- The paper introduces ALST to overcome GPU memory limits through Ulysses Sequence Parallelism, enabling efficient processing of multi-million token sequences.
- It employs Sequence Tiling and Tiled MLP techniques to reduce memory usage, achieving up to a 58% increase in sequence length capacity in certain setups.
- Integration with Hugging Face Transformers and PyTorch optimizations allows training of Llama-8B models up to 15M tokens, delivering significant performance improvements.
Arctic Long Sequence Training: Scalable and Efficient Training for Multi-Million Token Sequences
The paper "Arctic Long Sequence Training: Scalable And Efficient Training For Multi-Million Token Sequences" addresses the challenges associated with training LLMs on extremely long sequences, which is important for applications like retrieval-augmented generation (RAG), long document summarization, and multi-modality. The proposed approach, Arctic Long Sequence Training (ALST), enables efficient long-sequence training by overcoming hardware constraints and making it accessible to a broader AI community through novel optimizations.
Problem Statement and Challenges
Current state-of-the-art LLMs, such as Meta's Llama 4 Scout, support sequence lengths up to 10 million tokens. However, efficiently training these LLMs on long sequences is challenging due to:
- Suboptimal Memory Usage: Typical LLMs are not optimized to fully utilize the available memory of a single GPU.
- GPU Memory Limitations: High sequence lengths demand more memory than a single commercially available GPU can offer. Tools to leverage multi-GPU setups have limited availability or compatibility with widely-used frameworks like Hugging Face Transformers.
- Framework Limitations: PyTorch, commonly used for LLM training, faces memory bottlenecks that restrict sequence length capabilities further.
Arctic Long Sequence Training (ALST) Methodology
ALST addresses these issues with a combination of three key optimizations:
- Ulysses Sequence Parallelism: This technique distributes the sequence load across multiple GPUs, facilitating aggregate memory usage without sacrificing the natural structure of attention mechanisms (Figure 1).
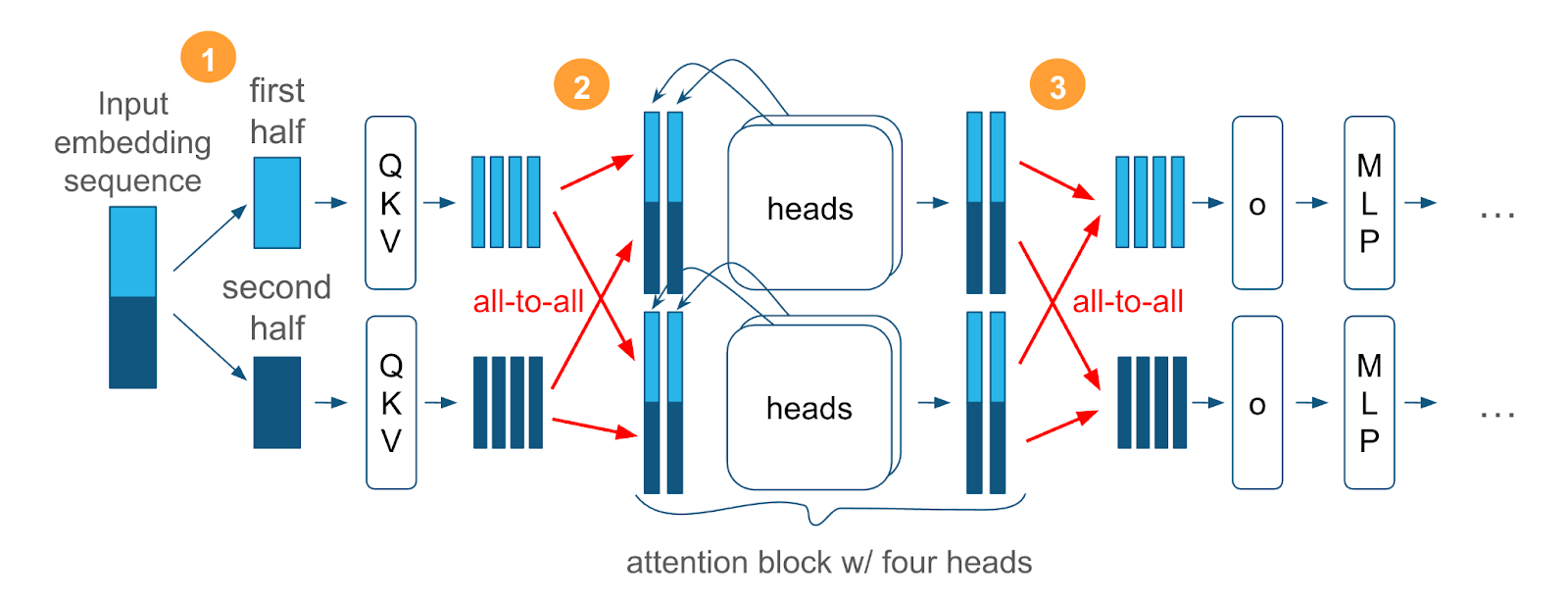
Figure 1: Ulysses Sequence Parallelism diagram with 4 attention heads per attention block model.
