- The paper introduces a hybrid particle-grid framework for accurately learning deformable object dynamics from RGB-D videos.
- It leverages a neural velocity field and Grid Velocity Editing to optimize predictions under sparse visual conditions.
- Results demonstrate improved metrics such as mean distance error and Chamfer Distance compared to traditional methods.
Particle-Grid Neural Dynamics for Learning Deformable Object Models from RGB-D Videos
This paper discusses a novel Particle-Grid Neural Dynamics (PGND) framework developed to model the dynamics of deformable objects from RGB-D videos. By leveraging a hybrid representation combining particle and grid techniques, the framework addresses the challenge of learning deformable object behavior with limited visual information.
Framework Overview
The proposed Particle-Grid Neural Dynamics Framework utilizes a hybrid representation to capture deformable object dynamics. The framework combines particle-based models with spatial grids for accurate prediction of object motion. Particles represent object shapes and global motion, while spatial grids maintain spatial continuity and computational efficiency. The dynamics model predicts dense particle movements using neural networks optimized from real-world interactions captured in RGB-D videos.
In practice, this framework excels in modeling complex interactions across diverse objects, including ropes, cloths, plush toys, boxes, and bread, each presenting unique challenges in dynamics prediction.
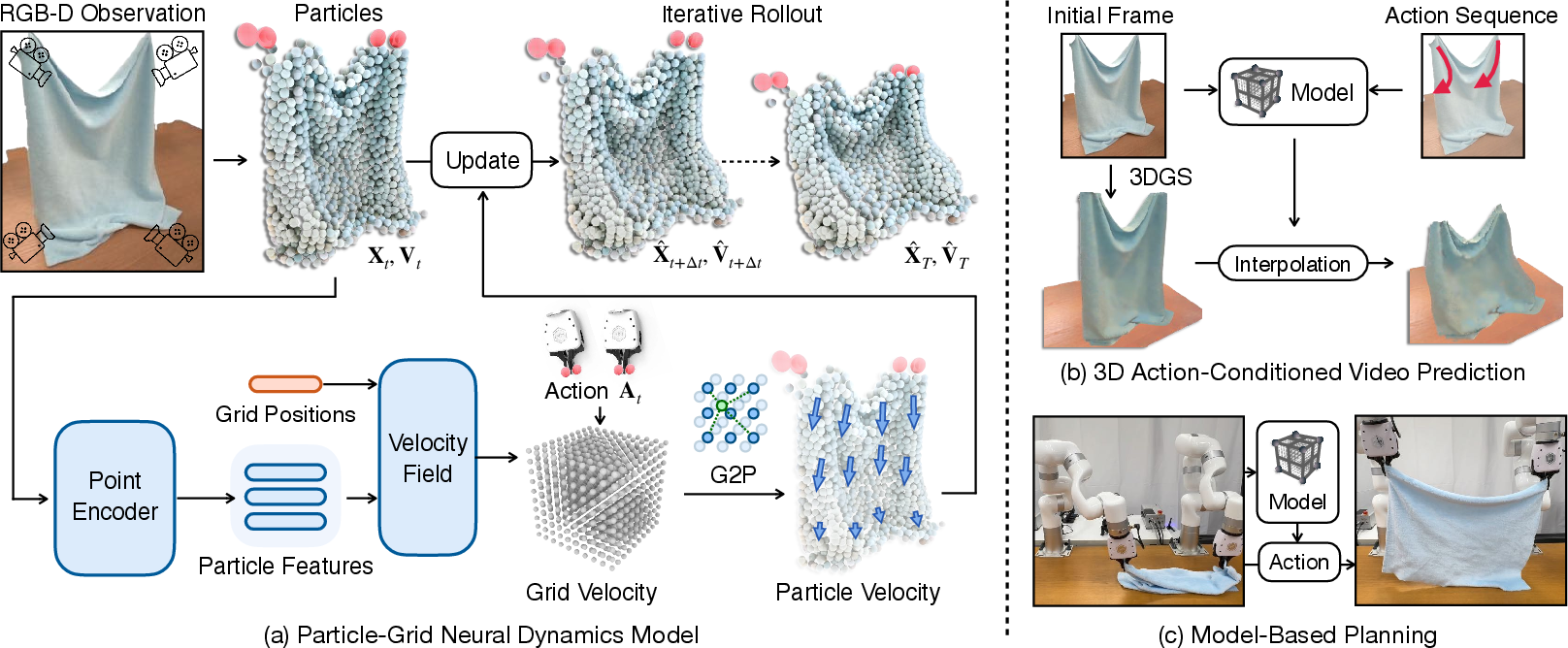
Figure 1: Overview of proposed framework: Particle-Grid Neural Dynamics.
