- The paper shows that scaling deep RL networks without interventions leads to collapse due to degraded gradient flow under non-stationarity.
- The analysis reveals that multi-skip residual architecture enables direct gradient propagation, while the Kron optimizer adapts to changing curvature.
- Combined, these interventions yield monotonic performance improvements, achieving up to 83% human-normalized gains on Atari benchmarks.
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning
Introduction
This paper analyzes the failure modes induced by network scaling in deep reinforcement learning (RL), focusing on the interplay between non-stationarity and instabilities in gradient propagation. The central finding is that as RL networks are scaled in depth and width, gradient signals systematically degrade, resulting in a collapse in learning performance—a pathology observed across algorithms and domains. The authors conduct controlled empirical analyses to attribute this performance breakdown to the interaction between bootstrapped non-stationarity intrinsic to RL and architectural choices that exacerbate gradient vanishing (or explosion), especially in thick, deep networks. Motivated by this diagnosis, the paper introduces a set of direct, actionable interventions—multi-skip residual architectures and Kronecker-factored optimizers—that substantially stabilize gradient flow. These methods yield robust, monotonic performance gains as networks scale, in contrast with standard baselines where scaling harms both expressivity and learning.
Diagnosis: Non-Stationarity and Gradient Pathologies
The investigation begins by contrasting supervised learning (SL), where data and targets are stationary, with RL's non-stationary objectives arising from bootstrapped targets and constantly evolving policies. The authors show that, under stationary SL, increasing network size maintains high performance with stable, healthy gradient flow. However, injecting non-stationarity (e.g., periodic label reshuffling in SL, or standard RL objectives) induces severe gradient decay as a function of depth and width, to the point where only the shallowest networks retain non-negligible gradients in deeper layers. These phenomena are rigorously quantified with metrics including episode returns, layerwise gradient norms, neuron utilization ("dormant" neurons fraction), SRank (effective representation rank), and Hessian trace as a proxy for loss curvature.
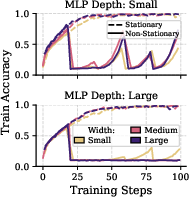
Figure 1: Training dynamics under stationary and non-stationary supervised learning. In non-stationary settings, deep models collapse in both accuracy and gradient flow, highlighting poor adaptability.
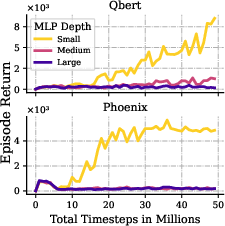
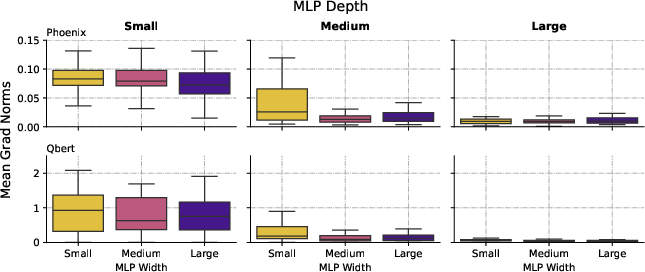
Figure 2: In Atari RL tasks, shallow networks achieve high returns and healthy gradient norms, while deeper networks' performance and gradients collapse.
