- The paper presents a hierarchical network that fuses fine-grained patches to learn both intra- and inter-modality correlations.
- It utilizes a multi-task learning paradigm combining reconstruction, classification, and contrastive losses to enhance retrieval accuracy.
- Experimental results on benchmarks like Wikipedia and NUS-WIDE demonstrate that CCL significantly outperforms traditional methods with robust MAP improvements.
Cross-modal Correlation Learning with Multi-grained Fusion by Hierarchical Network: An Expert Analysis
Introduction
The proliferation of multimodal data in real-world applications has foregrounded the necessity for effective cross-modal retrieval—retrieving data of a different modality from a given query. The primary challenge arises from the intrinsic heterogeneity gap between different modalities, complicating efforts to align distributions and representations across media such as images and text. Canonical approaches mostly cast cross-modal retrieval as a two-stage deep learning problem: first, learning modality-separate representations, and then projecting them into a shared latent space. However, these strategies overlook the complementary benefits of intra- and inter-modality correlation modeling and ignore valuable fine-grained cues from patches within modalities.
This work introduces Cross-modal Correlation Learning (CCL) with multi-grained fusion, utilizing a hierarchical deep network architecture to explicitly model both intra- and inter-modality correlations at multiple granularities, and to optimize for cross-modal retrieval accuracy through a unified multi-task learning paradigm.
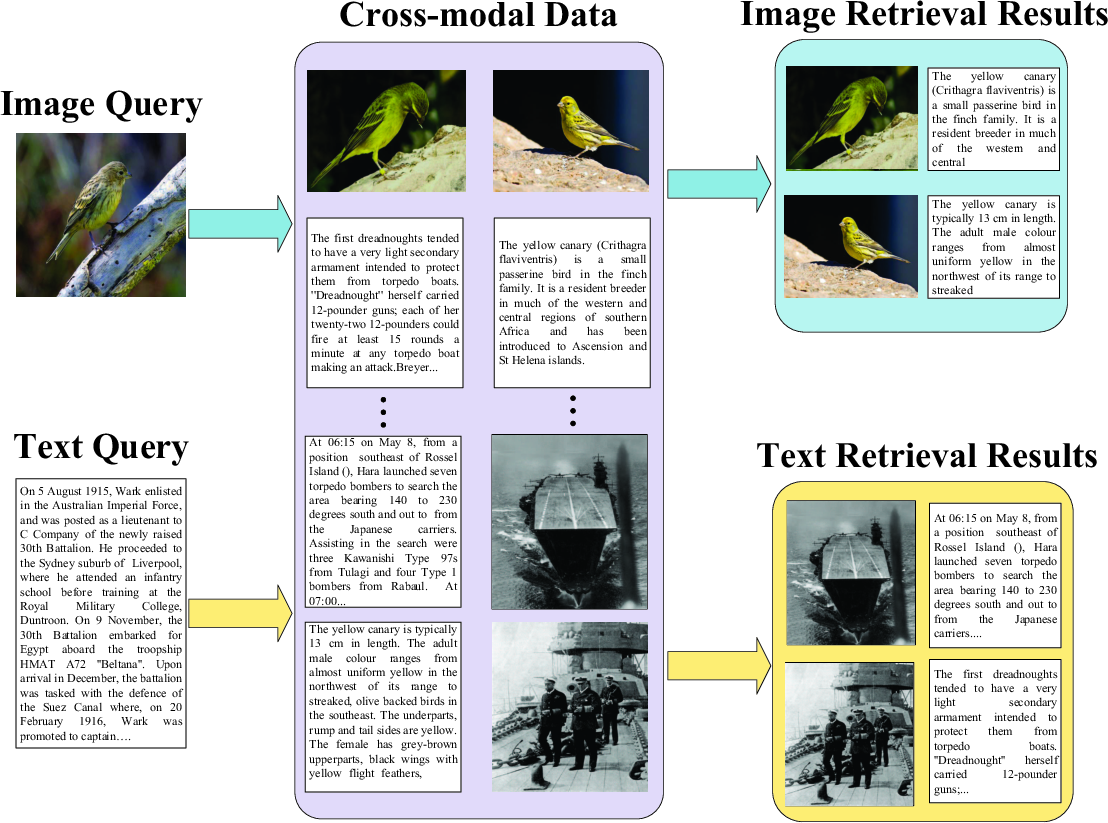
Figure 1: An example of cross-modal retrieval with image and text, which can present retrieval results with different modalities.
