- The paper presents a tight global convergence analysis of a one-layer transformer's training with precise upper and lower bounds on the population loss.
- It demonstrates that the transformer’s attention mechanism effectively selects label-relevant variable groups, ensuring optimal variable selection and strong generalization.
- Empirical results validate the theoretical insights through experiments on synthetic data and CIFAR-10, showcasing efficient transfer learning and prediction accuracy.
This paper (2504.08638) presents a theoretical analysis of how a one-layer transformer learns a group-sparse classification problem using gradient descent. The authors demonstrate that the transformer can effectively leverage the attention mechanism to select relevant variables, ignoring irrelevant ones, and achieve good prediction accuracy with limited samples in downstream tasks. This study provides insights into how transformers learn structured data.
Problem Setup and Contributions
The authors consider a group-sparse classification problem where input variables are divided into multiple groups, and the label depends only on the variables from one group. They analyze a one-layer transformer trained by gradient descent on this data model.
The main contributions of this paper are:
- A tight global convergence analysis with matching lower and upper bounds for the population cross-entropy loss of a one-layer transformer trained by gradient descent (Theorem 3.1). The analysis characterizes the global optimization trajectories of all trainable parameters, revealing how each component of the transformer contributes to learning the group-sparse data model.
- A demonstration that a well pre-trained one-layer transformer on group-sparse inputs can be efficiently transferred to a downstream task sharing the same group sparsity pattern. The authors prove a generalization error bound for the fine-tuned transformer using online-SGD (Theorem 4.1).
- Empirical validation of the theoretical findings through numerical experiments. The experiments show that the training loss converges, and the attention score matrix exhibits sparsity, indicating effective variable selection. The transfer learning experiments also demonstrate good generalization performance with small sample sizes.
Model Architecture and Training
The authors use a one-layer self-attention transformer with modifications: they combine the query and key matrices into one trainable matrix $\Wb$, and replace the value matrix with one trainable value vector $\vb$. The training objective is to minimize the population cross-entropy loss using gradient descent with zero initialization.
Theoretical Results
The authors establish a tight global convergence analysis, showing that the self-attention mechanism extracts variables from the label-relevant group. They prove that the attention score for the label-relevant group approaches one with high probability. The first block of the value vector aligns with the ground truth, while the second block remains zero, indicating that positional encoding is only involved in calculating attention weights. The authors provide matching upper and lower bounds on the convergence rate of the population loss.
The paper also demonstrates that the pre-trained transformer can be efficiently transferred to a downstream task with a similar structure. The authors provide a generalization error bound for the downstream task, showing that the sample complexity surpasses that of linear logistic regression on vectorized features.
Implementation Details
The experimental setup involves generating synthetic data following a group sparse data distribution. The authors train the one-layer transformer model using gradient descent and monitor the training loss, cosine similarity between the value vector and the ground truth, and the norm ratio between different parts of the value vector. They also visualize the attention score matrix to verify the sparsity pattern. For downstream tasks, the authors fine-tune the pre-trained transformer on new Gaussian samples and evaluate the test accuracy.
