- The paper introduces a formalism using the Free Energy Principle to derive self-organizing attractor networks that achieve orthogonal states via Bayesian inference.
- It employs a continuous Bernoulli distribution to bridge network architecture with stochastic Hopfield-like dynamics, optimizing predictive accuracy and memory capacity.
- In silico simulations validate key capabilities including robust sequence learning, optimal parameter tuning, and resistance to catastrophic forgetting.
Self-orthogonalizing Attractor Neural Networks Emerging from the Free Energy Principle
Introduction
The paper presents a formalism grounded in the Free Energy Principle (FEP) to describe the emergence of attractor networks. These networks inherently perform Bayesian active inference, optimizing predictive accuracy and model complexity. The study demonstrates that these networks self-organize without explicitly defined rules, using simulations to highlight emergent properties such as orthogonal attractor states which enhance generalization and reduce model complexity.
The Free Energy Principle and Network Dynamics
The Free Energy Principle, foundational to this study, provides a framework for understanding self-organization in complex systems. It posits that any viable system must minimize its variational free energy to maintain its structural integrity over time. This leads to systems that naturally partition into internal, external, and Markov blanket states, facilitating a dynamic interaction that is mathematically framed within this paper.
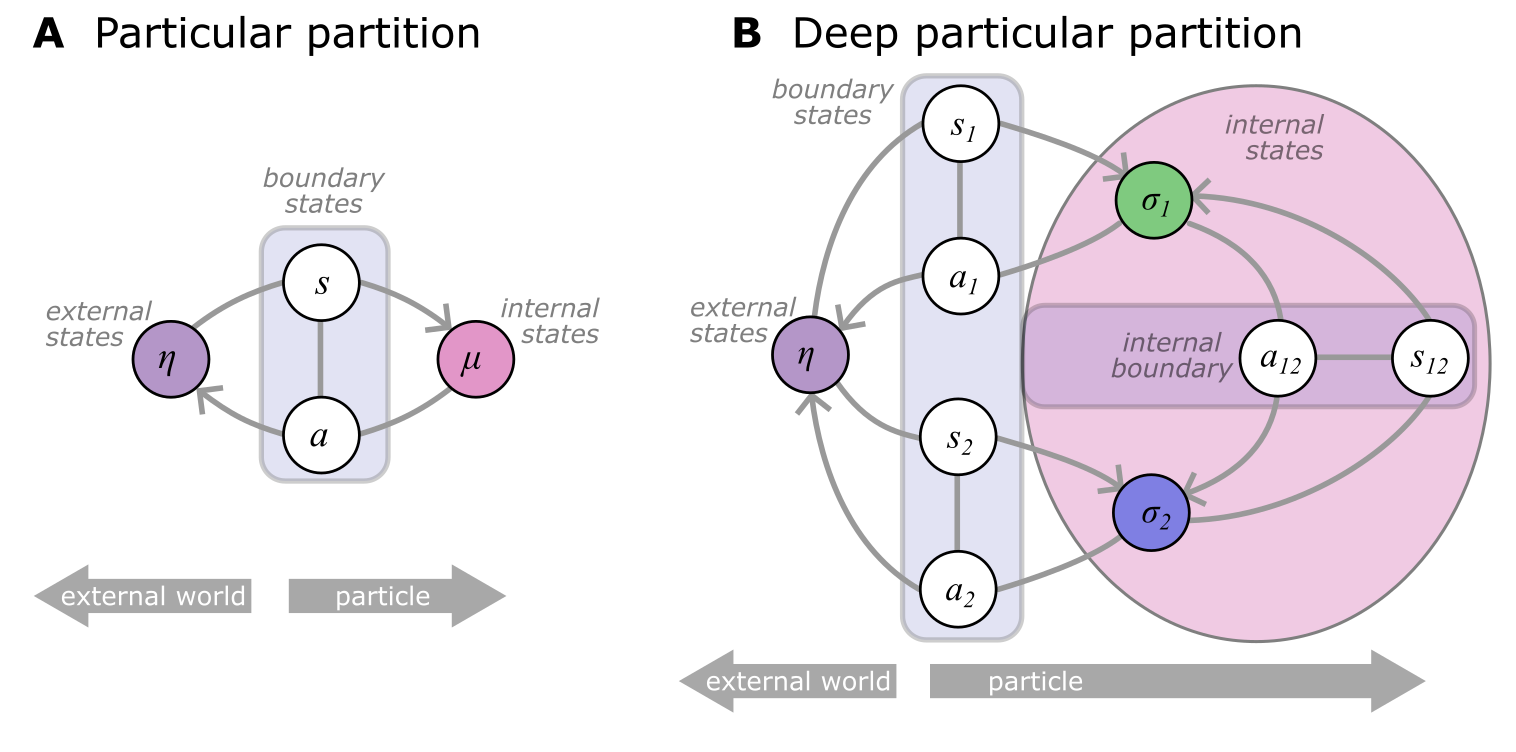
Figure 1: Schematic of a particular partition illustrating internal (μ) and external states (η), separated by a Markov blanket comprising sensory (s) and active states (a).