Earlier approaches to cross-modal retrieval, notably canonical correlation analysis (CCA) and its derivatives, sought to project features from different modalities into a common latent space by maximizing the pairwise cross-modal correlation. These linear models, limited by their non-adaptive kernels, failed to capture the highly non-linear structure inherent in real high-dimensional multimodal data. Deep neural network (DNN) methods introduced non-linear function approximation, spawning DBN and autoencoder-based frameworks such as Multimodal DBN, Bimodal AE, Corr-AE, and CMDN. While these advanced the field, they largely confined themselves to intra-modality structure during feature learning and underutilized the hierarchical and patch-wise fine-grained structure available in modern datasets.
The distinction and improvements over prior work are summarized in (Figure 2).
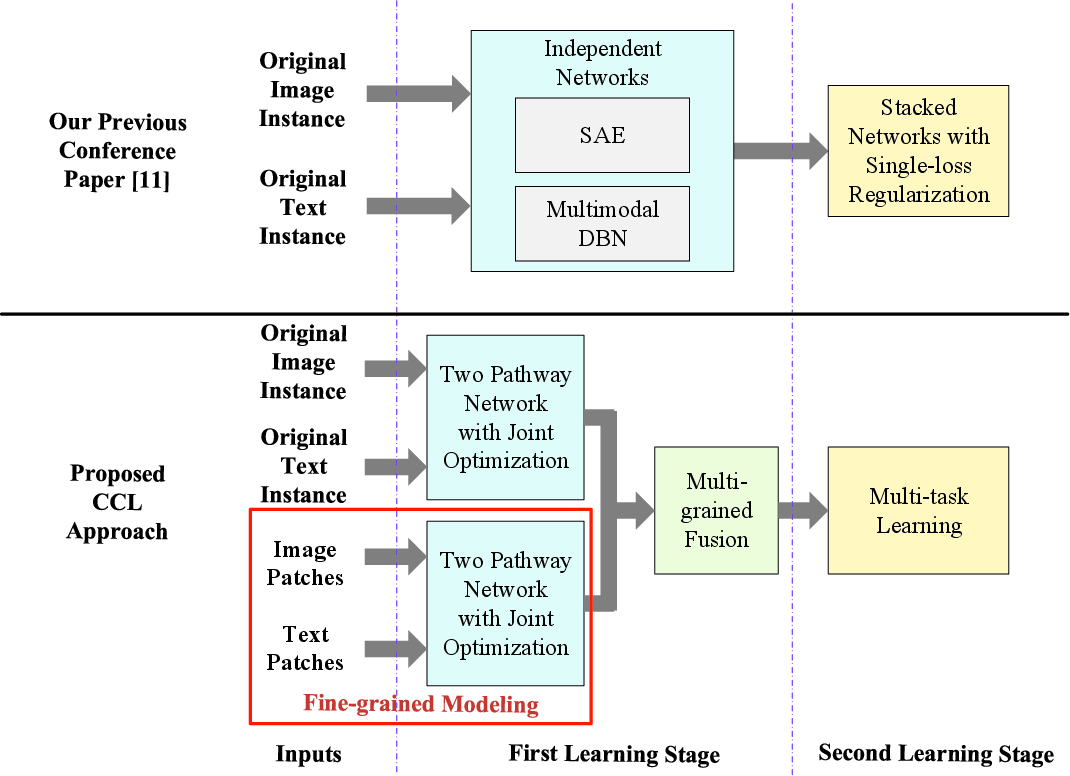
Figure 2: The schematic diagram to show the difference between the proposed CCL approach and CMDN, illustrating multi-grained fusion and unified optimization.
