- The paper establishes provable benefits of latent space prediction by contrasting joint-embedding and reconstruction-based SSL methods.
- It introduces closed-form solutions for linear models that illustrate how data augmentation alignment mitigates irrelevant noise in feature learning.
- Experimental results validate that joint-embedding approaches outperform reconstruction methods in noisy, high-dimensional environments.
Joint Embedding vs Reconstruction: Provable Benefits of Latent Space Prediction for Self-Supervised Learning
Introduction
The increasing prominence of Self-Supervised Learning (SSL) in deep neural networks represents a significant shift within AI, particularly in the domain of representation learning. As the reliance on labels, which are constrained by their specialized nature, wanes, SSL offers an innovative alternative by focusing on the unstructured data's intrinsic properties. This study dissects two key paradigms within SSL: reconstruction-based and joint-embedding approaches. Each paradigm presents unique mechanistic advantages and challenges, and this paper seeks to establish clear criteria for selecting between them by elucidating the nuanced impacts of data augmentation on learned representations.
The predominant goal in SSL is to develop representations invariant to specific transformations assumed to be non-informative. Two SSL paradigms stand at the forefront: reconstruction-based methods, which restore original inputs from noisy versions, and joint-embedding methods, which learn similar latent space representations from varied augmented views of data. Both paradigms require minimal alignment of augmentations with irrelevant features for optimal performance, a requirement sharply distinct from supervised learning's invariants, primarily due to its use of labels.
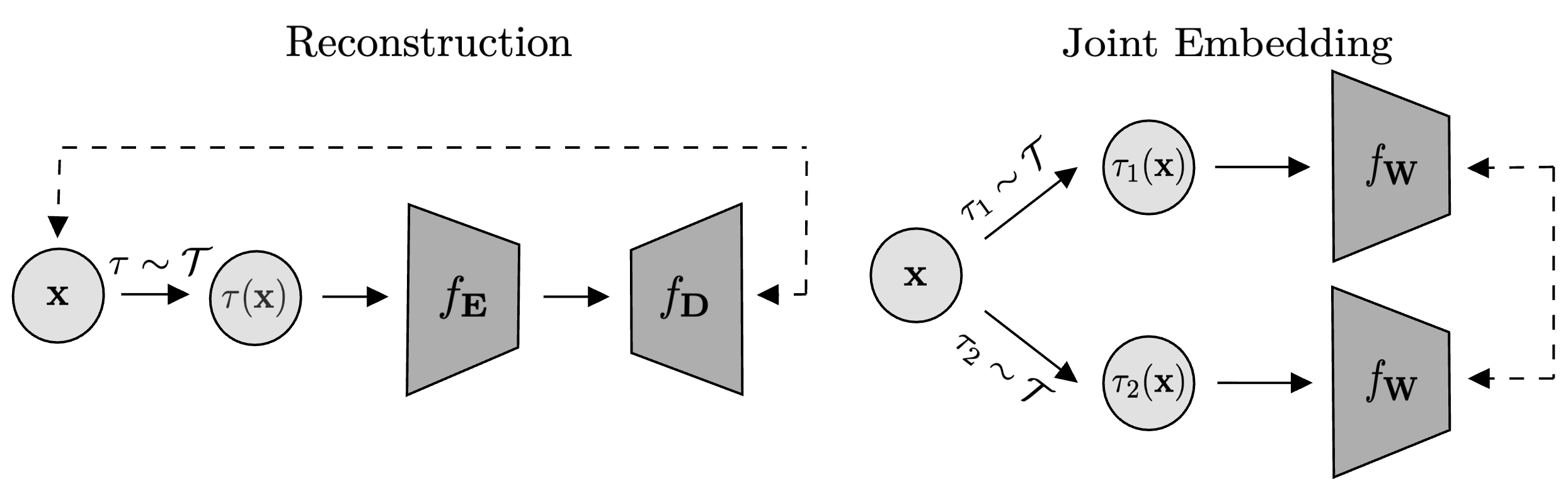
Figure 1: Two self-supervised learning paradigms illustrating the contrast between reconstruction and joint embedding approaches.
The Reconstruction-Based Approach
Reconstruction-based SSL methods leverage corrupted signals—infusing noise or masking to train models to accurately reconstruct inputs. This paradigm fosters the extraction of internal representations by emphasizing the variance that dominates the input. It excels in scenarios like natural language processing, where semantic units (words) are inherently informative. However, in visual domains, results are not as straightforward due to the noise intrinsic in raw sensory data like pixel values, resulting in variance-focused features that may lack semantic utility for higher-order tasks.
In vision applications, locally focused reconstructions risk learning tenuous features, requiring substantial fine-tuning to achieve useful downstream representations. The model's intrinsic capacity leans towards variance-heavy aspects, potentially missing perceptually significant details unless finely adapted to the task specifics.
The Joint-Embedding Approach
Joint-embedding strategies circumvent the reconstruction bias by aligning latent representations of varied augmented observations of the same input while disentangling differing inputs. Contrastive losses often facilitate this by explicitly enforcing representational boundaries. Models like BYOL and DINO embody this approach, promoting a learning focus on latent space projections rather than input space predictions. They have demonstrated robust performance in environments that are inherently high-dimensional and semantically sparse.
Joint-embedding approaches bear distinct advantages where irrelevance noise components heavily cloud the identification of key features. They retain sensitivity to task-relevant data attributes without needing distinct negative samples by exerting latent-space pressures, which makes them particularly resilient to intensity-driven data corruptions.
Empirical and Theoretical Contributions
This study introduces closed-form solutions for linear models within both paradigms to rigorously articulate how they are influenced by data augmentation strategies. The authors provide mathematical assurances that even simple alignment of augmentation with the noise facilitates the elimination of irrelevant data components, underscoring the crucial yet underappreciated role augmentation alignment plays in SSL. This stands contrary to the sample size strategy utilized in supervised learning environments.
Moreover, an experimental validation affirms these theoretical insights. High-fidelity scenarios with adversarial augmentations reveal joint-embedding models as sustaining robust performance amid noise, reflecting their capacity to abstract structural from destructural noise—an indispensable quality for deploying deep models in demanding real-world data landscapes.
Conclusions
The research presents a meticulously derived framework for discerning when to adopt reconstruction versus joint-embedding models based on informatively dense scenarios versus others diluted with high-magnitude irrelevant noise. Real-world datasets, which often feature unpredictable perturbations, benefit most from joint-embedding approaches due to their relaxed alignment prerequisites. Conversely, reconstruction methods fit better in lower-noise environments where variance alignment is naturally adequate.
The imperatives driving SSL's development and deployment underscore a critical need to refine augmentation strategies in tandem with model architecture advancements, which can further revolutionize performance and applicability in intricate data ecosystems. The insights provided lay groundwork for dangerous assumptions in SSL and propose targeted augmentations as a lever for superior performance, inviting further exploration into augmentations optimized for semantic coherence and task alignment.