Dynamics Function and Neural Architecture
State and Action Representation
The object's state is represented by particles Xt and velocities Vt. Actions (At) describe external robot effects, capturing the interaction with the object.
Particle-Grid Dynamics Function
The dynamics function f predicts future state evolution considering both intrinsic object dynamics and external manipulations:
V^t+Δt=f(Xt−hΔt:t,Vt−hΔt:t,At)
This is achieved through a neural architecture that includes:
- Point Encoder: Extracts features from particle positions and velocities.
- Neural Velocity Field: Predicts velocity at grid points using an MLP, enabling spatial field prediction crucial for robust dynamics modeling.
- Grid Velocity Editing (GVE): Utilizes grid representation to handle collisions and apply constraints dynamically.
Training and Optimization
The framework is trained using dense 3D particle tracking, derived from foundational vision models, with a focus on leveraging RGB-D video data, ensuring robustness to partial representations and generalizability across unseen instances.
Experimentation and Evaluation
Dynamics Prediction Accuracy
Quantitative evaluations demonstrate superior performance of the PGND framework compared to conventional approaches like Material Point Method (MPM) and Graph-Based Neural Dynamics (GBND). This is reflected through lower error metrics for various object categories:
- Mean Distance Error (MDE)
- Chamfer Distance (CD)
- Earth Mover's Distance (EMD)
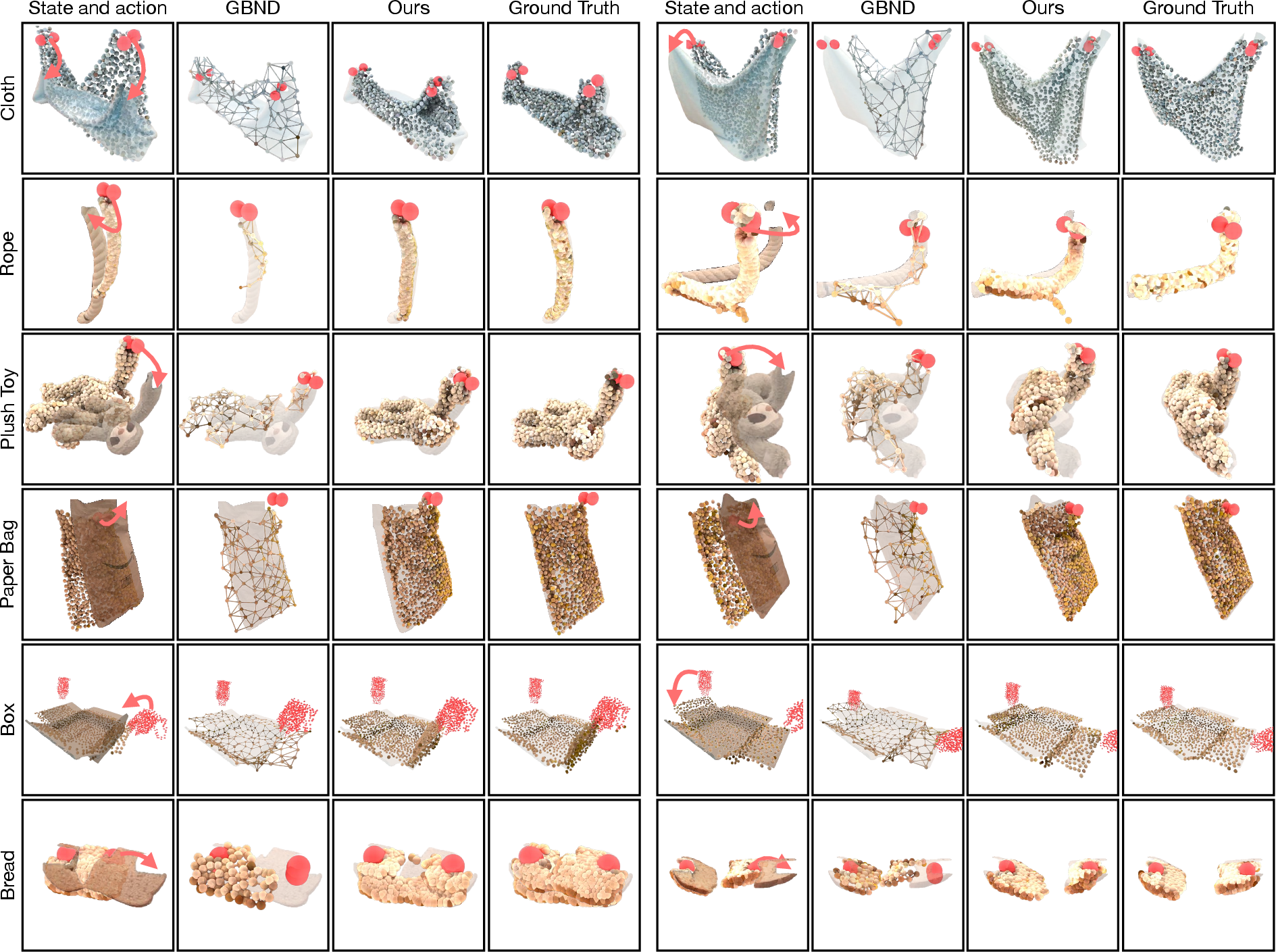
Figure 2: Qualitative Comparisons on Dynamics Prediction.