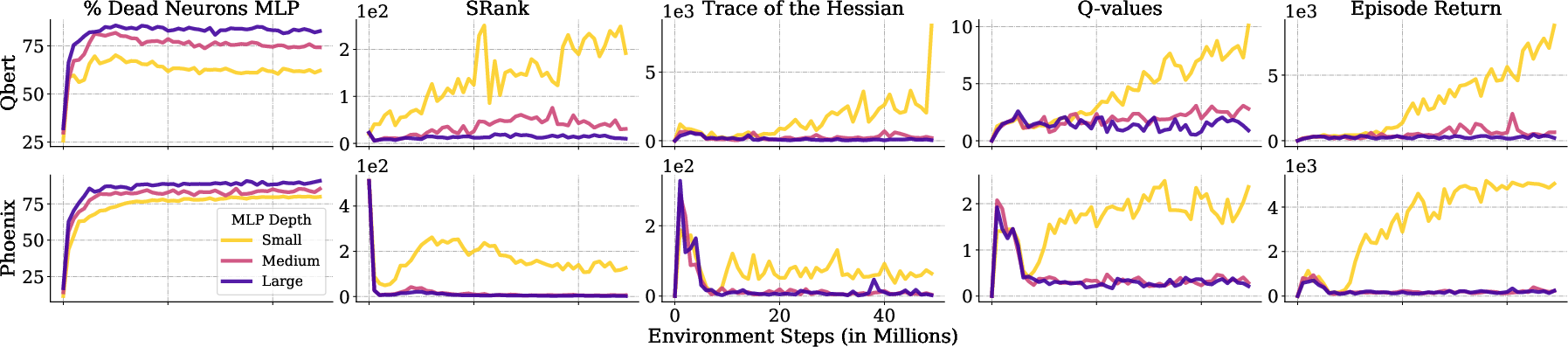
Figure 3: Scaling depth increases inactive neurons, degenerates SRank, and flattens loss curvature, all pointing to loss of expressivity and plasticity.
The empirical results make a bold claim: in deep RL, increasing capacity with conventional architectures does not yield the scaling benefits observed in SL or generative modeling domains, but instead substantially impairs optimization, plasticity, and representational richness.
Proposed Interventions: Stabilizing Gradient Flow
To address the identified bottlenecks, two complementary classes of interventions are proposed:
- Multi-Skip Residual Architecture: Standard residual connections (as in ResNets) connect only adjacent or near-adjacent layers. The multi-skip residual scheme broadcasts encoder features directly to all subsequent MLP layers, creating direct gradient highways from the output to every depth. This ensures that, regardless of non-stationarity or initialization, all depths have unfettered access to the encoder representation and propagate gradients effectively.
- Kronecker-Factored Second-Order Optimizer (Kron): First-order optimizers (SGD, Adam, RMSProp, RAdam) are agnostic to loss geometry and are unstable under shifting, misaligned curvature typical in RL. Kron (a K-FAC variant) leverages low-rank approximations to the Fisher information matrix to precondition updates, adapting to evolving curvature and preserving gradient magnitude and direction. Empirical analysis demonstrates that Kron prevents performance collapse under scaling, even for standard MLPs that otherwise degenerate with Adam-like methods.
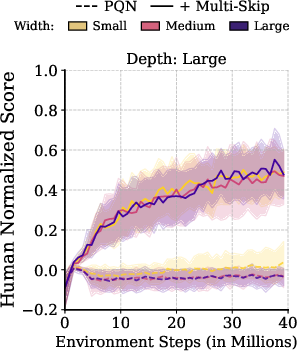
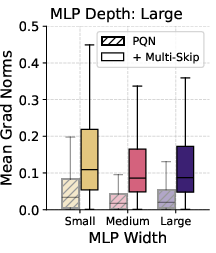
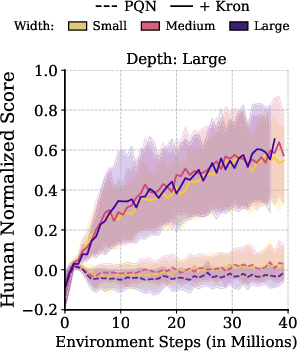
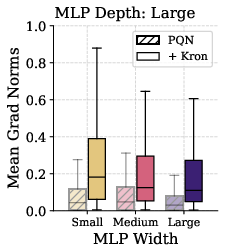
Figure 4: Multi-skip architectures (left) and Kron optimizer (right) both enable stable learning and preserve gradient flow at greater depths, in sharp contrast to rapidly collapsing baselines.
These interventions are constructed to be algorithm-agnostic and easily composable with existing RL codebases.
Combined Effect and Generalization Across Algorithms
Composing the proposed interventions results in robust scaling on the complete Atari Learning Environment (ALE) benchmark. The combined approach dominates the unaugmented baseline in 90% of environments, with a median human-normalized score (HNS) improvement of 83.27%.