The core of this mechanism is the transformation of FEP into computational architectures that learn and adapt without explicit instructions. This is realized through the introduction of "deep particular partitions" which enables arbitrarily complex hierarchies within networks, conceptualizing each component as a Bayesian entity interlinked with others.
Network Parametrization and Emergence of Attractor States
The authors introduce an internal parametrization based on the continuous Bernoulli distribution, creating a network state dynamic representative of complex probabilistic interactions without explicit intervention.
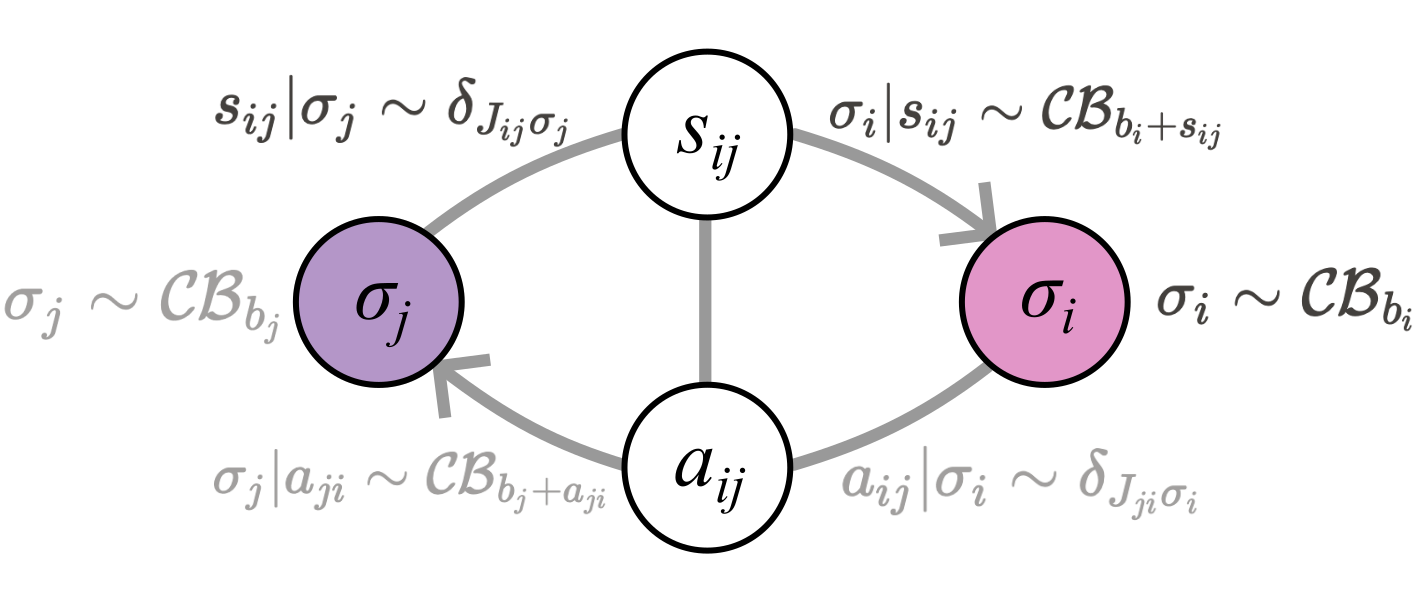
Figure 2: Parametrization of subparticles showing interaction via micro-scale boundary states, with internal states influencing one another through deterministic scaling.