Numerical Results
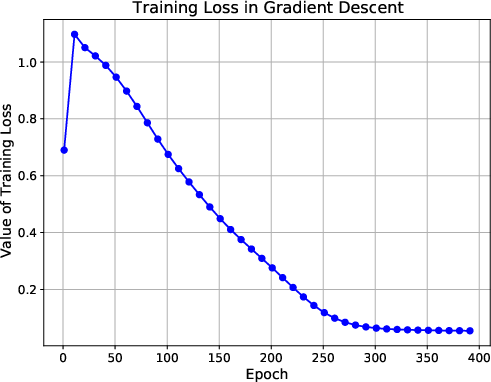
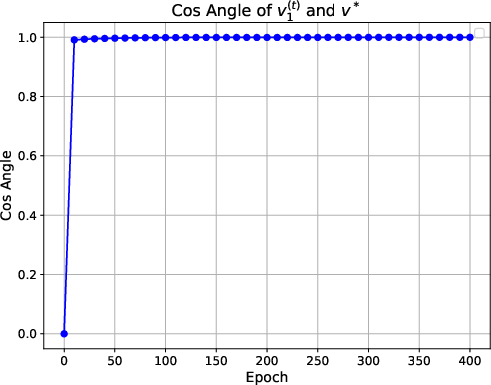
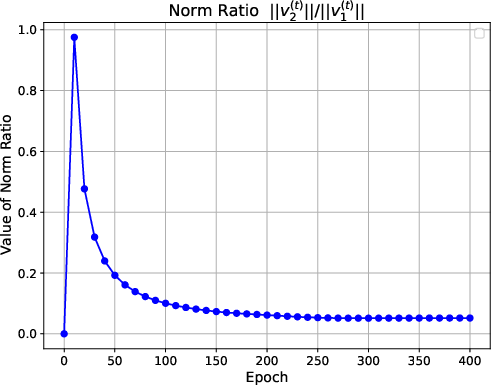
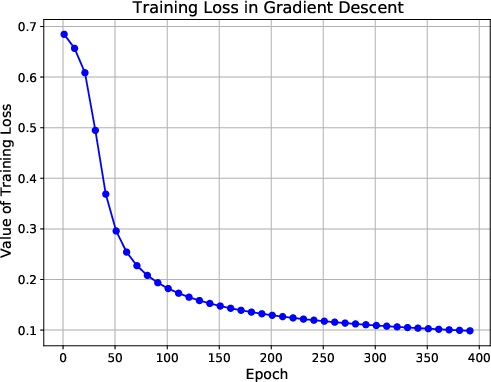
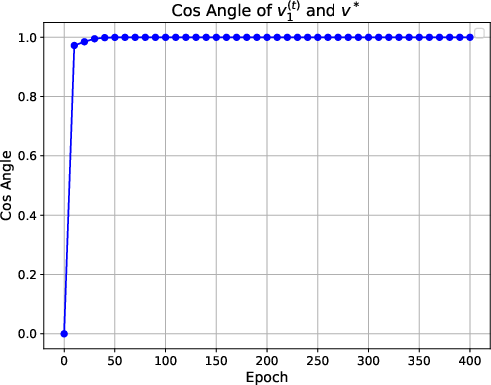
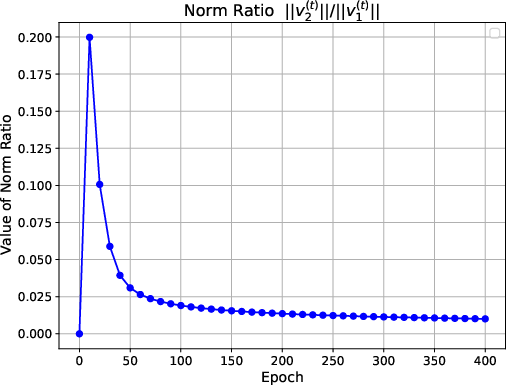
Figure 1: Figures on training loss, cosine similarity and norm ratio. The first line presents the training results with a sample size of 400, 6 variable groups, and a variable dimension of 4. The second line shows the training results for a sample size of 200, with 4 variable groups and a variable dimension of 2.
The numerical experiments show that the training loss converges to zero, and the value vector aligns with the ground truth direction. The attention matrix exhibits a clear sparsity pattern, with the attention focused on the label-relevant group (Figure 2). The transfer learning experiments demonstrate that the pre-trained transformer achieves good generalization performance on downstream tasks.
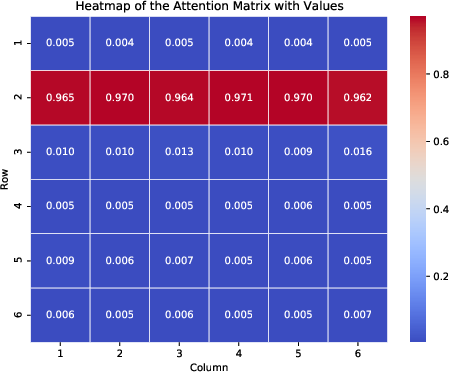
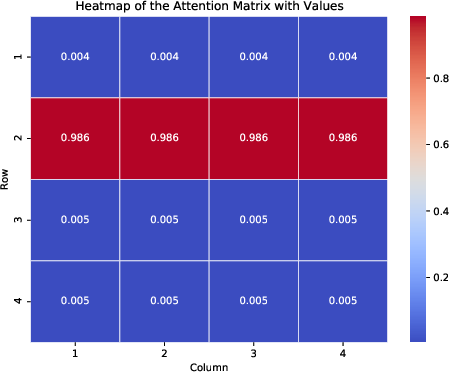
Figure 2: Heatmap of the average attention matrix. Figure~\ref{subfig:heat1} shows the heatmap of the attention matrix corresponding to the 6 variable groups, and Figure~\ref{subfig:heat2} shows the heatmap of the attention matrix corresponding to the 4 variable groups.
