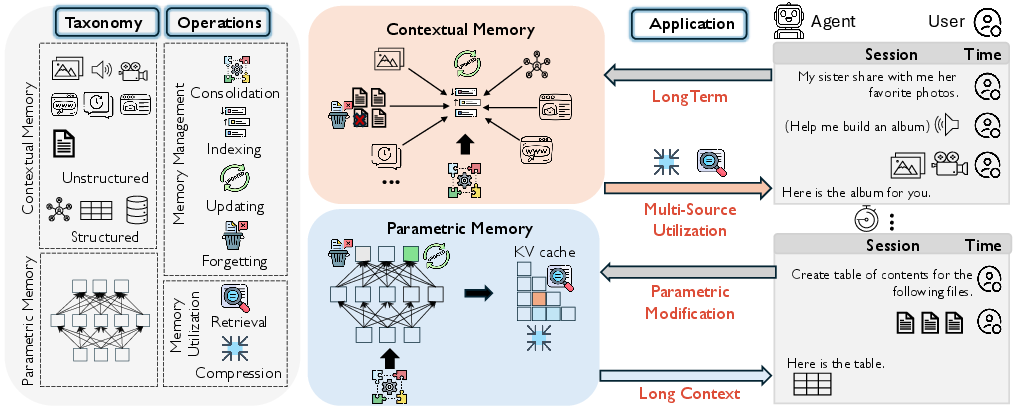
- The paper introduces a structured taxonomy that categorizes memory into parametric, contextual structured, and contextual unstructured types.
- It details six core memory operations—consolidation, indexing, updating, forgetting, retrieval, and compression—to enhance dynamic AI performance.
- The study outlines future directions such as lifelong learning, unified memory representation, and secure memory practices for advanced AI applications.
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
The paper "Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions" (2505.00675) offers a comprehensive survey of memory mechanisms within AI systems, focusing on the roles these mechanisms play in the functioning of LLM-based agents. This paper introduces a structured approach to understanding and implementing memory in AI systems by organizing complex memory operations and their interactions with different types of memory.
Memory Taxonomy and Types
The paper delineates memory types into three categories: parametric, contextual structured, and contextual unstructured memory.
The use of these categorized memory types is pivotal for optimizing AI interactions over varying timescales and contexts, offering avenues for nuanced AI applications demanding long-term adaptation and knowledge retention.
Core Memory Operations
Six fundamental memory operations form the backbone of how AI systems manage and utilize memory:
- Consolidation involves integrating new experiences into enduring memory forms, facilitating continuous learning.
- Indexing creates efficient memory access points through structured mapping.
- Updating and Forgetting accommodate necessary modifications and strategic knowledge pruning for memory relevance.
- Retrieval facilitates the extraction of pertinent memories to enhance reasoning or decision-making processes.
- Compression streamlines memory use by retaining essential details for efficient resource management.
These operations are crucial for maintaining dynamic and scalable memory systems, supporting capabilities such as long-context reasoning and lifelong learning.
System-Level Applications and Research Topics
The paper maps emerging research topics to these operations, emphasizing areas like long-term dialogue modeling and parametric memory modification. The systems leverage combinations of memory operations to address specific challenges:
- Long-Term Memory Utilization supports sustained dialogue and historical context integration, crucial for personalized AI interaction.
- Long-Context Memory addresses handling extended sequence data, emphasizing memory retrieval and contextual compression to manage large inputs efficiently.
- Parametric Memory Modification enables adaptive learning via targeted edits within the model's parameters, vital for real-time knowledge adaptation.
- Multi-Source Memory Integration focuses on reasoning across heterogeneous data sources, essential for robust multi-modal AI applications.
These applications highlight the dynamic interplay between memory types and operations, facilitating AI advancement through improved memory-centric capabilities.
Implications and Future Directions
The survey outlines several promising directions for enhancing AI memory systems:
- Lifelong Learning and Evolutionary Memory: Pursuing frameworks that balance knowledge stability and adaptability across parametric and contextual memory paradigms.
- Unified Memory Representation: Developing cohesive frameworks to enhance memory consolidation and retrieval across varying knowledge forms and modalities.
- Spatio-temporal Memory Models: Mimicking biological systems' memory architectures to enable temporally informed reasoning and nuanced decision-making.
Furthermore, the study suggests addressing paramount security concerns associated with memory operation vulnerabilities, pressing for innovations in secure memory management practices.
Conclusion
By offering a structured examination of memory in AI systems, this paper elucidates critical memory operations and their implications for current and future AI capabilities. It serves as a blueprint for navigating the complex landscape of AI memory systems, guiding future research towards more refined and secure memory management methodologies that enhance the practical applications of AI across various domains.