- The paper demonstrates that retrieval-augmented prompting triples tool selection accuracy (43.13% vs. 13.62%) compared to baseline methods.
- The paper shows that reducing prompt size by over 50% improves context efficiency, enabling scalability with thousands of MCP entries.
- The paper introduces a three-step pipeline—semantic retrieval, compatibility validation, and selective prompting—for dynamic LLM tool integration without model retraining.
Motivation and Context
Recent expansion of Model Context Protocol (MCP) repositories has presented a scalability crisis for LLM-based tool selection. As LLM agents increasingly rely on external function-calling APIs, prompt bloat—resulting from the need to inject hundreds or thousands of tool descriptions into inference prompts—chokes both context window efficiency and selection reliability. This phenomenon is exacerbated by semantic overlap across tools and is empirically validated via a context stress test paralleling Needle-in-a-Haystack (NIAH) benchmarks. Naïve full-context prompting and baseline keyword filtering approaches suffer dramatic declines in accuracy with expanding MCP pools. To systematically address these limitations, the RAG-MCP framework embeds a semantic retrieval pipeline for pre-selecting relevant MCP schemas prior to LLM invocation, thus decoupling tool discovery from generation.
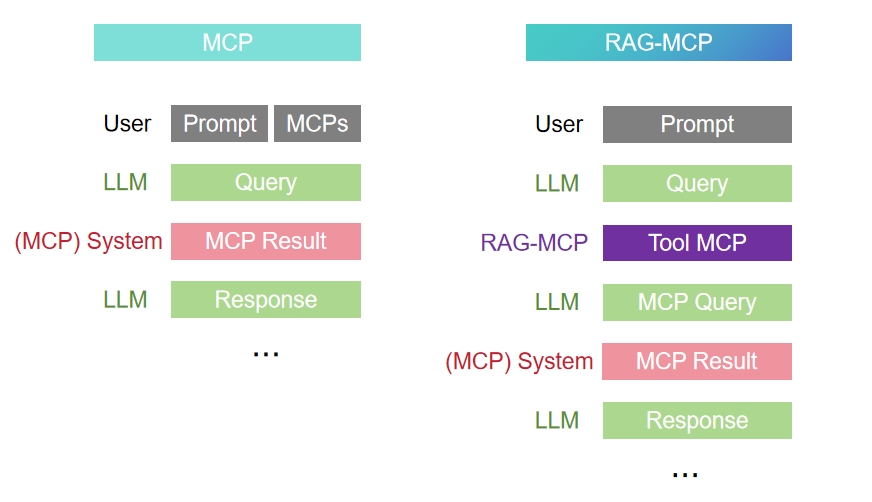
Figure 1: Comparison of inference workflows for baseline MCP (full-prompt) versus the retrieval-augmented RAG-MCP approach.
RAG-MCP Architecture
The RAG-MCP system operationalizes a three-step pipeline:
- Semantic Retrieval: Query encoding with Qwen-max precedes dense vector-space search over a registry of MCP tool descriptions. Top-k matches are selected by cosine similarity.
- Compatibility Validation: Candidate tools may be validated with synthetic queries to ensure interaction viability, functioning as a pre-invocation filter.
- Selective Prompting: Only the top candidate MCP’s schema is injected into the LLM prompt, eliminating irrelevant distractor metadata.
This architecture allows flexible, on-the-fly integration of new tools without retraining the LLM, as proxied through external index updates.
