- The paper introduces a novel asymmetric design that integrates RGB imagery with DSM data to overcome architectural redundancy and modality misalignment.
- It employs a dual encoder and fusion modules to achieve state-of-the-art segmentation performance on the ISPRS Vaihingen and Potsdam datasets.
- Results demonstrate improved accuracy for challenging classes with 64% fewer FLOPs and 30% reduced memory consumption compared to prior methods.
AMMNet: An Asymmetric Multi-Modal Network for Remote Sensing Semantic Segmentation
The paper "AMMNet: An Asymmetric Multi-Modal Network for Remote Sensing Semantic Segmentation" (2507.16158) addresses the challenges of semantic segmentation in remote sensing by introducing a novel asymmetric architecture, AMMNet, designed to efficiently integrate RGB imagery and Digital Surface Model (DSM) data. The key contribution lies in tackling architectural redundancy and modality misalignment, which are common limitations in multi-modal approaches. AMMNet employs three key modules: the Asymmetric Dual Encoder (ADE), the Asymmetric Prior Fuser (APF), and the Distribution Alignment (DA) module, each tailored to leverage the unique characteristics of RGB-DSM input pairs. The paper demonstrates state-of-the-art segmentation accuracy on the ISPRS Vaihingen and Potsdam datasets while reducing computational and memory requirements, thus validating the effectiveness and robustness of the proposed asymmetric design for multi-modal semantic segmentation in complex urban environments.
Addressing Limitations in Multi-Modal Semantic Segmentation
The paper begins by highlighting the significance of remote sensing semantic segmentation in geoscientific research and its applications in environmental monitoring, resource management, and disaster assessment. The limitations of single-modal input, particularly RGB imagery, in handling complex remote sensing conditions such as illumination changes and occlusions, are discussed. Multi-modal learning, specifically the integration of RGB imagery and DSM, is presented as a promising approach to overcome these limitations. RGB provides contextual information while DSM offers elevation-based structural information.

Figure 1: Visualization of the complementary characteristics between RGB and DSM modalities.
The authors identify two main challenges in multi-modal semantic segmentation: architectural redundancy and modality misalignment. Architectural redundancy arises from the inclusion of extra encoder and fusion components, leading to increased computational complexity. Modality misalignment stems from the inherent heterogeneity between modalities, which, if not properly addressed, can degrade segmentation performance. The paper posits that AMMNet effectively addresses these challenges through its novel asymmetric architecture.
The Asymmetric Multi-Modal Network (AMMNet) Architecture
The AMMNet architecture is composed of three key modules: the Asymmetric Dual Encoder (ADE), the Asymmetric Prior Fuser (APF), and the Distribution Alignment (DA) module, which are illustrated in (Figure 2).
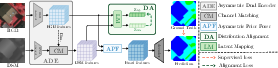
Figure 2: The overall architecture of AMMNet.
The ADE module (Figure 3) is designed to reduce architectural redundancy by employing modality-specific encoders. A deeper encoder is used for RGB imagery to capture rich contextual information, while a lightweight encoder is used for DSM to extract sparse structural features. This design choice is based on the observation that RGB images provide rich contextual information, necessitating a deep encoder, while DSM data primarily encodes sparse structural cues, for which a shallow encoder is sufficient. The Channel Matching (CM) module aligns the DSM features dimension with those of the RGB features to ensure consistency for downstream integration.

Figure 3: The overview of Asymmetric Dual encoder (ADE).
To address modality misalignment, the APF module (Figure 4) integrates RGB and DSM features through a modality-aware prior matrix, generating structure-aware contextual representation. The Distribution Alignment (DA) module further minimizes the distributional divergence between the DSM and RGB features, enhancing cross-modal compatibility.
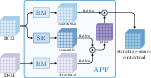
Figure 4: The overview of Asymmetric Prior Fuser (APF).
The APF module constructs a modality-aware prior matrix to capture complementary information from both modalities, facilitating more effective feature integration. This prior is subsequently incorporated into the RGB contextual features to generate structure-aware contextual features. The Distribution Alignment (DA) module projects features into a latent space via Latent Mapping (LM) to capture their underlying distributions. By minimizing the divergence between the latent variables of RGB and DSM, the DA module ensures cross-modal compatibility.
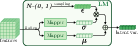
Figure 5: The overview of the Latent Mapping (LM) module.
Experimental Results and Analysis
The authors conduct extensive experiments on the ISPRS Vaihingen and Potsdam datasets to evaluate the performance of AMMNet. The results demonstrate that AMMNet achieves state-of-the-art segmentation accuracy among multi-modal networks while reducing computational and memory requirements.
On the Vaihingen dataset, AMMNet achieves an mOA of 93.52\%, mF1 of 93.27\%, and mIoU of 87.56%. Notably, AMMNet achieves substantial improvements of 4.61\% and 5.34\% in the "Tree" and "Low Vegetation" categories, respectively, compared to the previous state-of-the-art network, FTransUNet, highlighting its effectiveness in handling structurally complex and contextually ambiguous classes.
On the Potsdam dataset, AMMNet achieves an mOA of 93.47\%, mF1 of 93.50\%, and mIoU of 88.02%. The paper notes that the "Tree" category is relatively sparse and more challenging to identify due to the limited number of training samples in the Potsdam dataset. Nevertheless, AMMNet demonstrates superior recognition capability, achieving a 9.20\% improvement compared with the previous state-of-the-art network, which highlights its effectiveness in detecting sparse categories by leveraging structural cues from DSM.
Qualitative results on both datasets demonstrate AMMNet's ability to accurately segment occluded and contextually ambiguous classes (Figures 6 and 7). Efficiency analysis reveals that AMMNet achieves the highest segmentation accuracy while requiring only 64% of the FLOPs and 30% of the memory consumption compared to the second-best method, FTransUNet. Ablation studies validate the individual contributions and interdependencies of the core components in AMMNet, as well as the effectiveness of the asymmetric design in ADE and the strength sensitivity of the DA module's alignment loss weight.

Figure 6: Qualitative comparison of segmentation results on the ISPRS Vaihingen test set.

Figure 7: Qualitative comparison of segmentation result on the ISPRS Potsdam test set.
Conclusion
The paper "AMMNet: An Asymmetric Multi-Modal Network for Remote Sensing Semantic Segmentation" (2507.16158) presents a well-designed and thoroughly evaluated approach to multi-modal semantic segmentation in remote sensing. The proposed AMMNet architecture effectively addresses the challenges of architectural redundancy and modality misalignment through its novel asymmetric design. The extensive experimental results on the ISPRS Vaihingen and Potsdam datasets demonstrate the superior performance and efficiency of AMMNet compared to existing state-of-the-art methods. The modular design of AMMNet, comprising the ADE, APF, and DA modules, facilitates a nuanced integration of RGB and DSM data, leading to enhanced segmentation accuracy and reduced computational overhead. This work contributes significantly to the field of remote sensing by providing an effective and efficient solution for semantic segmentation in complex urban environments.

