- The paper demonstrates that utilizing intermediate Transformer layer representations significantly improves topic coherence and diversity in topic modeling.
- It systematically evaluates 18 configurations with various pooling strategies like Mean, Max, and CLS across datasets such as 20 Newsgroups and UN texts.
- The study highlights that optimal pooling methods, especially Max pooling coupled with stop word removal, lead to clearer, more diverse topics.
Introduction
Topic modeling plays a pivotal role in extracting structured information from text corpora, where BERTopic, a state-of-the-art TM approach, has emerged as a potent tool for generating coherent topics utilizing Transformer-based embeddings. This study investigates the efficacy of using intermediate layer representations from Transformer models within BERTopic, exploring 18 diverse configurations across multiple datasets, including 20 Newsgroups, Trump Tweets, and United Nations texts. The focus is on whether alternative embedding strategies can surpass default settings, thereby enhancing TM performance metrics like topic coherence and diversity.
Methodology
The research employs a systematic approach by deriving embeddings from various layers of Transformer models, using pooling strategies (Mean, Max, CLS) to enhance topic coherence and diversity outcomes. The configurations include outputs from layers such as the last, second-to-last, and aggregated outputs (sum or concatenate), thereby probing the impact of these diverse embeddings in TM tasks.
A visual depiction of potential embeddings retrievable from a model is instrumental in understanding these possibilities:
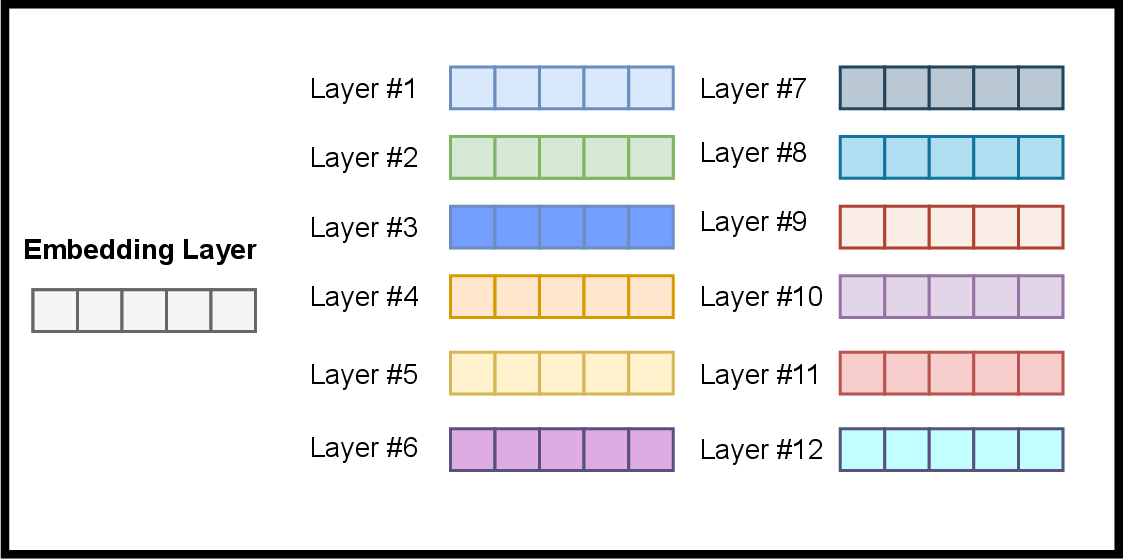
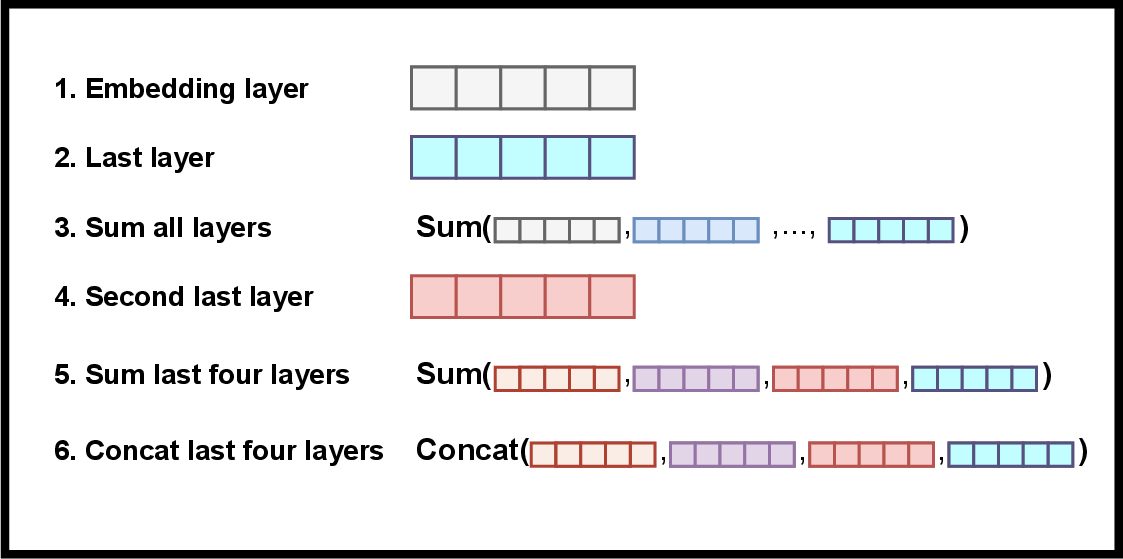
Figure 1: Possible to retrieve embeddings from the model.
The experimental evaluation adheres to previous datasets used in BERTopic to ensure comparability and encompasses modifications like replacing the BBC News dataset with larger UN General Debate transcripts to address size limitations.
Experimental Results
The results, detailed across datasets, reveal key trends:
- Default Configuration Limitations: The study finds that the default BERTopic configuration (Mean pooling with last layer) can be improved upon, affirming that leveraging different layers can enhance TM quality.
- Embedding Layer Insights: Negatively impacts coherence scores in certain settings, emphasizing the influence of layer selection (e.g., CLS pooling underperforms).
- Pooling Strategy Effectiveness: Max pooling achieves optimal topic diversity across numerous configurations.
A noteworthy observation highlights the considerable enhancement achieved when stop words are removed, underscoring an improvement in metric scores and resulting in more precise topic delineation.
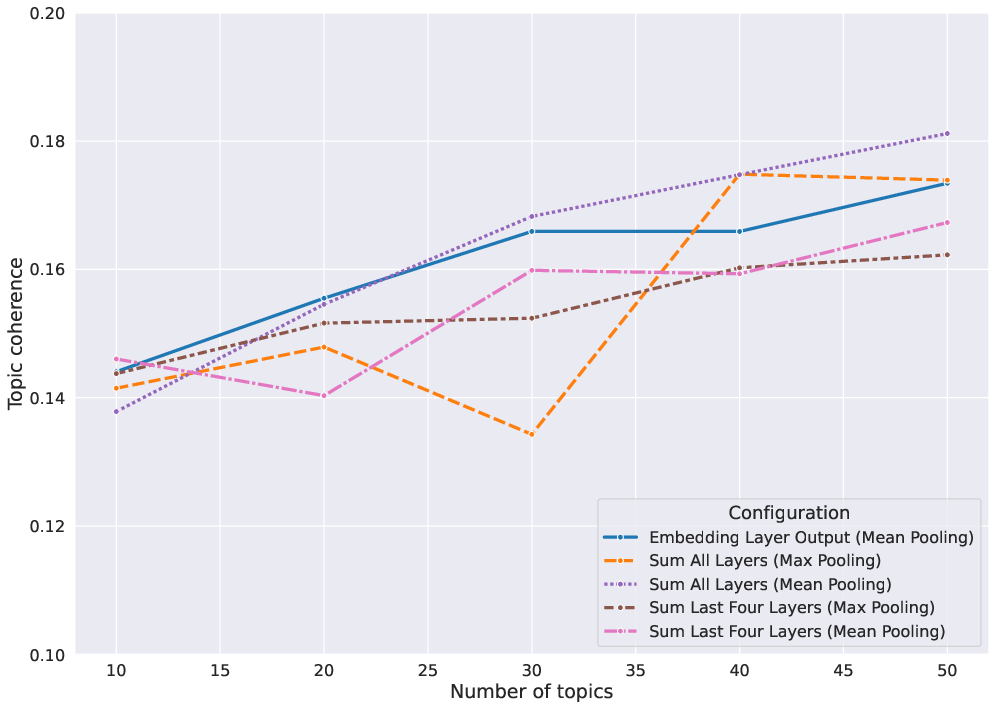
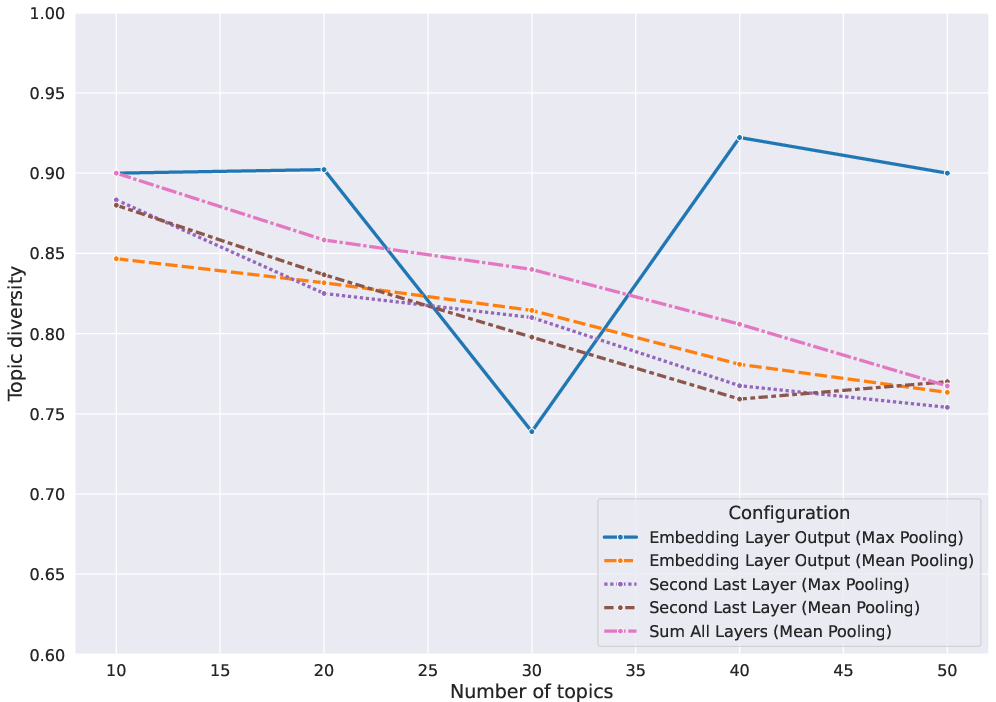
Figure 2: Topic coherence scores.
Advanced Configuration Analysis
A deeper examination of topic models reveals stark contrasts in topic word scores between the least and most effective configurations. The visualization highlights that configurations such as Sum All Layers with Max pooling facilitate clearer and more diverse topic identification compared to others, such as the Embedding Layer with CLS pooling.