This approach mathematically bridges the network's architecture with stochastic Hopfield-like dynamics, enabling the emergence of orthogonal attractor states through adaptive learning mechanisms. This orthogonality is central, optimizing model efficiency by minimizing redundancy in internal representations and potentially enhancing memory capacity significantly.
Bayesian Inference and Learning Dynamics
The inference and learning processes operate on the principles of variational free energy minimization. Local node-level inference is aligned with Bayesian updating, where biases are adjusted by integrating input from adjacent nodes, reflecting a locally precise yet adaptive inference mechanism.
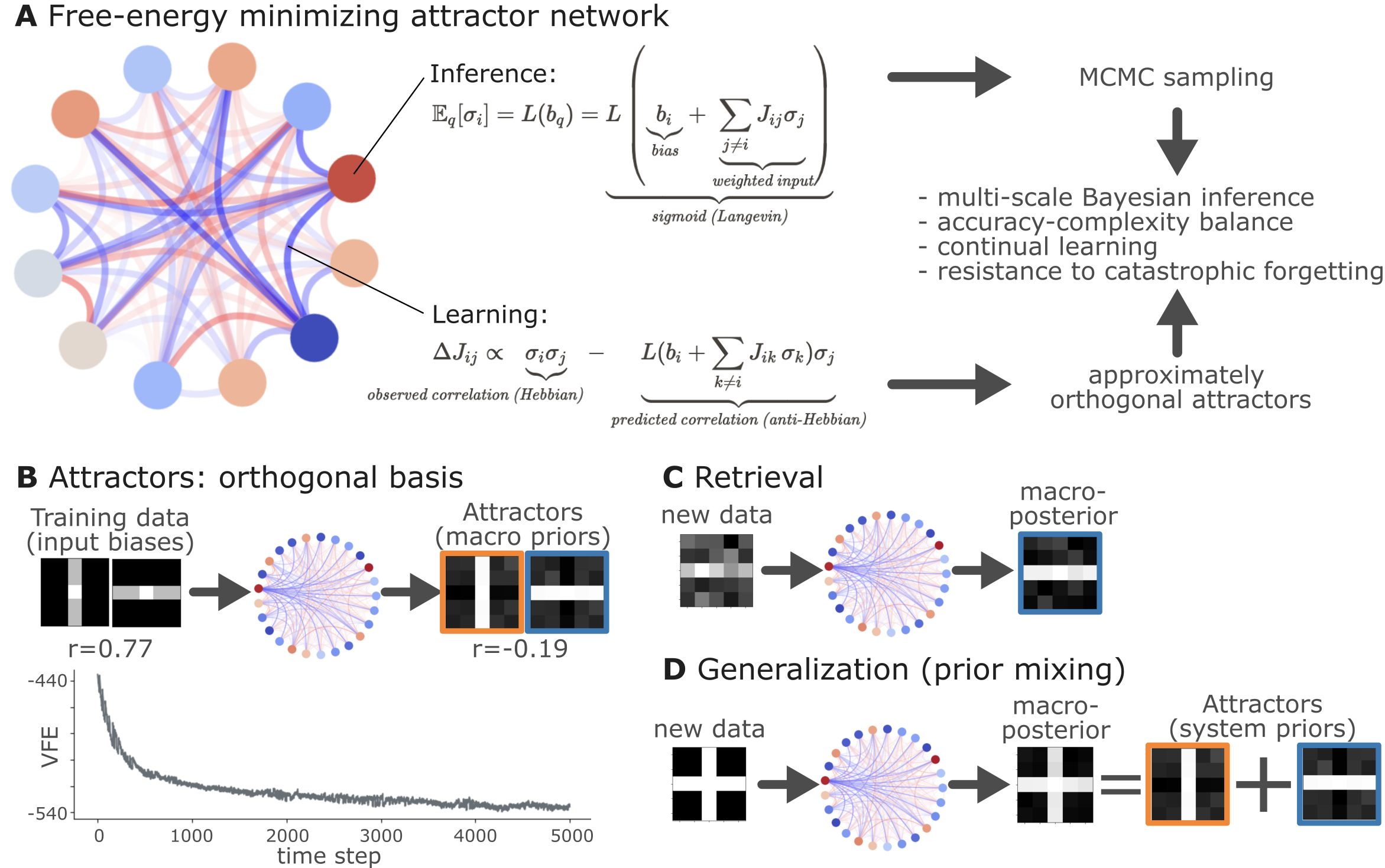
Figure 3: Free energy minimizing attractor network where inference and learning processes coalesce to form orthogonal basis of inputs.
