- The paper introduces R-Search as a framework that integrates search into LLM reasoning via multi-reward RL, optimizing both the timing and integration of retrieved data.
- It employs multi-stage reward signals, including answer quality, evidence, and format rewards, to enhance factual accuracy and decision-making efficiency.
- Experimental results demonstrate up to 32.2% improvement in in-domain tasks and 25.1% in out-of-domain tasks, outperforming traditional RAG methods.
Summary of "R-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning"
The paper "R-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning" presents a robust framework designed to enhance the reasoning capabilities of LLMs through dynamic interaction with external search processes, optimized via reinforcement learning (RL). The proposed R-Search framework innovatively integrates search and reasoning tasks by utilizing a multi-reward signal approach to train models for improved decision-making regarding when to retrieve information and how to integrate it into reasoning processes.
Framework and Methodology
R-Search is constructed around the concept of coalescing multi-reward RL techniques to optimize reasoning-search interaction trajectories. The framework addresses two principal challenges: determining optimal timing for retrieval actions and ensuring deep interaction between retrieved content and reasoning chains. This is implemented by allowing LLMs to decide at any point in the token-level reasoning step whether to trigger a search, ensuring a seamless integration of retrieved knowledge.
The RL training process in R-Search is optimized through multi-stage, multi-type reward signals. These signals include answer quality, evidence quality, and format correctness. The evidence reward, in particular, encourages models to focus on maintaining high factual accuracy in intermediate reasoning steps, thus reducing errors associated with speculative or shortcut-driven responses.
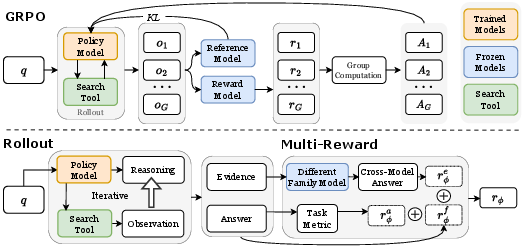
Figure 1: Overview of R-Search.
The effectiveness of R-Search is validated through extensive experiments on seven QA datasets, which encompass complex multi-hop and simpler single-hop tasks. The results highlight that R-Search consistently outperforms existing RAG (Retrieval-Augmented Generation) baselines, with improvements of up to 32.2% in in-domain tasks and 25.1% in out-of-domain tasks. These improvements underscore the framework's ability to conduct deep knowledge exploration and enhance LLM performance by effectively navigating complex reasoning pathways.
Analysis and Insights
The analysis within the paper shows that the adoption of GRPO over PPO leads to faster convergence and better outcomes, attributed to GRPO's avoidance of the critic architecture's instability in PPO. The experiments also reveal that larger models with more robust internal knowledge bases can achieve superior performance, reinforcing the benefit of using more powerful LLMs in conjunction with R-Search.
The number of valid searches conducted during training increases, indicating an enhanced capability of the model to conduct detailed examinations of available knowledge bases, ultimately leading to more factually accurate reasoning results.
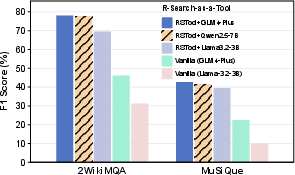
Figure 2: R-Search-as-a-Tool.
Conclusion
R-Search demonstrates significant advancements in integrating search functions within reasoning tasks using LLMs through a reinforcement learning framework that prioritizes multi-reward modeling. The framework's emphasis on factual accuracy and deep integration of search results into reasoning processes allows it to effectively tackle both simple and complex logic-intensive questions. Future work could expand on the incorporation of diverse and high-quality knowledge sources to further increase the model's effectiveness.
In summary, R-Search provides a powerful tool for improving the interaction between search and reasoning in LLMs, offering practical advantages for handling tasks requiring extensive logic and knowledge engagement.