- The paper demonstrates how a universal tokenizer, trained on a wide range of 69 languages, enhances LLM adaptability with up to 19% win rate improvements.
- It employs Byte Pair Encoding with a unique language weighting strategy, achieving +8x faster adaptation while preserving nearly identical accuracy.
- The study highlights practical gains in multilingual LLMs, offering efficient language support even for resource-scarce and previously unseen languages.
Multilingual LLMs and Universal Tokenizers
Introduction
The paper "One Tokenizer To Rule Them All: Emergent Language Plasticity via Multilingual Tokenizers" investigates how universal tokenizers can enhance the adaptability of large multilingual LLMs to new languages. By focusing on universally trained tokenizers, this study seeks to overcome the limitations of post-training language adaptation in LLMs related to language coverage and efficiency.
Background and Motivation
Training multilingual LLMs is challenging due to limited capacity, high computational costs, and scarcity of high-quality data for numerous languages. Previous work primarily addresses language adaptation post-pretraining through techniques like vocabulary extension or embedding retraining, which are resource-intensive. The lack of language coverage in tokenizers used during pretraining further complicates post-hoc language adaptation efforts.
Universal Tokenizer Approach
The proposed universal tokenizer strategy is central to this work. It involves training a tokenizer with data from a broader range of languages than those primarily used during pretraining. This approach aims to enhance the model’s language plasticity, allowing faster and more efficient adaptation to new languages. The core hypothesis is that a universal tokenizer can improve adaptability without degrading performance on the primary pretraining languages.
Figure 1:
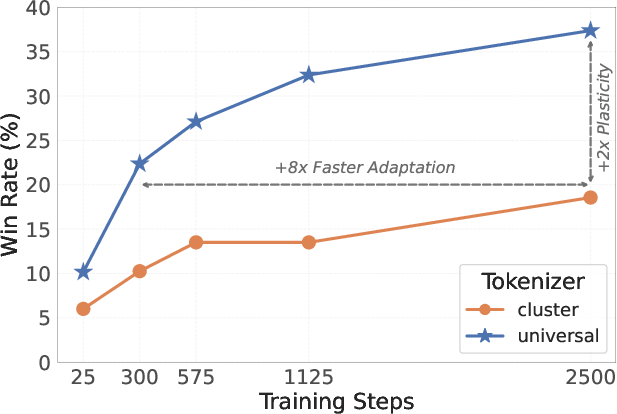
Figure 1: Universal tokenizer exhibits +2x higher plasticity with +8x faster adaptation compared to the cluster-specific baseline tokenizer.
Methodology
Language Coverage and Model Training
The experiments covered 69 languages, grouped into three geographic clusters: European, Asian, and Middle-Eastern & Indic languages. Models were pretrained on primary languages from each cluster, with systematic adaptation experiments conducted on an expanded set of languages. The adaptation experiments included strategies like continued pretraining and targeted adaptation, both for languages seen in tokenizer training and those completely unseen.
Tokenizer Specifications
The universal tokenizer was trained using Byte Pair Encoding across all languages, with a vocabulary size of 250k tokens. A unique feature of the tokenizer was its language weighting strategy, balancing the natural data distribution with language grouping by script and family.
Figure 2:
Figure 2: Win rates for models trained with the Universal and Cluster tokenizers against Dolly generations.
Results
The universal tokenizer demonstrated competitive performance with cluster-specific tokenizers on primary languages, maintaining performance differences within 0.5% average accuracy. Moreover, it showed superior plasticity on expanded languages, with up to a 19% increase in win rates during continued pretraining and a 14.6% improvement in targeted adaptations.
Figure 3:
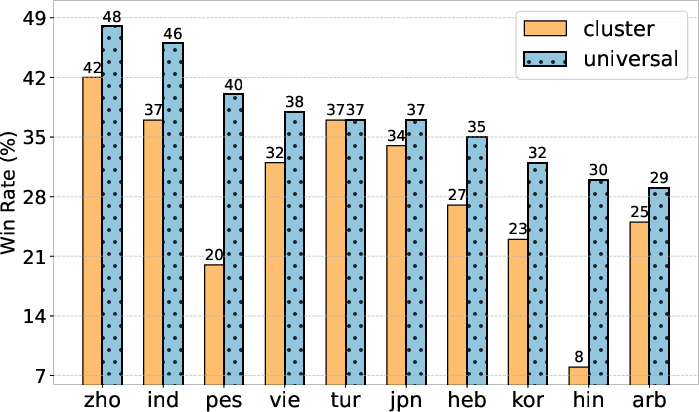
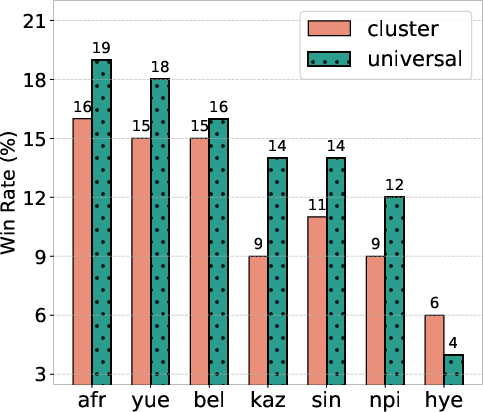
Figure 3: Universal tokenizer shows nearly the same performance with Cluster tokenizer throughout the training.