These same principles extend to macro-scale inference due to the structure's inherent property of nesting particular partitions, encapsulating both local and global network dynamics within a single unifying framework.
In Silico Simulations
The implementation of four diverse simulations underpins this formalism:
- Orthogonal Basis Formation: Simulation demonstrates network's ability to form robust orthogonal attractor states from correlated inputs, highlighting enhanced retrieval and generalization.
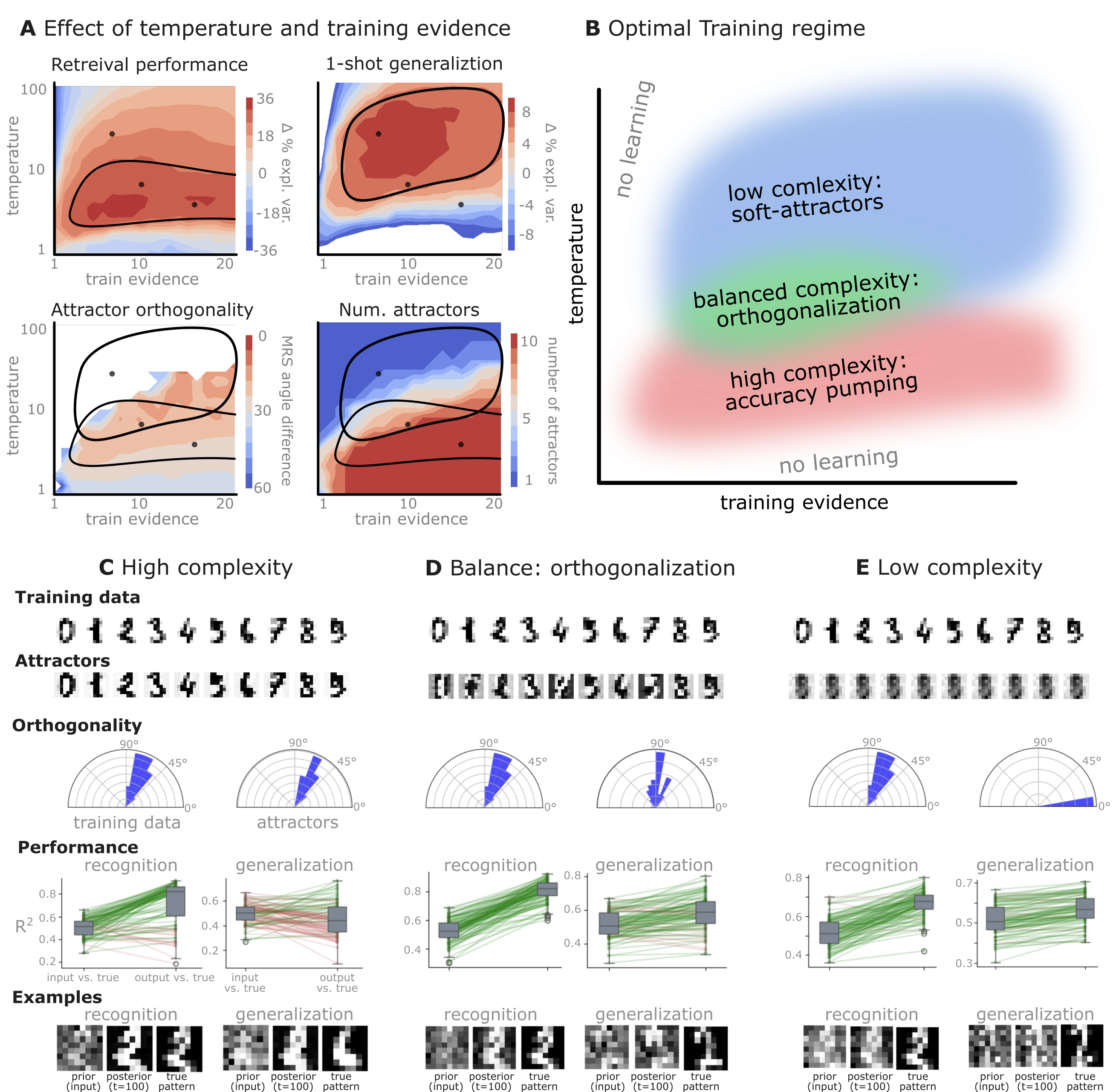
Figure 4: Performance landscapes revealing optimal inference parameters yielding highly orthogonal attractors.