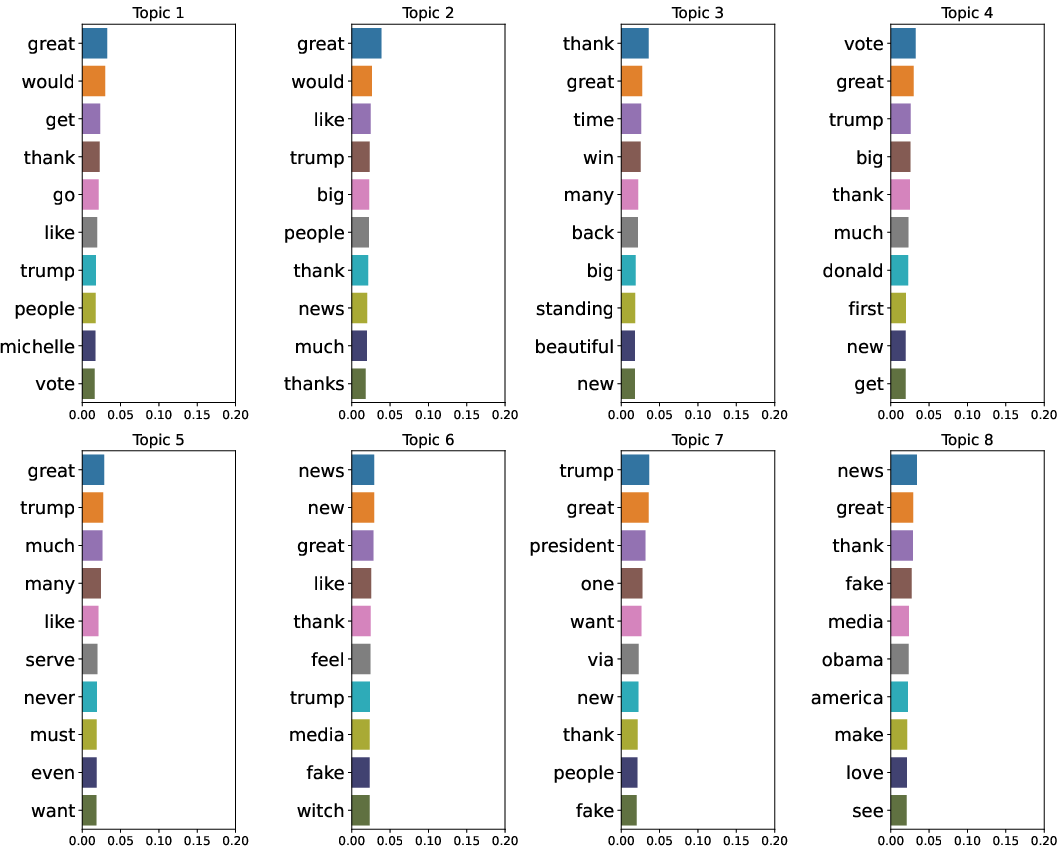
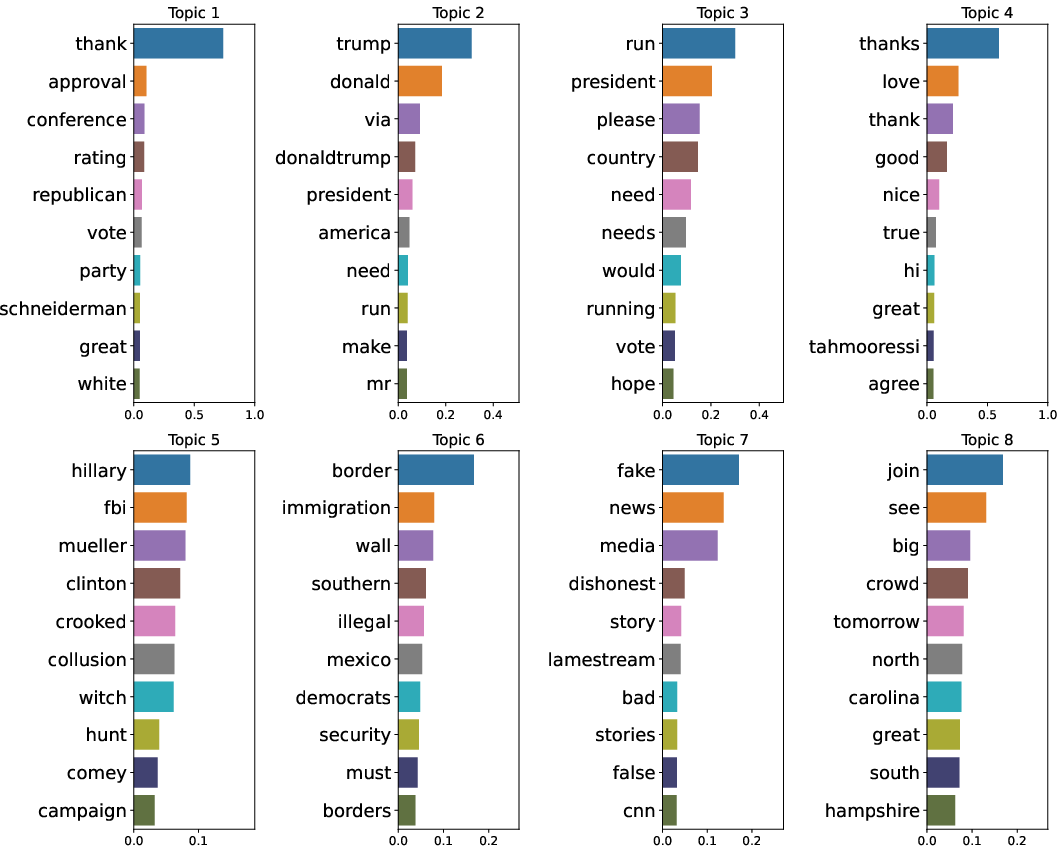
Figure 3: Topic word scores for Embedding Layer with CLS pooling configuration.
Such analyses underscore the significance of both the chosen embedding layers and pooling strategies in influencing the interpretability and relevance of topic models.
Dynamic Topic Modeling
The study extends the analysis to DTM, examining temporal shifts in topics across datasets like Trump Tweets, thus enhancing understanding of topic evolution over time. This application demonstrates the utility of BERTopic in tracing topic prevalence and transformation through periods, further augmented by intermediate layer representations for bolstered coherence and diversity.
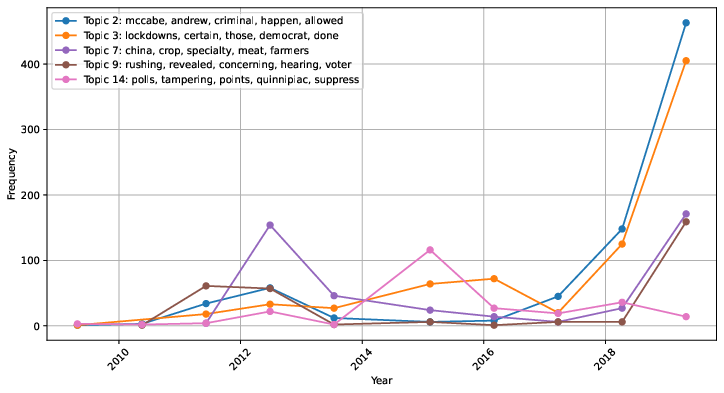
Figure 4: Frequency of selected topics estimated from Trump Tweets dataset over the years. Topics have been created by utilizing the best configuration in terms of topic coherence (Concat Last Four Layers with Max pooling).
Conclusion
This investigation into the use of intermediate layer representations within BERTopic elucidates a path for enhancing TM approaches beyond default settings. The findings highlight that through meticulous selection of embedding layers and pooling methods, significant improvements in coherence and diversity can be achieved. These insights pave the way for further exploration into automated methods for optimizing TM processes, particularly employing advanced NLP models for evaluation, potentially obviating the need for labor-intensive manual assessments. Future work should concentrate on unraveling the underlying dynamics of Transformer layers' contributions to topic characterization, thereby refining interpretive power and applicability in real-world scenarios.