- Sequence Tiling: This reduces memory usage by dividing the computation of activations and gradients into smaller, manageable tiles instead of computing them all at once (Figure 2).
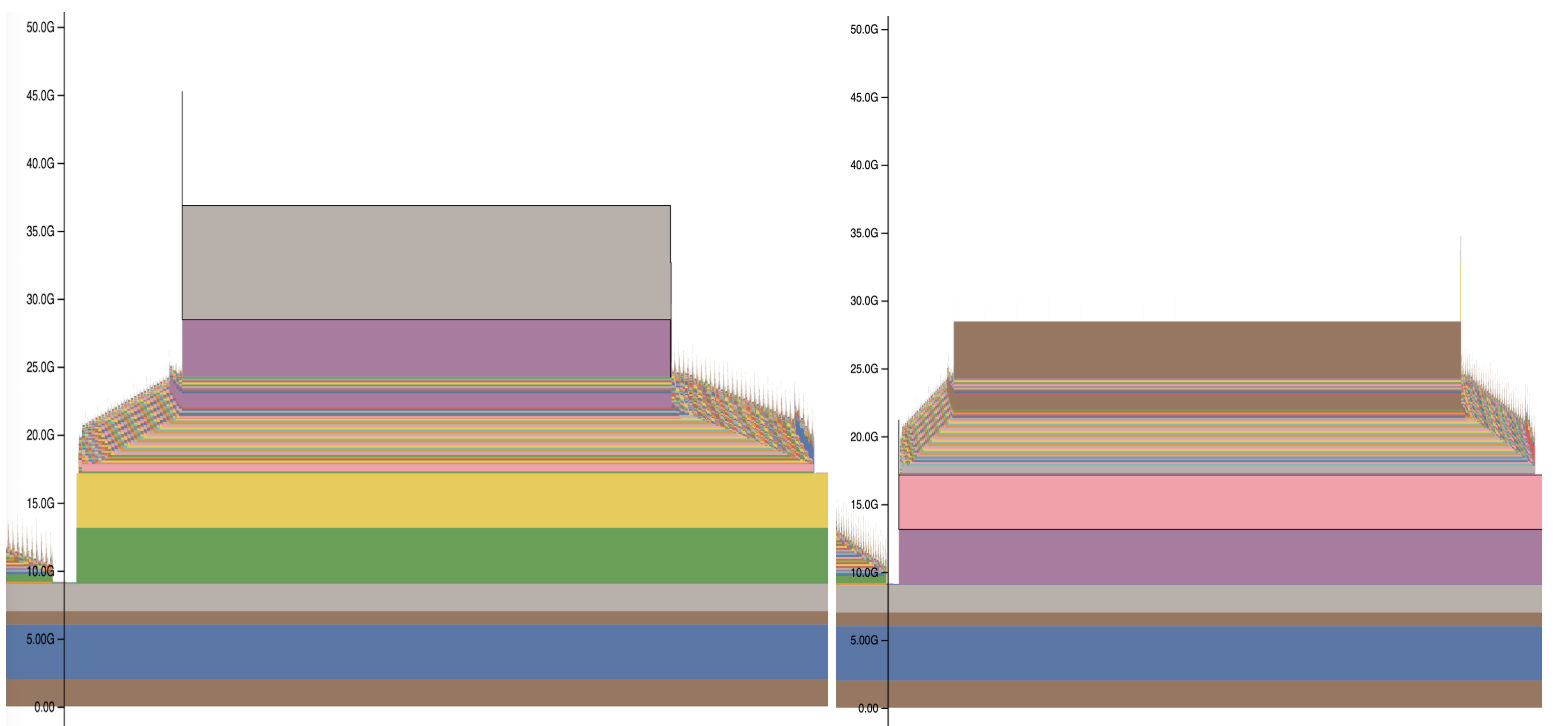
Figure 2: PyTorch memory usage plots before (left) and after (right) using Sequence Tiling to reduce loss calculation memory usage.
- PyTorch Optimizations: Optimizations include more efficient memory allocation strategies to minimize wastage and using activation offloading to shift temporary data to the CPU.
By integrating these components into ALST, it becomes possible to train models like Meta's Llama-8B with up to 15M sequence length—a significant increase over existing capabilities.
Implementation Considerations
Memory Profiling and Optimization: Through detailed memory profiling, key inefficiencies were identified within PyTorch. Ulysses Sequence Parallelism allows for the natural distribution of memory, which, when combined with activation offloading, enables significant memory conservation.
Sequence Tiling and Tiled MLP: By employing a tiled compute strategy, memory-intensive operations like MLP calculations are performed in segments. This was further extended in ALST with Tiled MLP to achieve over a 58% increase in sequence length capability in certain configurations.