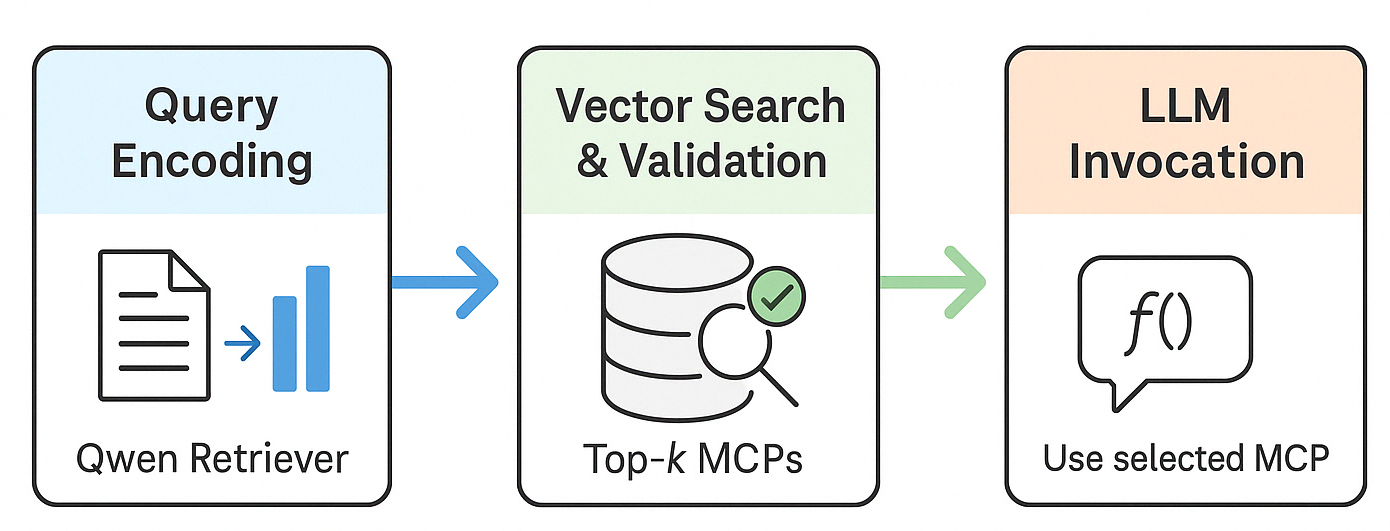
Figure 2: The RAG-MCP pipeline detailing query encoding, retrieval/validation of tool schemas, and ultimate invocation via function-calling.
Empirical Evaluation
MCP Stress Test
A stress test utilizing 20 web-search tasks and varying N (tools available per trial from 1 up to 11100) demonstrates sharp, non-monotonic degradation in baseline accuracy as N increases. For ground-truth MCP servers buried among thousands of distractors, retrieval-augmented selection is critical for acceptable performance.
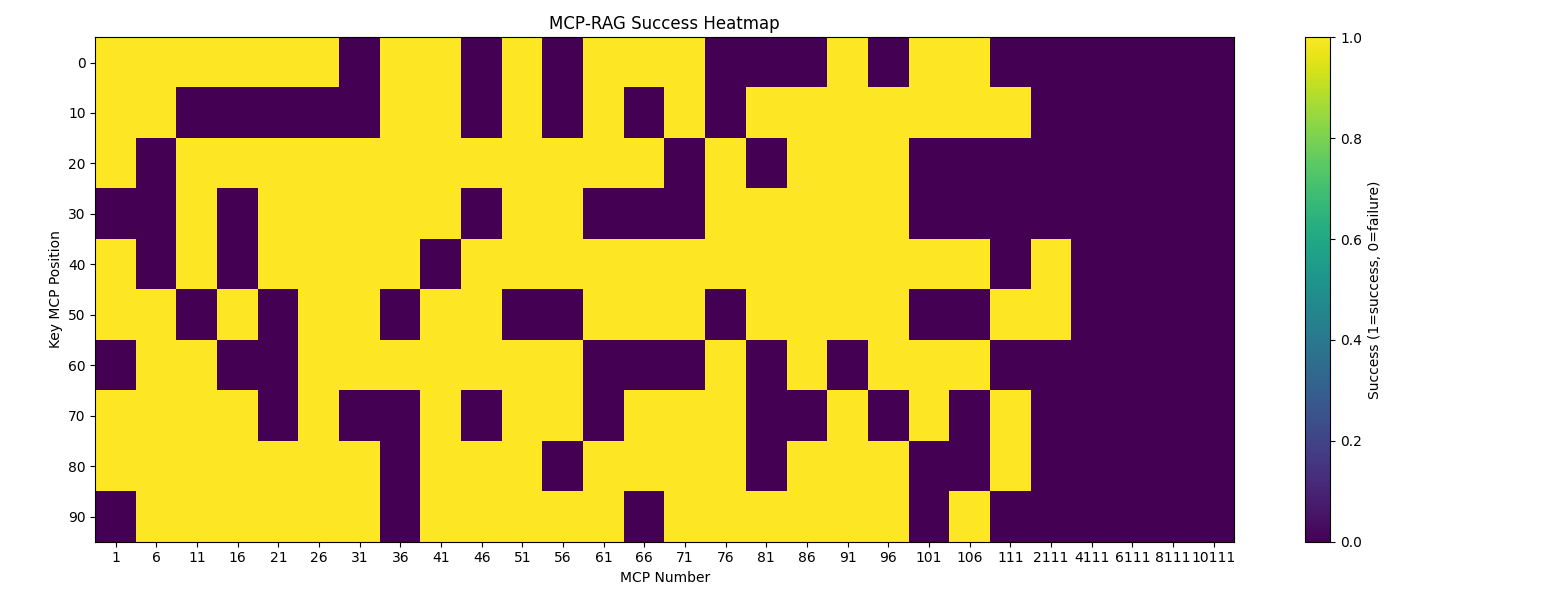
Figure 3: Per-trial success (yellow) and failure (purple) heatmap across MCP index positions, showing clear scale-dependent degradation.
Main Results
On MCPBench web search tasks, RAG-MCP triples tool selection accuracy compared to naïve full-context prompting (43.13% vs. 13.62%), and more than halves prompt token consumption (1084 vs. 2133.84). Actual Match, using simple keyword filtering, yields a modest improvement (18.2%), but is decisively beaten by the retrieval-augmented framework. While RAG-MCP incurs a marginal increase in output token count, this correlates with deeper and more successful execution traces, validated under Llama-based automatic evaluation.
Strong Numerical Findings
- Accuracy Improvement: RAG-MCP achieves 43.13% selection accuracy versus 13.62% for blank conditioning baselines, and 18.2% for keyword-matched retrieval.
- Prompt Size Reduction: Prompts shrink by over 50% (from 2133.84 to 1084 tokens) compared to naïve baselines.
- Scalability: The system remains robust in MCP pools up to several thousand entries, though retrieval precision naturally degrades at very high index cardinality.
Analysis and Implications