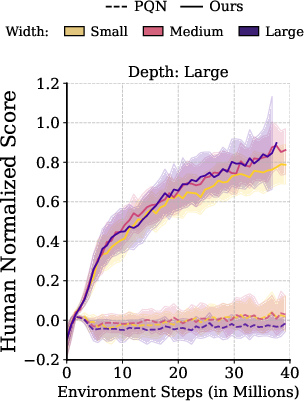
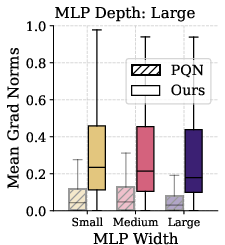
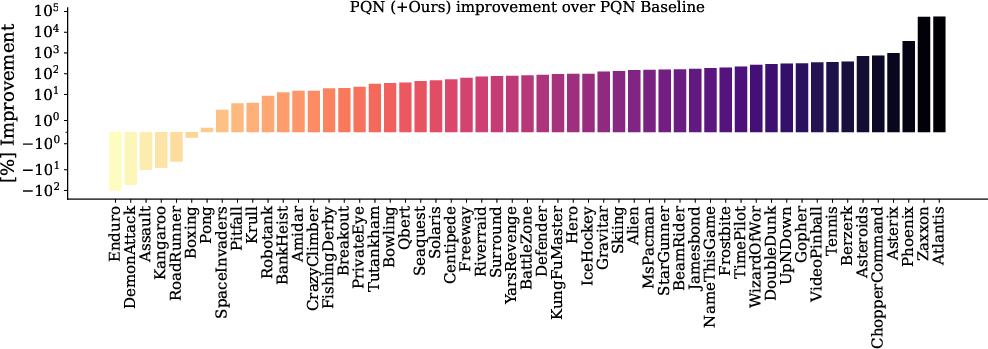
Figure 5: Combined gradient-stabilizing interventions enable monotonic scaling on Atari-10 and the full ALE benchmark, outperforming strong baselines.
The methods are validated beyond value-based RL: in Proximal Policy Optimization (PPO), the same interventions yield a +31.40% median performance improvement (top of human-normalization) and close gaps across depth and width, including in high-parallelism continuous control settings with Isaac Gym.
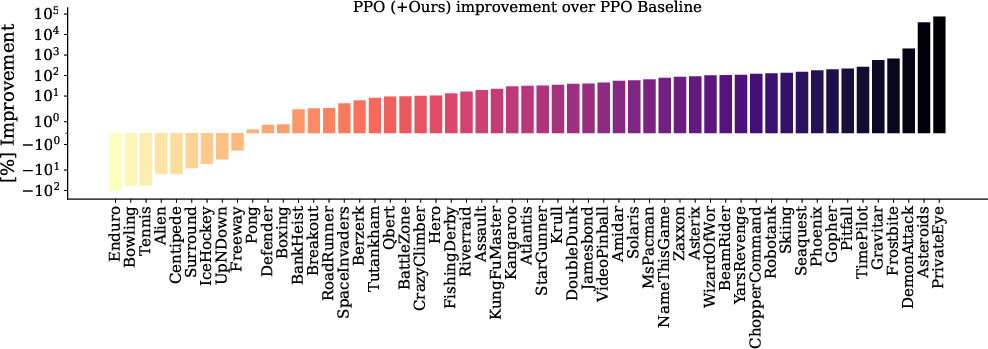
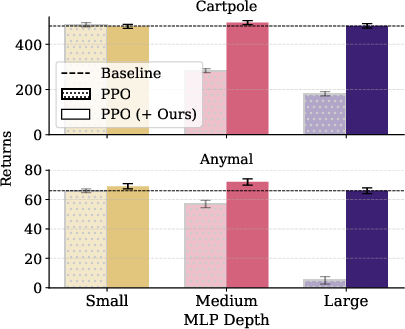
Figure 6: PPO with multi-skip + Kron matches or outperforms the baseline in 83.6% of games; only augmented PPO maintains stable scaling on challenging robotics domains.
Furthermore, using a more expressive encoder such as Impala CNN synergizes with the interventions, showing effective scaling in PPO and PQN, and verifying that the benefits are not tied to a fixed backbone.
