Can Diffusion Models Disentangle? A Theoretical Perspective
Published 31 Mar 2025 in cs.LG, cs.AI, and cs.CV | (2504.00220v2)
Abstract: This paper presents a novel theoretical framework for understanding how diffusion models can learn disentangled representations. Within this framework, we establish identifiability conditions for general disentangled latent variable models, analyze training dynamics, and derive sample complexity bounds for disentangled latent subspace models. To validate our theory, we conduct disentanglement experiments across diverse tasks and modalities, including subspace recovery in latent subspace Gaussian mixture models, image colorization, image denoising, and voice conversion for speech classification. Additionally, our experiments show that training strategies inspired by our theory, such as style guidance regularization, consistently enhance disentanglement performance.
The paper establishes sufficient conditions using a regularized score-matching objective to recover approximately disentangled latent representations.
It quantifies disentanglement via mutual information metrics and shows that content-style leakage is inevitable without explicit regularization.
Empirical validations on datasets like MNIST and CIFAR-10 corroborate the theoretical predictions, demonstrating improved editability and robustness.
Theoretical Analysis of Disentanglement in Diffusion Models
Introduction
This work provides a formal learning-theoretic perspective on the disentanglement capabilities of diffusion models (DMs), specifically in the context of content and style latent variable models under weak supervision. The analysis rigorously addresses the fundamental challenges imposed by stochastic, non-invertible generative processes and characterizes precise identifiability and recovery guarantees. The framework allows for both information-theoretic and practical editability metrics, and emphasizes finite-sample results in idealized and realistic settings.
Problem Formalization and Approaches
The core task is to recover disentangled representations of content and style latent factors from observed data when the generative map is stochastic and not analytically invertible—a fundamentally different regime than classical (V)AE or ICA results. The observable is defined as
X=1−δ2f(Z,G)+δN,
with Z and G independent, N standard Gaussian, and f (possibly nonlinear and invertible). Notions of (ϵ,ν)-disentanglement are established using mutual information to quantify: (1) near-independence between learned representations, and (2) retention of information about the observation. Editability is defined by conditional generation; the ability to modify style while preserving content. It is proven that these two properties are non-equivalent, and that mutual information criteria alone do not guarantee practical editability.
Two realistic supervision scenarios are considered:
Content disentanglement: The style function is known and content must be learned.
Multi-view disentanglement: Multiple views share content with independent styles, possibly with view-specific generative maps.
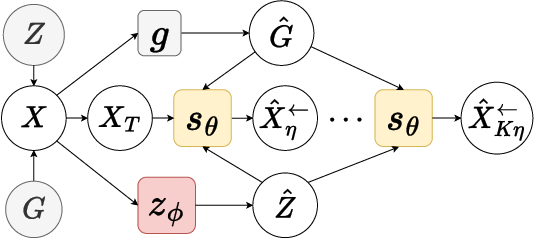
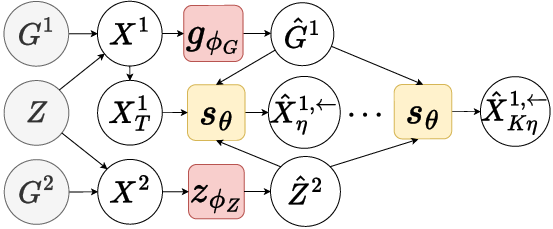
Figure 1: Graphical models for content disentanglement (left: known style encoder, learned content encoder and score estimation) and multi-view disentanglement (right: two views with shared content and view-specific style encodings; conditioning enables cross-view disentanglement).
Key technical assumptions imposed for tractability include: sub-Gaussian data, Lipschitz score functions, and realizability of encoders.
Main Theoretical Results
The first principal result is the derivation of sufficient conditions under which a conditional DM, trained with a regularized score-matching objective, recovers approximately disentangled representations. Notably:
Under mild regularity and noise δ→0, DMs can achieve (ϵ,ν)-disentanglement with ϵ,ν→0. The convergence rate depends on the score function's Lipschitz constant and the latent dimension.
Using weak supervision, such as multi-view alignment or partial labels for style, is sufficient to guarantee practical disentanglement under the model.
Mutual information constraints as regularization are necessary: without explicit regularization, content-style leakage is inevitable due to the non-invertibility and stochasticity of DM transitions.
In the multi-view setting, disentanglement and editability are both theoretically achievable, and the error bounds depend on the intrinsic noise level, Lipschitz constants of the encoders and generative function, and statistical dependencies in the latent factors. The role of regularizers is made explicit: they prevent leakage of content into the style representation, enabling reliable mix-and-match generation.
A strong finite-sample recovery result is established for independent subspace models (ISM): with orthogonally mixed, independent Gaussian subspaces for content and style, score-based models with dual-encoder architectures globally recover the correct subspaces as the number of samples grows, provided sufficient style-guidance regularization is included.
Figure 2: Dual-encoder architecture for ISM: separate networks encode content and style, whose scores are linearly combined and regularized to ensure subspace disentanglement.
Empirical Validation
Experiments on synthetic and real datasets corroborate the theory. On latent subspace GMMs, DMs robustly recover disjoint latent subspaces, with reduced recovery error as the style guidance weight or sample size increases. This supports the predicted convergence rates.
On MNIST (colorization: content = shape, style = color) and CIFAR-10 (denoising: content = clean image, style = noise), ablation studies reveal that, without regularization, the model copies inputs, failing to disentangle. Applying the style-guidance regularizer recovers interpretable, fully editable factors as predicted.
Figure 3: (Top) MNIST colorization: input, baseline result (no disentanglement), regularized colorization (successful disentanglement), and reference. (Bottom) CIFAR10 denoising: input, baseline, regularized denoising, and reference.
On speech (voice conversion for robust classification tasks), disentanglement improves emotion recognition and impairment detection across unseen speakers, with the effect magnified when using multi-speaker augmentation—consistent with the multi-view theory.
Implications and Future Directions
Practical Impact
This work establishes that, unlike classical deterministic approaches, DMs can provably learn editable, disentangled latent factors from non-invertible, stochastic processes under practical weak supervision. The framework applies to controlled generation, robust perception under distribution shift (e.g., in speech or vision), and creative editing tools. The explicit characterization of regularization and sample complexity is highly relevant for design of next-generation generative architectures in multimodal and real-world systems.
Theoretical Impact
The paper corrects misconceptions about the identifiability limitations of unsupervised disentanglement in highly non-invertible, stochastic generative settings. It generalizes results from nonlinear-ICA, causality, and SSL to diffusion models, augmenting the understanding of the fundamental limits and robustness required for practical disentanglement.
Speculative Directions
Extension to more complex latent variable structures, including hierarchical, causal, or group-theoretic factors.
Integration of pre-trained foundation models as encoders within the theoretical framework, enabling scalable application to high-dimensional modalities.
Adaptive or data-dependent regularization, possibly guided by downstream performance rather than purely information-theoretic criteria.
Stronger finite-sample analysis under non-idealized data regimes.
Conclusion
This work provides a rigorous theoretical and practical foundation for disentanglement with diffusion models. By precisely analyzing the regimes in which content-style factors can be identified and manipulated, it both clarifies the fundamental limitations and guides practitioners towards robust, editable generative systems. Further, the demonstrated framework and empirical results delineate a roadmap for extending DM-based disentanglement to more complex latent structures and applications.
Reference: "Can Diffusion Models Disentangle? A Theoretical Perspective" (2504.00220)
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.