- Learning Regimes: Extensive variance in training precision and evidence strength reveals an optimal parameter space fostering both high recognition and generalization capabilities.
- Sequential Dynamics: Networks trained in specific sequences produce asymmetric coupling matrices encoding temporal dynamics, thus showcasing the system's potential for sequence learning.
(Figure 5)
Figure 5: Sequence learned through network dynamics indicating spontaneous recall capabilities via asymmetric coupling networks.
- Catastrophic Forgetting Resistance: Spontaneous network activity reinforces attractor states, mitigating traditional issues with memory in dynamic environments.
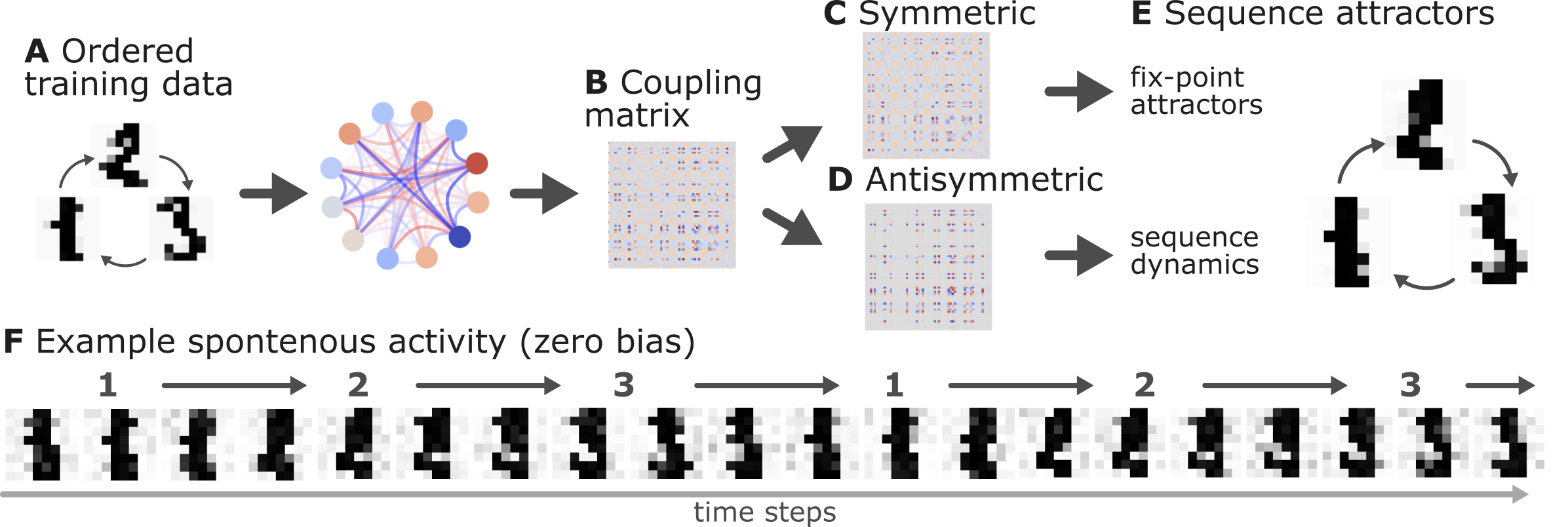
Figure 6: Demonstration of the network's resistance to forgetting, maintaining retrieval performance after extensive free-running periods.
Conclusion
The study illustrates a comprehensive architecture for self-organizing attractor networks via the Free Energy Principle. These systems exhibit remarkable properties, such as orthogonal attractors and robust Bayesian inference, presenting implications for both natural and artificial intelligence. The framework's scalability and generalizability propose potent avenues for future research aimed at leveraging these principles in larger, more complex environments.