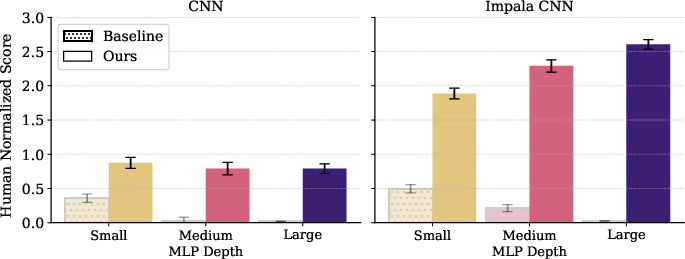
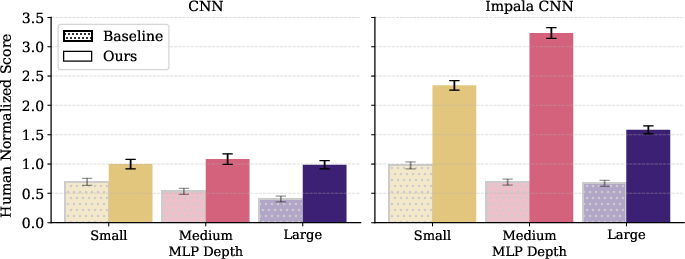
Figure 7: Impala CNN encoder enhances scaling with gradient interventions in both value- and policy-based RL agents.
Ablations confirm that alternative normalization, regularization, or adaptive optimizers are insufficient alone; the specific combination of multi-skip (for representational robustness and gradient highways) and Kron (for curvature-aware updates) is essential for reliable large-scale learning.
Extension to Offline RL and Other Domains
Gradient-stabilizing interventions also generalize to offline RL settings, where non-stationarity is attenuated. When augmenting a diverse suite of offline Q-learning algorithms (including SHARSA/DSHARSA) on hard tasks, especially those with sparse rewards, the methods improve credit assignment and policy quality without explicit horizon reduction, addressing a distinct axis of scalability.
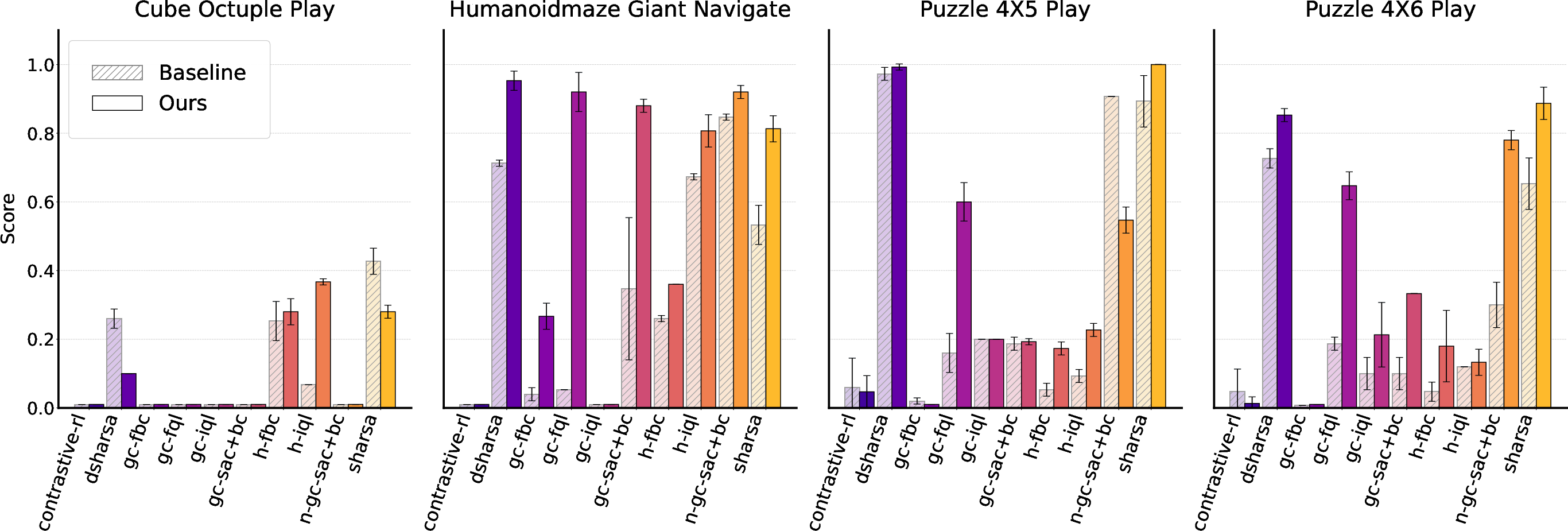
Figure 8: Gradient interventions enable consistent scaling and improvement even in offline RL algorithms.
