- The paper highlights that current VQA models often exploit dataset biases rather than demonstrating robust image reasoning.
- It analyzes multiple datasets, identifying limitations in size and bias that affect overall model performance.
- The study recommends developing larger, unbiased datasets and sophisticated evaluation metrics for improved real-world applications.
Visual Question Answering: Datasets, Algorithms, and Future Challenges
Visual Question Answering (VQA) combines the fields of computer vision and natural language processing by testing an algorithm's ability to answer textual questions about an image. It has emerged as a critical task in AI, demanding robust image understanding, reasoning capabilities, and proficiency with natural language. This paper evaluates the landscape of VQA, scrutinizing the available datasets, algorithms employed, and potential future directions.
VQA requires deeper semantic comprehension than other tasks such as object detection and image captioning. Object detection and semantic segmentation do not explore the contextual understanding necessary for answering VQA questions.



Figure 1: Object detection, semantic segmentation, and image captioning compared to VQA.
The paper emphasizes that whereas tasks like object detection focus on spatial localization, VQA involves reasoning about spatial relationships and activities — aspects that are underrepresented in purely detection or segmentation tasks.
Existing Datasets and Their Limitations
VQA datasets like DAQUAR, COCO-QA, and the VQA Dataset are analyzed. Each dataset varies in terms of size, scope, and question types. Several datasets have inherent biases which can be exploited by algorithms to achieve high performance without truly solving the VQA problem.
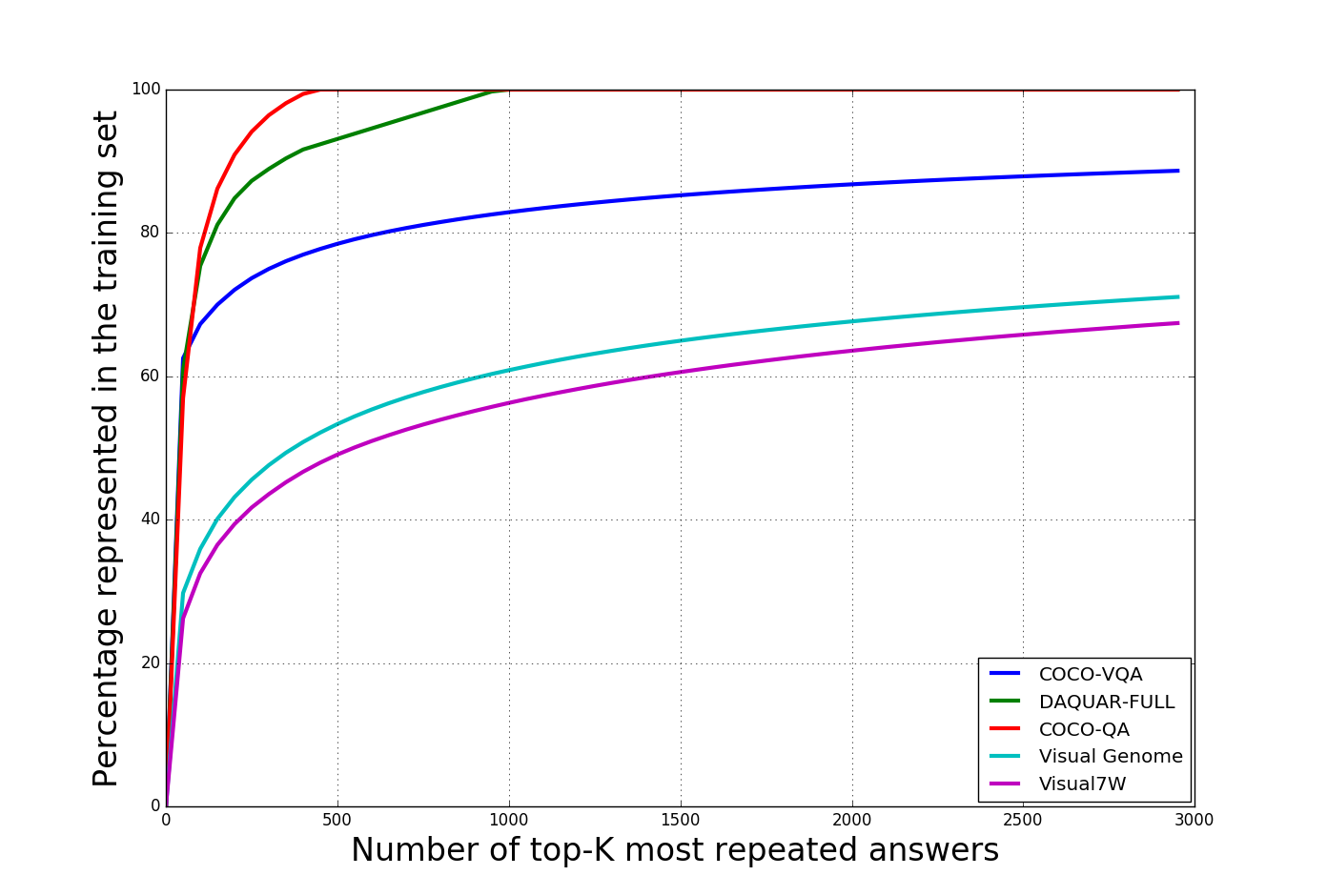
Figure 2: The long-tailed nature of answer distributions highlights variability across VQA datasets.