Proposed Method: Hierarchical Multi-grained Cross-modal Correlation Learning
Multi-stage Hierarchical Learning
The CCL model operates in two synergistic learning stages (Figure 3). The first stage generates separate representations per modality by jointly optimizing reconstruction (intra-modality) and pairwise similarity (inter-modality) objectives across both original instances and their subdivisions ("patches"). Fine-grained information extraction is achieved by segmenting both images (via region proposals/selective search) and texts (into sentences, paragraphs, or tags), as visualized in (Figure 4).
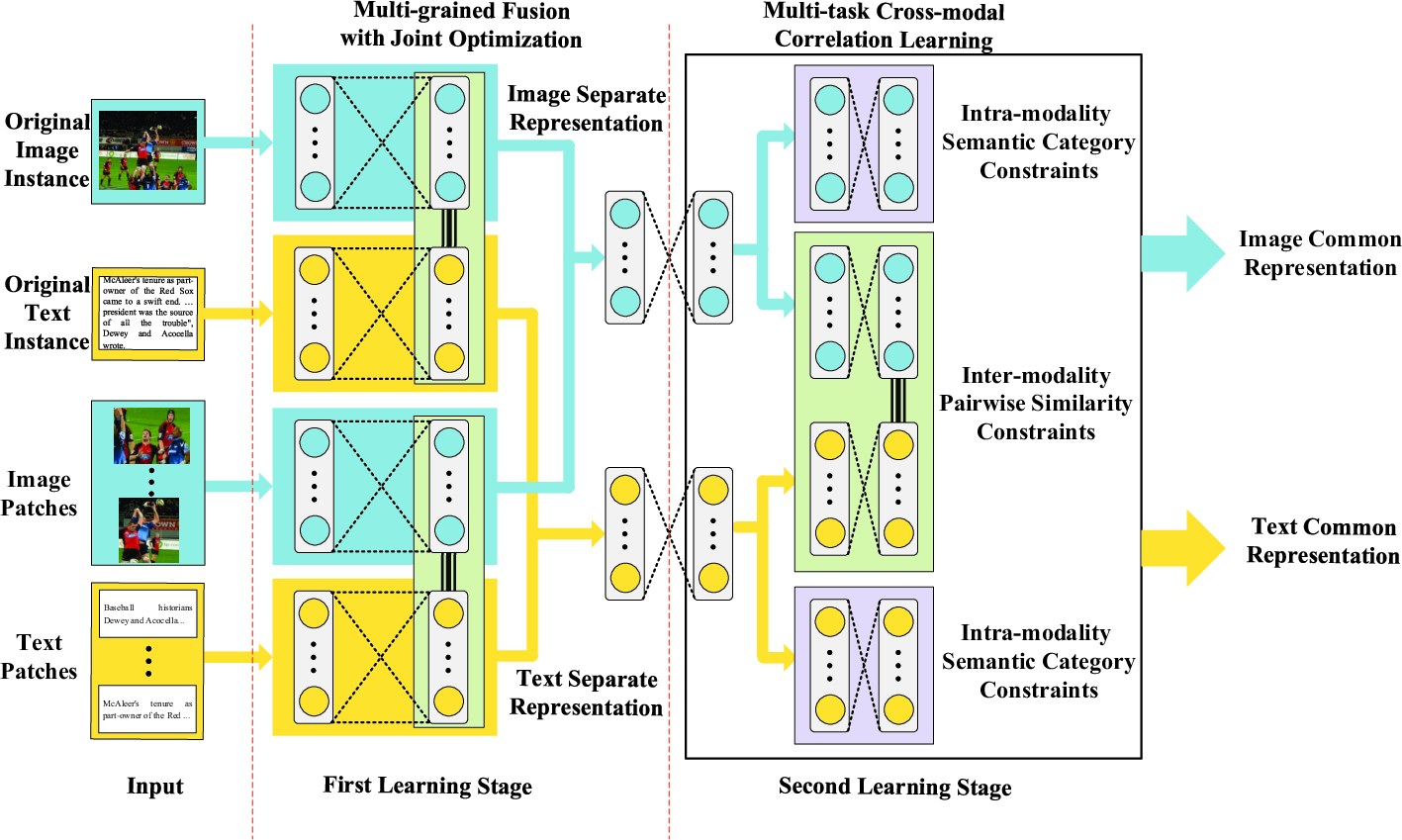
Figure 3: An overview of CCL: Stage 1 simultaneously learns intra- and inter-modality correlations from both original instances and their patches; Stage 2 applies multi-task learning to balance category and pairwise constraints.
