant potential application area, domain randomization applied through enhanced simulation tools like Gazebo can facilitate experiments involving real-time object interaction and manipulation.
The study opens pathways for further exploration into domain adaptation using synthetic data, particularly in complex settings such as instance segmentation. Enhancements in synthetic data generation, such as allowing multiple textures per object, could expand application scenarios.
Conclusion
This paper demonstrates that robust object detectors can be effectively trained using non-photo-realistic synthetic datasets augmented with domain randomization, leading to significant improvements in detection performance under data-scarce conditions. These results indicate a practical direction for extending domain randomization methods to various AI and robotics applications. Future research should continue refining these methods, particularly in adapting more complex vision tasks.