COCO-VQA: While expansive, it's known for biases which lead to over-reliance on certain answers. Image-blind approaches exploit these biases and perform surprisingly well, undermining the dataset's utility as a comprehensive benchmark.
Evaluation Metrics and Challenges
Evaluation remains a significant challenge in VQA, primarily due to the diversity in potential correct responses. Methods range from standard accuracy to more sophisticated consensus-based approaches like the AccuracyVQA metric which considers agreement among multiple annotators.
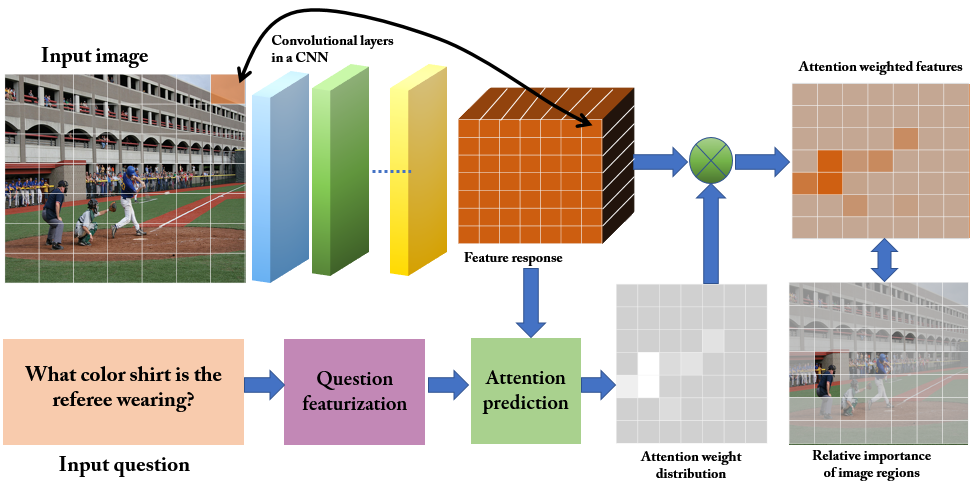
Figure 3: Illustration of using spatial attention in a VQA system leveraging CNN feature maps.
Algorithmic Advances
Recent algorithmic progress in VQA has seen various models leveraging deep learning architectures, especially attention mechanisms to focus on relevant portions of images when answering questions. This includes methods that employ spatial attention to discern features for specific image regions.
Attention-Based Models: These models apply attention to spatially distinct features within an image, attempting to emulate human focus during the questioning process.
Compositional and Modular Networks: Neural Module Networks represent another prominent approach, proposing that VQA can be formulated as a sequence of sub-tasks, each handled by independent neural modules.
Discussion on Bias and Model Evaluation
A winning entry at the 2016 VQA Challenge workshop, the MCB model's success illustrates that models often learn dataset-specific biases rather than generalized image reasoning.
