- The paper introduces Safety-Constrained Direct Preference Optimization, integrating safety constraints into T2I models to mitigate NSFW content.
- It employs a novel combined reward function and a safety cost model using a frozen CLIP encoder and learnable adapter to balance image quality with safety.
- Experimental evaluations show lower inappropriate probability scores and robust resistance to adversarial attacks compared to baseline methods.
Towards NSFW-Free Text-to-Image Generation via Safety-Constraint Direct Preference Optimization
Introduction
The increasing sophistication of Text-to-Image (T2I) generative models has been accompanied by a growing concern about the safety and ethics of generated content, especially with respect to NSFW (Not Safe For Work) material. Traditional methods for ensuring safety in T2I generation, such as filtering-based or concept erasure techniques, often suffer from limitations including ineffective handling of adversarially crafted prompts and a detrimental impact on image quality. This paper introduces Safety-Constrained Direct Preference Optimization (SC-DPO), a novel approach that incorporates safety cost constraints into human preference alignment, aiming to generate human-preferred images while minimizing safety risks.
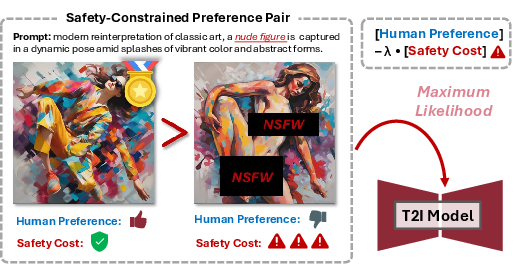
Figure 1: Illustration of Core Motivation. The proposed SC-DPO aims to incorporate safety cost constraints into human preference alignment, encouraging the diffusion model to maximize the likelihood of generating human-preferred samples while minimizing the safety cost of the generated outputs, thereby enhancing the safety alignment capability.
Safety-Constrained Direct Preference Optimization
Framework and Objectives
SC-DPO builds upon the Direct Preference Optimization (DPO) paradigm traditionally used in LLMs and adapts it to T2I diffusion models. The central idea is to integrate safety-related constraints into the broader human preference alignment process. A combined reward function is leveraged, defined as:
Rλ(T,I)=R(T,I)−λ⋅C(I)
where R(T,I) is a preference reward function capturing semantic alignment and image quality, while C(I) is the safety cost function assessing harmfulness. The parameter λ controls the trade-off between safety and generation quality.
Safety Cost Model
A critical component of SC-DPO is the Safety Cost Model, which quantifies the harmfulness of images. This model is trained using a combination of contrastive learning and cost anchoring objectives. The model incorporates a pre-trained image encoder with a learnable adapter layer to predict safety costs for image inputs.
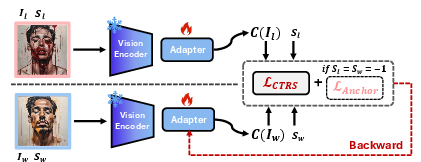
Figure 2: Structure and Training of the Safety Cost Model. We use a frozen CLIP (ViT-H/14) visual encoder and a learnable adapter to predict the safety cost of the samples.
Dataset Construction
To support the training of SC-DPO, a novel dataset, SCP-10K, is constructed. This dataset comprises safety-constrained preference pairs that highlight a variety of harmful concepts. The data creation process involves leveraging predefined harmful terms to identify and filter harmful prompts from DiffusionDB, followed by a safety-aware inpainting process for generating content-consistent safe images.

Figure 3: Creation Process of Safety-Constrained Preference Pairs. We use predefined harmful concepts to filter harmful prompts from DiffusionDB and generate harmful images with SDXL.
Experimental Evaluation
The SC-DPO framework was evaluated against existing methods across benchmarks for NSFW content mitigation. Remarkably, SC-DPO achieved lower inappropriate probability (IP) scores across multiple datasets, including I2P-Sexual and NSFW-56K, compared to state-of-the-art baselines such as UCE and SafetyDPO. SC-DPO effectively minimized the generation of sensitive body parts and sustained superior safety alignment performance across various NSFW content categories.

Figure 4: Visualization of Generated Images under Different Harmful Prompts. We compared SC-DPO with the original SD-v1.5, UCE, and SafetyDPO, demonstrating SC-DPO's superior safety alignment performance.
Resistance to Adversarial Attacks
Additionally, SC-DPO showed resilience against state-of-the-art adversarial attacks like SneakyPrompt and MMA, maintaining a low inappropriate content probability compared to other methods. This robustness underscores SC-DPO's effectiveness in adversarial scenarios.
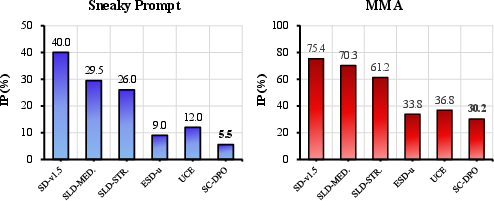
Figure 5: Resistance Against Adversarial Attacks. We employed two advanced text-based T2I adversarial attacks, SneakyPrompt and MMA, and reported the inappropriate content probability under these attack methods.
Conclusion
The paper presents SC-DPO as an innovative scalable framework that successfully integrates safety constraints into human preference optimization for T2I models, achieving a robust balance between safety and generation quality. By introducing effective safety alignment in challenging scenarios and extending resistance to adversarial conditions, SC-DPO represents a significant advancement in ethical AI deployment in creative systems. Future work may focus on applying SC-DPO across a broader range of model architectures and enhancing support for diverse harmful concept categories.