Adaptation Efficiency
The universal tokenizer enabled up to +8x faster adaptation for expanded languages, even when minimal additional data from new languages was included during pretraining. This efficiency significantly benefits practitioners aiming to expand language coverage with limited computational resources.
Discussion
The findings suggest that using a universal tokenizer from the outset can effectively boost the adaptability of LLMs to new languages. This method contrasts with the typical post-training techniques and showcases notable improvements in adaptation speed and efficiency. The universal tokenizer also shows promise for languages previously unseen in both tokenizer and pretraining stages, leading to gains of up to 5% in win rates.
Figure 4:
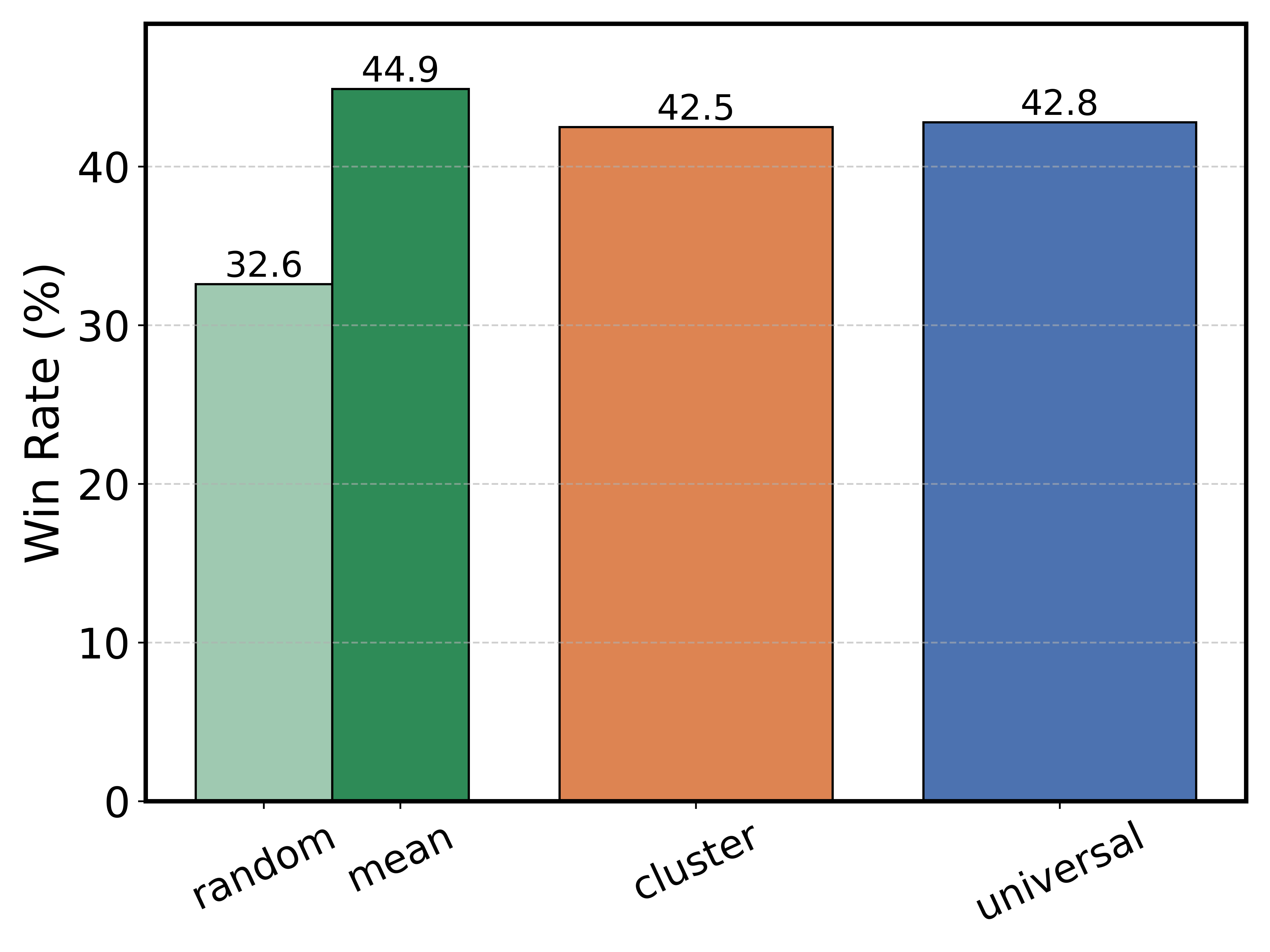
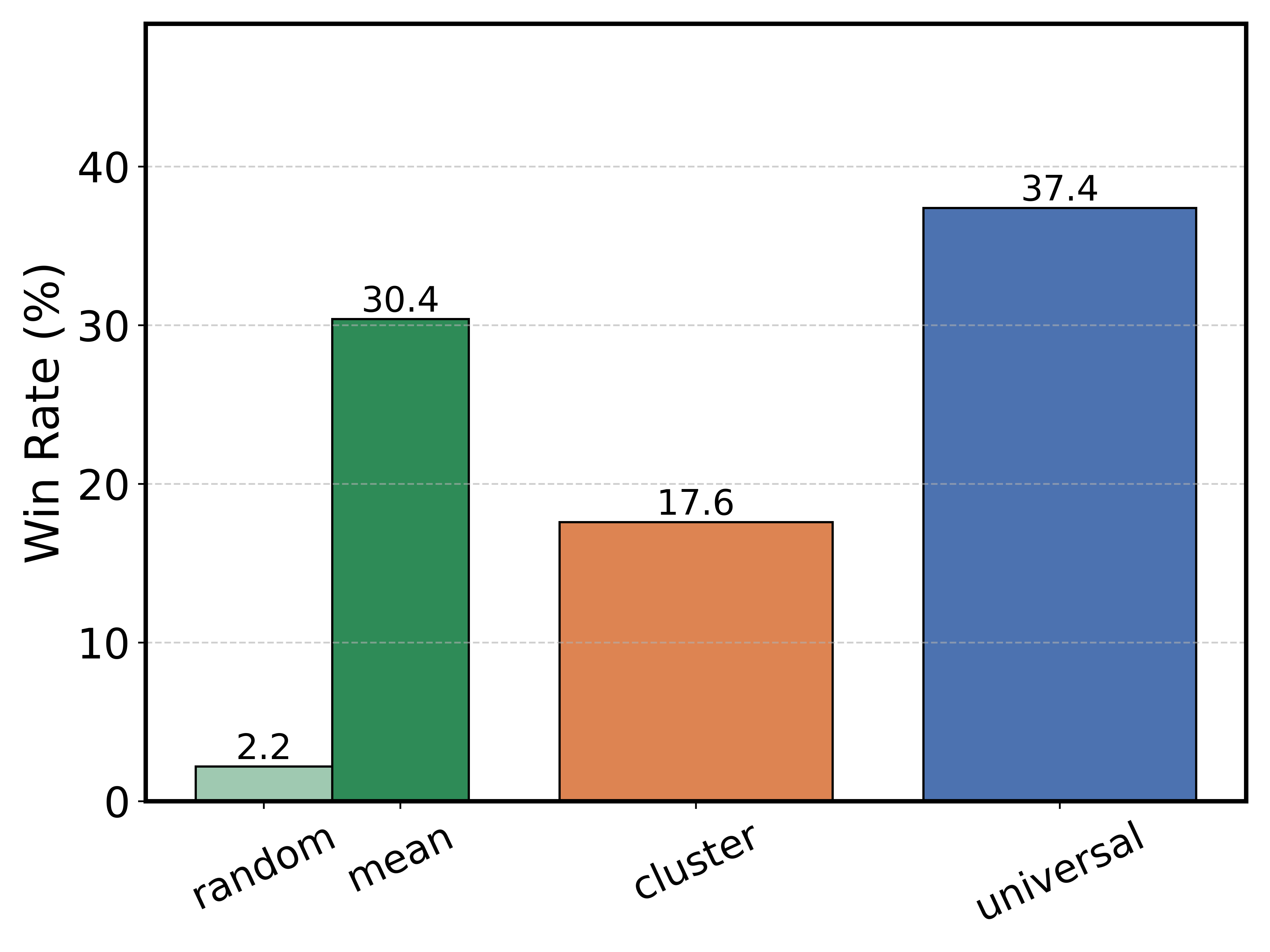
Figure 4: Adaptation results per language in Euro cluster together with tokenizers' compression ratio.
Conclusion
The study concludes that universal tokenizers significantly improve multilingual plasticity in LLMs and facilitate more efficient language adaptation strategies. This capability has important implications for expanding language support in AI systems globally, enabling more equitable technology access across diverse linguistic settings. Future research might explore integrating universal tokenizers with other language adaptation techniques to further optimize performance across an even wider range of languages.