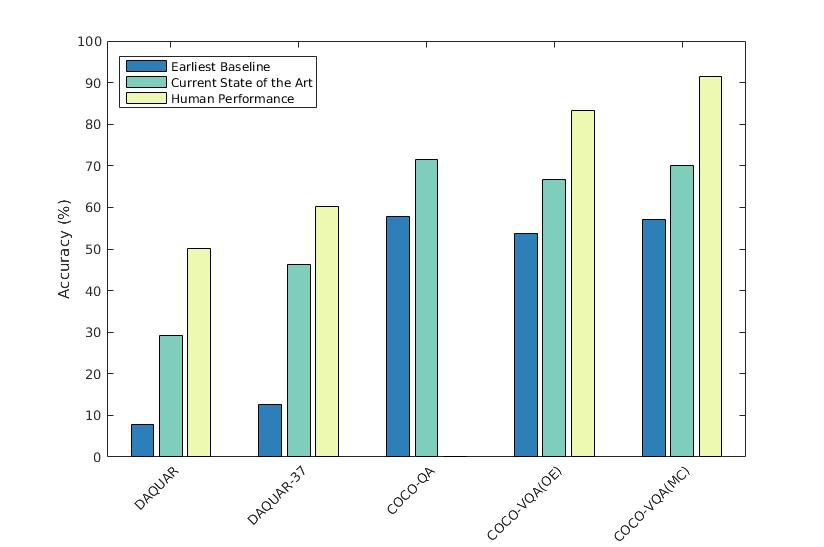
Figure 4: A graph indicating various state-of-the-art results and the gap to human performance.
Bias Impact: Bias in datasets profoundly influences model performance, often leading to inflated accuracy. This reiterates the need for carefully curated datasets to truly benchmark VQA systems.
Recommendations for Future VQA Datasets
The paper suggests the next steps involve crafting larger, more unbiased datasets while advocating for evaluation metrics that measure nuanced understanding rather than raw performance. Addressing dataset bias and developing more sophisticated evaluation frameworks will likely yield algorithms that perform better on real-world VQA challenges.
Conclusion: The paper establishes that while progress in VQA is notable, substantial gaps remain in achieving models that generalize robustly to varied and unforeseen visual questions. Progress depends on developing better datasets and evaluation metrics that reflect the true complexity of VQA beyond dataset-specific biases.
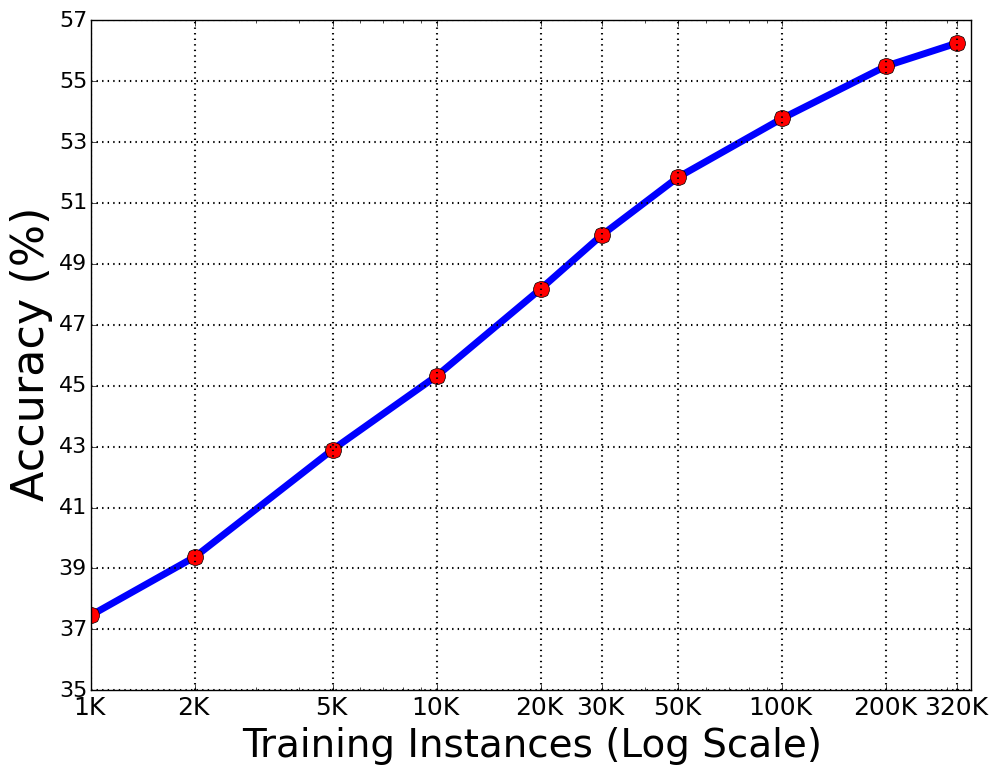
Figure 5: A depiction showing how test accuracy on COCO-VQA correlates with the volume of training data, underscoring data dependency.