Integration with Existing Frameworks: ALST was specifically designed to integrate with Hugging Face Transformers, allowing for seamless training without massive code alterations. This facilitates easy adoption by practitioners familiar with these platforms.
Evaluation
The performance of ALST was evaluated across different configurations of GPUs and model scales. In a single H100 GPU setting, ALST achieved a 16x increase in sequence length compared to the baseline (Figure 3).
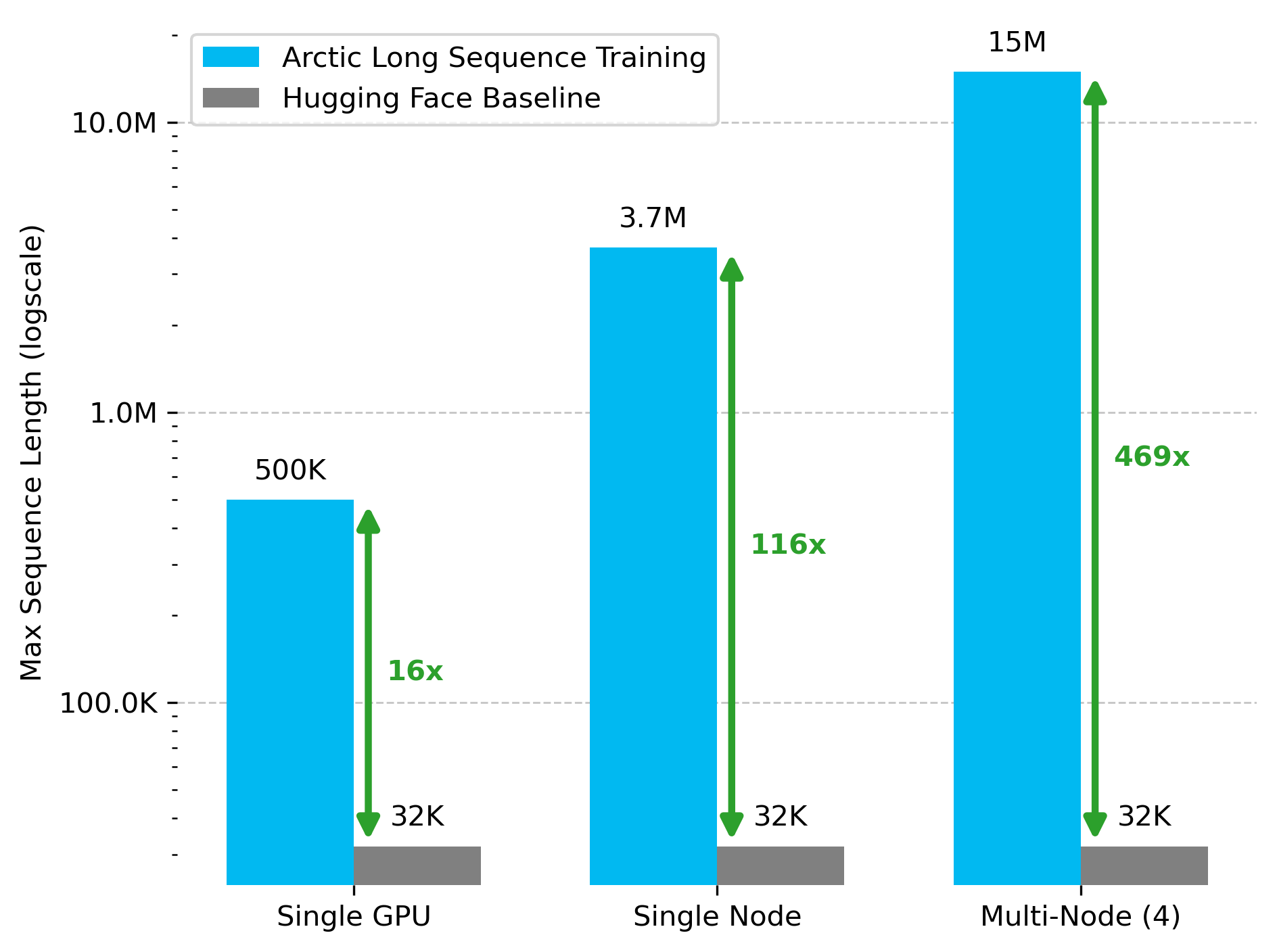
Figure 3: A dramatic improvement in sequence length with ALST enabled on 1, 8 and 32 H100 GPUs with Llama-8B. The baseline is Hugging Face with DeepSpeed ZeRO Stage 3 and optimizer states offload to CPU.
Conclusion
The Arctic Long Sequence Training framework significantly advances the capability for training on multi-million token sequences, democratizing access to such capabilities across less resource-intensive environments. It effectively balances GPU and CPU memory dynamics and leverages parallelism to handle the demands of extreme sequence lengths. Future work will further integrate ALST into broader frameworks to enhance accessibility and explore additional performance optimizations. This work is foundational for applications needing extensive sequence processing, enhancing both the theoretical and practical capabilities within the AI field.