Robustness to Sparse Views
The model's robustness was assessed under partial view conditions, highlighting its performance with reduced camera view inputs. The PGND framework maintains lower error rates and shows resilience to decreased visual information.
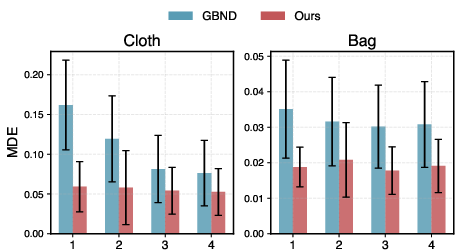
Figure 3: Quantitative Comparisons on Prediction under Partial Views.
Generalization and Planning
The framework's ability to generalize across categories and its integration with Model Predictive Control (MPC) for object manipulation tasks further establishes its effectiveness. Experiments included cloth lifting, box closing, and plush toy relocating, where PGND consistently achieved lower errors and higher task success rates.
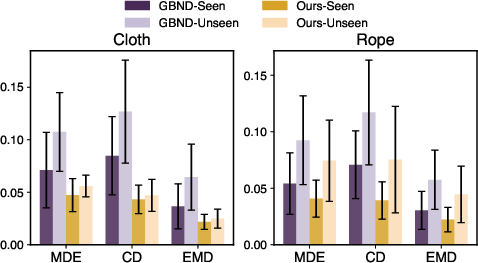
Figure 4: Quantitative Comparisons on Planning.
Conclusion
This paper presents a novel Particle-Grid Neural Dynamics framework that effectively models the dynamics of deformable objects from RGB-D videos, addressing critical challenges in occlusion and partial observation. Through a hybrid particle-grid representation, it provides robust and accurate predictions across diverse deformable objects and integrates seamlessly with planning applications in robotics.
Future Directions
Future work could involve enhancing the modeling of disappearing particles, explicit modeling of physical properties for better interpretability, and expanding applicability to more complex physical systems, potentially refining applications in various AI-driven robotic challenges.