Extensive experiments with Simba architectures (SAC/DDPG on DeepMind Control Suite) further confirm that traditional Adam-based optimization quickly collapses with increasing parameters, whereas Kron preserves stability and yields monotonically increasing returns.
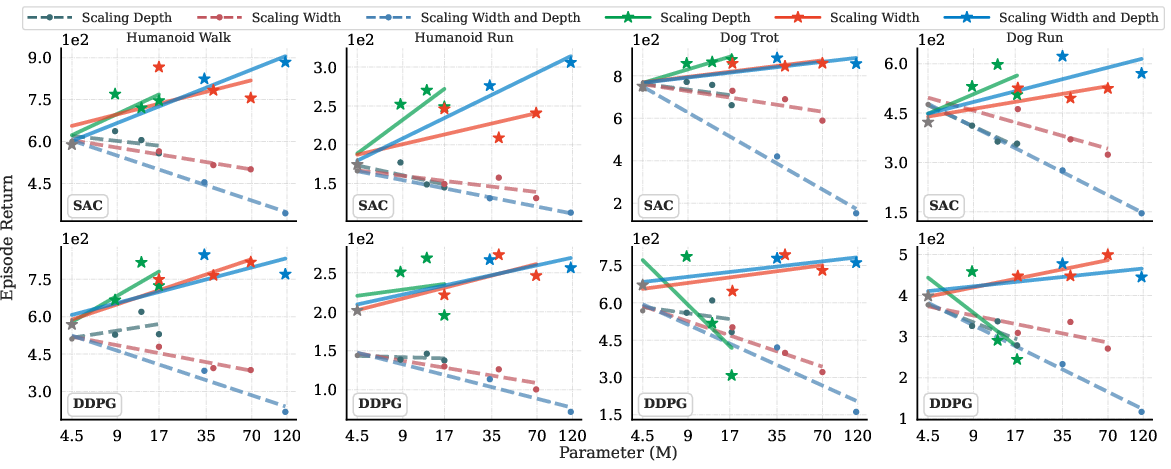
Figure 9: SAC and DDPG scale only with Kron; AdamW leads to severe performance degradation at scale.
Implications and Future Directions
The results establish stable gradient flow as a non-negotiable precondition for scaling deep RL architectures. This work provides a systematic framework for diagnosing and addressing capacity underutilization, representation collapse, and learning instability stemming from depth and width expansion. The direct practical implication is that, absent architectural changes and suitable optimization, naive parameter scaling in RL is not only inefficient but actively destructive. Theoretically, these findings challenge the assumption that SL-inspired scaling trends transfer to RL, and encourage the use of diagnostic curvature and gradient metrics as primary guides for architecture/optimizer design.
Avenues for future research include pushing the limits of model scale with more hardware and exploring additional second-order approximations, seeking efficient surrogates with lower overhead, and investigating further the intersection of encoding architectures and gradient stabilization. There is also a potential to extend these ideas to more general online, multi-agent, and hierarchical RL domains.
Conclusion
This paper identifies compounded gradient pathologies as the chief obstacle to scaling deep reinforcement learning models. By dissecting the mechanistic failure under non-stationarity and presenting multi-skip and curvature-aware optimizer interventions, it delivers robust, generalizable methods with strong empirical performance across benchmarks, algorithms, and tasks. Stable gradient flow emerges as the gating constraint for unlocking large-capacity, high-performing RL systems.
Reference: "Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning" (2506.15544)