The authors also conduct experiments on the CIFAR-10 dataset. They embed each image as either the first or the 25th patch in a grid, while the remaining patches are filled with noise. The authors train a one-layer transformer to classify the embedded images. The results show that the model can effectively focus on the relevant patch and achieve strong generalization performance.
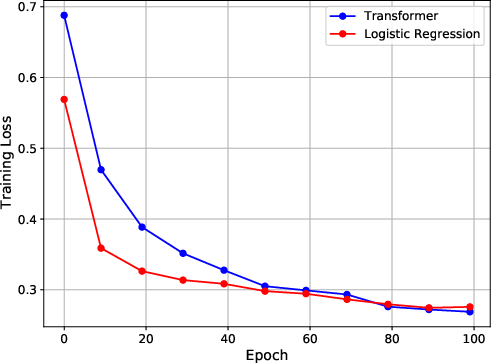
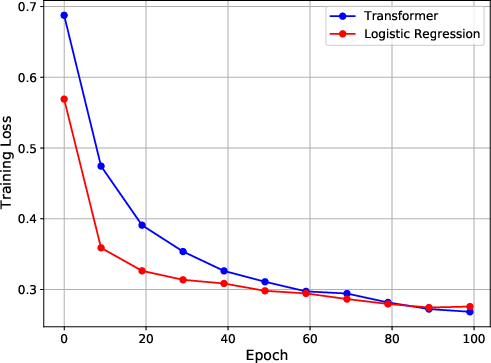

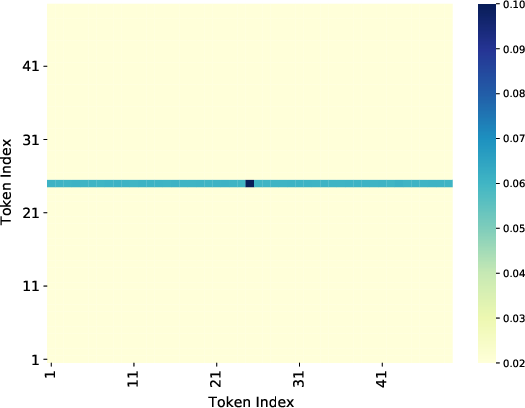
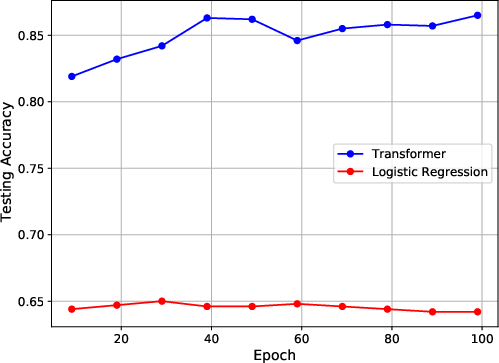
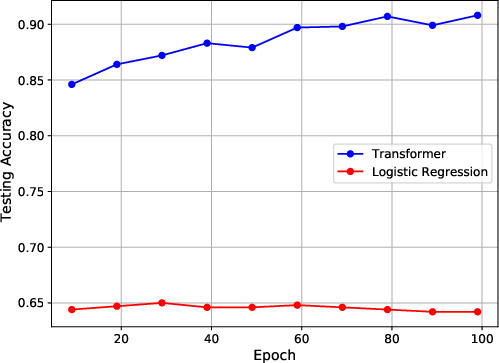
Figure 3: Experiment results on training loss, attention matrix and testing accuracy. The first column shows the results when images have position at (1,1). The second column shows the results when images have position at (4,4).
Conclusions
This paper provides a theoretical and empirical analysis of how transformers learn group-sparse data. The authors demonstrate that the one-layer transformer can effectively implement variable selection and achieve good generalization performance. The results shed light on the mechanisms of self-attention in variable selection and provide insights into the training dynamics of transformers. The authors point out that future research could investigate deeper transformer architectures and the integration of self-attention with other modules.