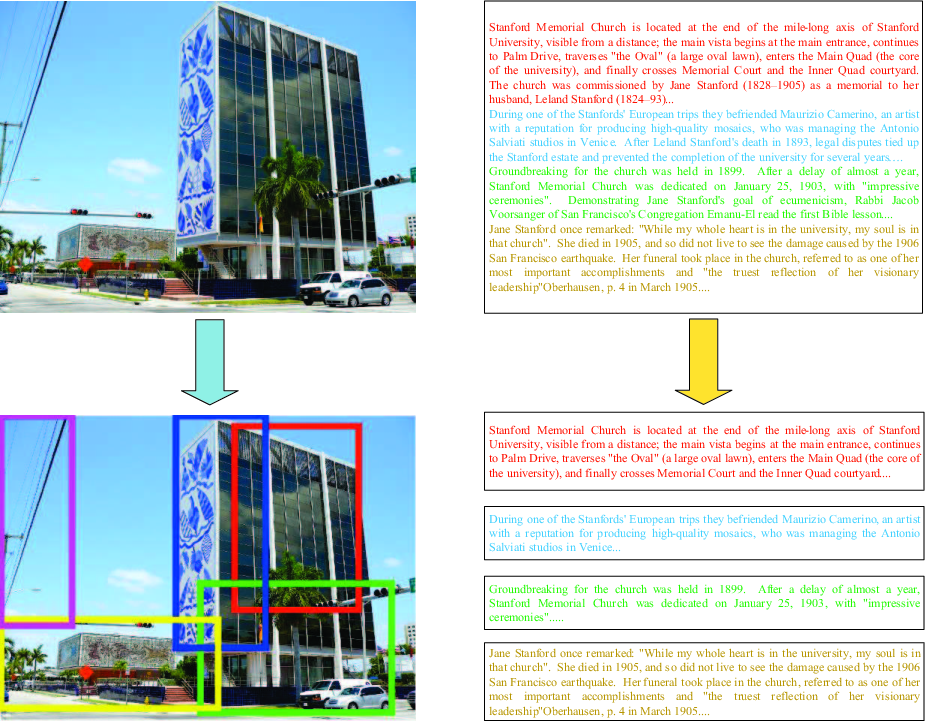
Figure 4: Examples for the generation of fine-grained patches from images and texts.
Separate representations from the original and patch-level features are fused via a joint Restricted Boltzmann Machine (RBM), which aggregates the multi-grained information into cohesive per-modality embeddings prior to cross-modal alignment.
Multi-task Correlation Learning
The second stage employs a multi-task DNN architecture where two main objectives are jointly optimized:
- Intra-modality semantic category classification: Enforced via a softmax cross-entropy loss to enhance class discriminability within the shared embedding space.
- Inter-modality pairwise similarity/dissimilarity: Modeled using a contrastive loss enforcing that paired image-text instances with matching labels are close in embedding space, while non-matching pairs are separated by a specified margin.
This explicit multi-task formulation allows CCL to adaptively balance semantic and correlation constraints and harness richer intrinsic relationships than single-loss approaches.
Experimental Results and Analysis
Experiments were performed on six benchmark datasets, including Wikipedia, NUS-WIDE, Pascal Sentence, Flickr-30K, and MS-COCO, leveraging both hand-crafted and CNN-based image features. CCL was compared against 13 state-of-the-art methods including kernel and DNN-based models. Bi-modal and all-modal retrieval tasks were considered, with mean average precision (MAP) as the main evaluation metric.