RAG-MCP’s retrieval-based context management fundamentally restructures tool selection as a two-stage process, removing discovery from the LLM’s generative mandate. The results indicate that prompt efficiency (token reduction) not only facilitates compliance with hardware constraints (context window length), but also enhances cognitive focus required for reliable tool selection. Notably, the architecture supports continuous extensibility—new MCPs may be indexed on-the-fly—without additional model tuning, which is crucial for practical deployment in rapidly evolving plugin/API ecosystems.
The observed scale-dependent performance drop (Figure 3) motivates further research in hierarchical index structures or adaptive retrieval strategies, especially as MCP repositories approach tens of thousands of entries.
Theoretical and Practical Prospects
From a theoretical perspective, RAG-MCP supports the paradigm shift where LLMs evolve from monolithic, context-crammed agents toward modular systems integrating external, discoverable knowledge and action schemas. This decoupling suits both current hardware limitations and the trajectory toward ever-expanding tool/plugin universes. Practically, the framework enables more robust, up-to-date, and cost-efficient AI assistants—capable of interfacing with both legacy and bleeding-edge services at scale. Longer term, this signals the emergence of agentic LLMs that leverage dynamic external knowledge, functional modularity, and selective context presentation, all managed without catastrophic inference-time overload.
Conclusion
The RAG-MCP methodology provides a robust solution for mitigating prompt bloat and selection complexity associated with large MCP pools. By moving discovery to an external retrieval module, RAG-MCP achieves substantial improvements in accuracy and efficiency, ensuring scalable tool integration for next-generation LLM agents. Future directions include hierarchical retrieval mechanisms for ultra-large registries and the extension to multi-tool workflows, cementing RAG-MCP’s role in scalable, agentic AI protocol architectures.
Reference: "RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation" (2505.03275).