- The paper presents a novel masked autoregressive image generation method using a Deep Compression Hybrid Tokenizer that achieves a 32× spatial compression ratio.
- It employs a three-stage adaptation training strategy that leverages both discrete and continuous token paths for robust and high-fidelity image reconstruction.
- Experimental results demonstrate 1.5-7.9× higher throughput and 2.0-3.5× lower latency, validating its efficiency and superior performance on benchmark datasets.
Efficient Masked Autoregressive Image Generation with DC-AR
DC-AR represents a significant advancement in masked autoregressive (AR) image generation, specifically tailored for text-to-image synthesis. In contrast to diffusion models, which have dominated this sphere due to their continuous nature and computational efficiency, DC-AR leverages a novel approach that emphasizes both efficiency and high-quality image reconstruction through a hybrid tokenization strategy.
Introduction to DC-AR
The foundation of DC-AR lies in the innovative Deep Compression Hybrid Tokenizer (DC-HT), which provides a 32× spatial compression ratio. DC-HT improves upon existing masked AR models by introducing a tokenization process that maintains high reconstruction fidelity and cross-resolution adaptability. By implementing DC-HT with a three-stage adaptation training strategy, DC-AR overcomes prevalent limitations found in previous models concerning throughput and latency.
In comparison to leading autoregressive and diffusion models, DC-AR achieves 1.5-7.9× higher throughput and 2.0-3.5× lower latency, setting new benchmarks in computational efficiency. This is important for practical applications where resource constraints are a critical factor.
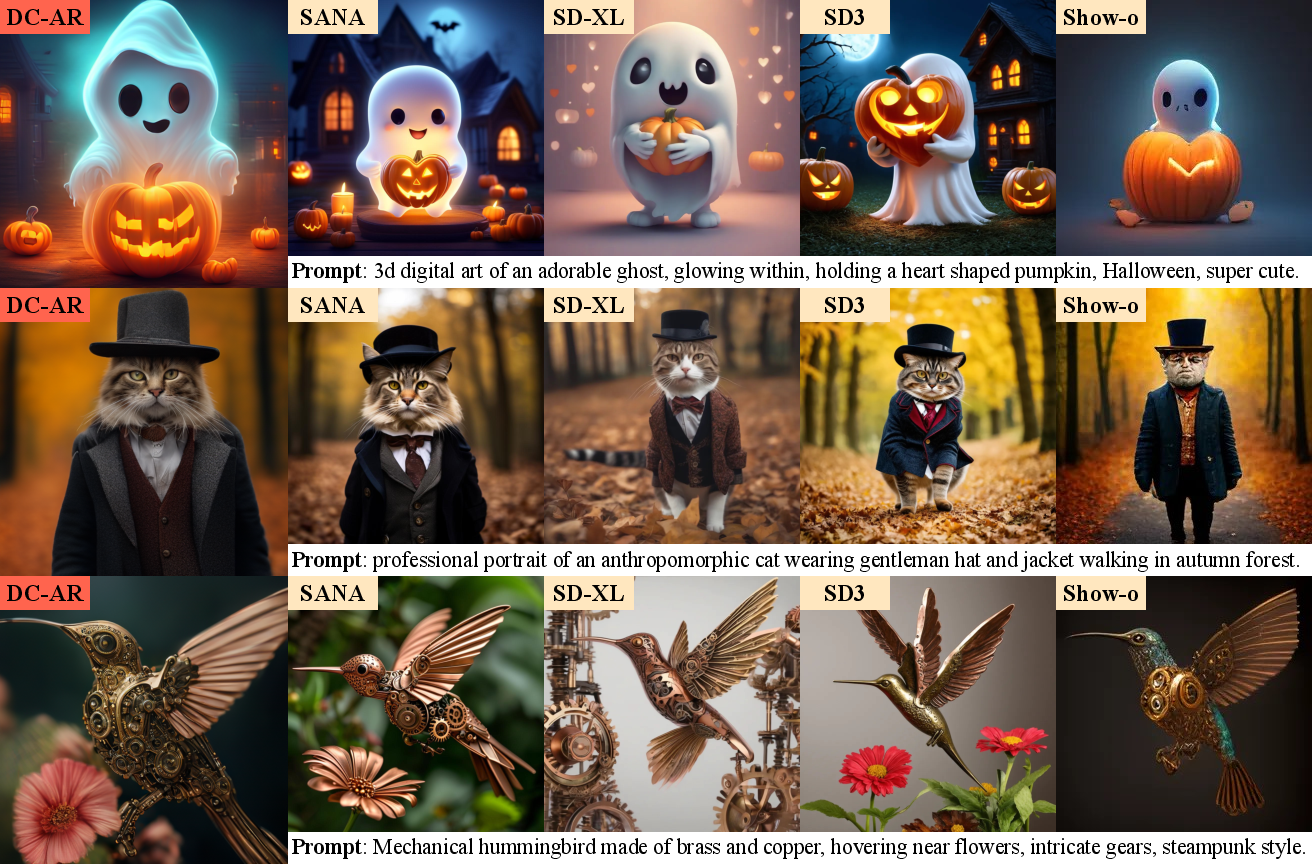
Figure 1: Qualitative Comparison of Text-to-Image Generation Results Between DC-AR and Other Generative Models.
Methodology
Deep Compression Hybrid Tokenizer
DC-HT is pivotal to DC-AR's performance. It not only reduces the spatial dimensions effectively (32× compression) but also supports a hybrid tokenization framework. This framework accommodates both discrete and continuous token paths, employed during different stages of image reconstruction. The discrete path benefits the generation of broad structural elements, while the continuous path refines these elements, ensuring high fidelity.
The three-stage adaptation strategy enhances the training of DC-HT. Initially, the continuous warm-up stage sets an appropriate baseline. This is followed by discrete learning, focusing on stable latent space comprehension. Finally, an alternate fine-tuning stage ensures that the decoder can effectively interpret both discrete and continuous inputs.
Hybrid Masked Autoregressive Model
DC-AR combines the strengths of DC-HT with a novel masked autoregressive generation process. The training involves both mask-prediction objectives and diffusion loss refinement, using discrete tokens for the structural layout and residual tokens for intricate detailing. At inference, DC-AR utilizes a progressive unmasking approach, unique for its efficiency—delivering optimal results with merely 12 steps, a marked efficiency improvement over purely continuous token-based models.
Experimental Evaluation
In experiments on various benchmarks, DC-AR demonstrates state-of-the-art quality with a generation FID (gFID) of 5.49 on MJHQ-30K, and a competitive score of 0.69 on GenEval for prompt alignment. These advancements validate the effectiveness of the proposed hybrid tokenization and generation framework.
Advantage Over Other Models
The unique design of DC-AR, combining discrete and continuous tokens, sets it apart from other frameworks. It allows for maintaining high image quality with significantly reduced latency, crucial for deployment in real-world scenarios where speed is parallel to quality. This efficiency does not compromise the model's ability to generalize across image resolutions, an attribute critical for scalable and adaptable AI applications.
Conclusion
DC-AR illustrates a robust advancement in autoregressive image generation by introducing high-efficiency tokenization and a hybrid autoregressive framework that leverages discrete and continuous token strengths. The result is a model that combines computational efficiency with high-quality output, offering significant practical benefits and setting the stage for future developments in efficient text-to-image synthesis frameworks. This research opens pathways for further innovations that could integrate or enhance similar hybrid strategies in related domains.