Key empirical findings:
- CCL achieves consistent, strong performance gains over all baselines across all datasets. For instance, on the Wikipedia dataset, CCL with CNN features yields an average MAP of 0.481 in bi-modal retrieval, outperforming CMDN (0.458) and outstripping all traditional correlation-based and autoencoder methods.
- The CCL design yields robust improvements in both Image↔Text retrieval directions and for both coarse-grained and fine-grained modalities.
- Precision-recall and precision-scope analyses on NUS-WIDE (Figure 5, Figure 6) further confirm the superiority of CCL on large-scale multimodal collections.

Figure 7: Bi-modal retrieval results on Wikipedia, comparing CCL with CMDN. Green borders denote correct results, red denote failures.
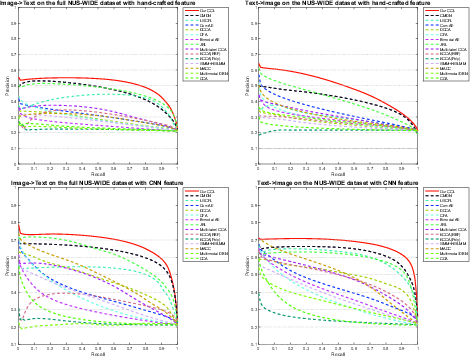
Figure 5: Precision-Recall curves for bi-modal retrieval on NUS-WIDE dataset.
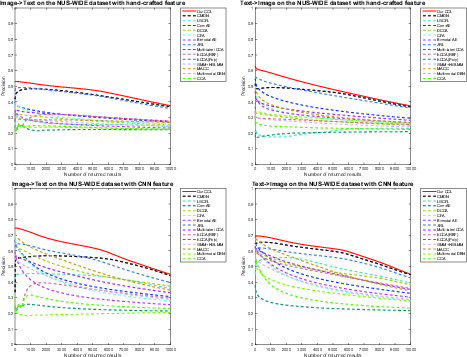
Figure 6: Precision-Scope curves for bi-modal retrieval on NUS-WIDE dataset.
Convergence and parameter sensitivity experiments validate the efficiency and stability of the proposed hierarchical learning scheme (Figure 8, Figure 9). Ablation studies (presented in supplementary tables not depicted here) show that the integration of both coarse- and fine-grained inputs in multi-grained fusion significantly enhances retrieval accuracy, and that simultaneous intra-/inter-modality optimization is essential for top-tier performance.
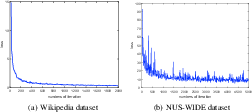
Figure 8: Loss curves demonstrating rapid convergence of CCL on Wikipedia and NUS-WIDE datasets.
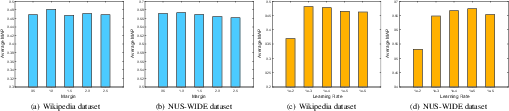
Figure 9: Hyperparameter analysis (learning rate, margin parameter) showing CCL's robustness and optimal ranges.
Implications and Future Directions
The CCL framework's ability to capture complementary intra- and inter-modality structures, along with its explicit fusion of fine-grained cues, addresses critical limitations in prior work and establishes a new state-of-the-art for deep cross-modal retrieval systems. From a practical standpoint, the methodology can directly extend to any application requiring semantically coherent retrieval across heterogeneous media types, such as search engines, digital asset management, and multimedia recommendation systems.
Theoretically, CCL affirms the importance of multi-level granularity and multi-task regularization in multimodal representation learning and suggests that further advances may be realized through continued development of adaptive fusion strategies, improved segmentation algorithms for semantic patch extraction, and integration of unsupervised or semi-supervised objectives for scenarios with limited annotation. Future work includes expansion to unlabeled datasets and refinement of fine-grained region proposal mechanisms.
Conclusion
CCL represents a comprehensive and technically rigorous advance for cross-modal retrieval, leveraging fine-grained, multi-level, and multi-task deep learning strategies to substantially improve both modeling fidelity and empirical performance. Its architectural features offer a blueprint for subsequent research on multi-grained fusion and hierarchical multimodal representation learning.
Reference: "CCL: Cross-modal Correlation Learning with Multi-grained Fusion by Hierarchical Network" (1704.02116)

