- The paper demonstrates that GPT-4.5-PERSONA achieved a 73% win rate, clearly outperforming human witnesses in a three-party Turing test.
- The experimental design used controlled settings with minimal and persona prompts to highlight the significance of prompt engineering in LLM performance.
- The findings raise important questions regarding AI deception, trust in online communication, and the societal implications of advanced conversational models.
LLMs Triumph in the Three-Party Turing Test
The paper "LLMs Pass the Turing Test" (2503.23674) presents empirical evidence demonstrating that contemporary LLMs, specifically GPT-4.5 and LLaMa-3.1-405B, can successfully imitate human conversation in a standard three-party Turing test. This research marks a significant milestone in the field of AI, raising crucial questions about the nature of intelligence and the potential societal impact of increasingly sophisticated LLMs.
Experimental Design and Methodology
The study employed a randomized, controlled experimental design involving human interrogators interacting simultaneously with a human witness and an AI system. The interrogators' task was to identify which of the two witnesses was human based on a five-minute text-based conversation. The AI systems evaluated included GPT-4.5, LLaMa-3.1-405B, GPT-4o, and ELIZA, with the first three being LLMs and the last being a rule-based chatbot used as a baseline. The LLMs were tested with two types of prompts: a minimal instruction prompt ({NO-PERSONA}) and a prompt that encouraged the model to adopt a specific human-like persona ({PERSONA}). The experiments were conducted on two independent populations: undergraduate students and Prolific workers, ensuring robustness and generalizability of the results. An example of the {PERSONA} prompt can be seen below.

Figure 1: The full {PERSONA} prompt used to instruct the LLM-based AI agents how to respond to interrogator messages in the Prolific study.
The experimental setup was designed to mirror a conventional messaging application (Figure 2), providing a naturalistic and engaging environment for the participants. This setup allowed for a direct comparison between human and AI conversational abilities under ecologically valid conditions.
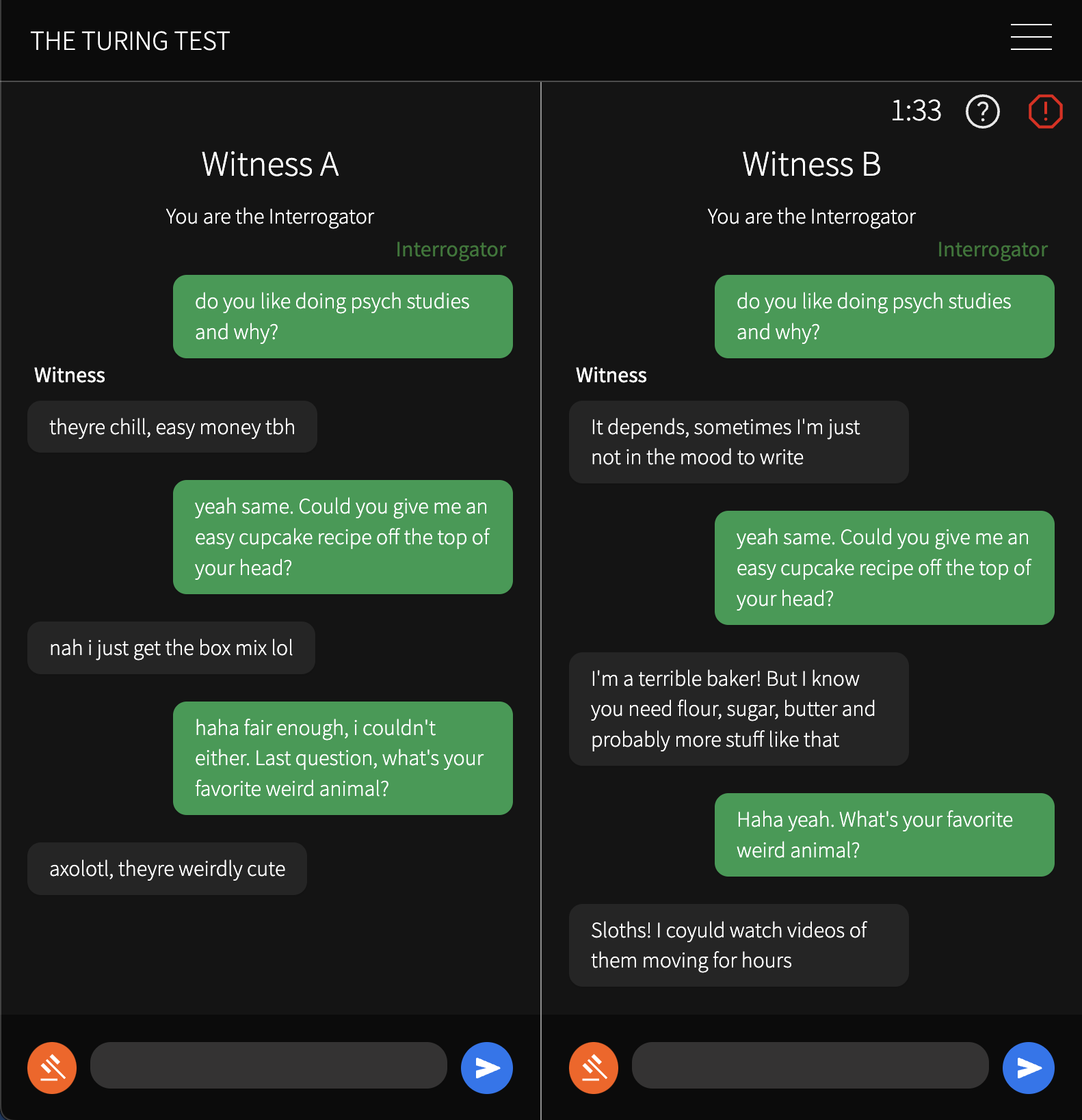
Figure 2: Turing test game interface containing an in-progress conversation between an interrogator (green) and two witnesses (grey). The timer at the top shows time remaining in the game.
Key Results and Statistical Analysis
The study's primary metric was the "win rate," defined as the proportion of times the interrogator identified the AI system as human. The results revealed that {GPT-4.5-PERSONA} achieved a win rate of 73% across both studies, significantly outperforming the human witnesses. {LLAMA-PERSONA} also demonstrated a high win rate of 56%. In contrast, the baseline models, {GPT-4o-NO-PERSONA} and {ELIZA}, had significantly lower win rates of 21% and 23%, respectively.
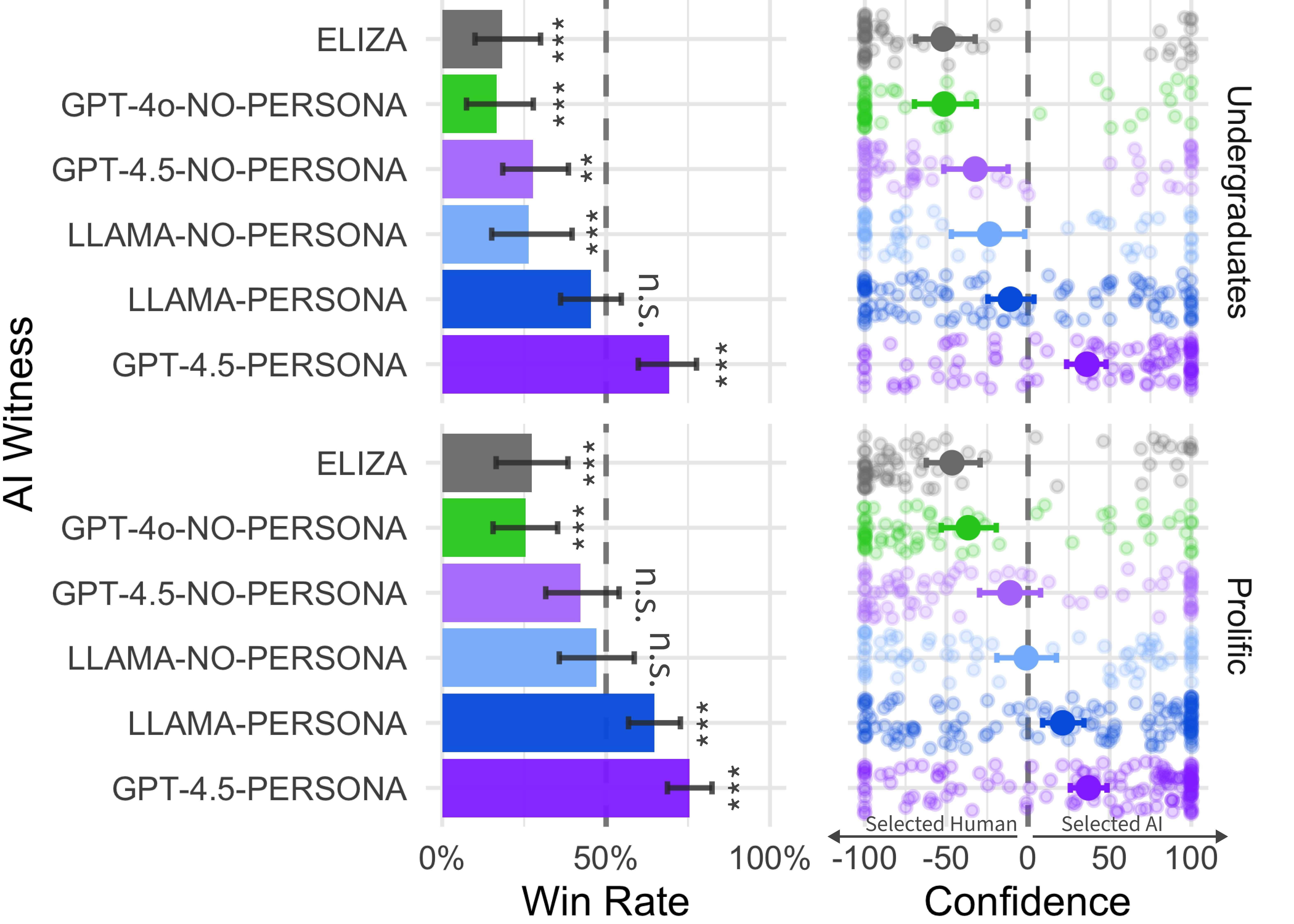
Figure 3: Win rates for each AI witness, demonstrating superior performance of {GPT-4.5-PERSONA}.
Statistical analyses confirmed that the win rates of {GPT-4.5-PERSONA} were significantly above chance, indicating that interrogators were not only unable to distinguish the model from humans but were also more likely to believe the model was human. The win rates for ELIZA were significantly below chance, confirming that interrogators were able to distinguish humans from this simple AI system. Further analyses showed that models with the {PERSONA} prompt performed significantly better than those without, highlighting the importance of prompting in achieving human-like conversational abilities.
Interrogator Strategies and Reasoning
To gain insights into how interrogators were evaluating the witnesses, the study analyzed the strategies employed and the reasons given for their verdicts. The most common strategy was engaging in small talk (61% of games), followed by probing social and emotional qualities (50%). Interestingly, interrogators were most accurate when they used unusual or "jailbreak" tactics, suggesting that these methods were effective in exposing the limitations of the AI systems.
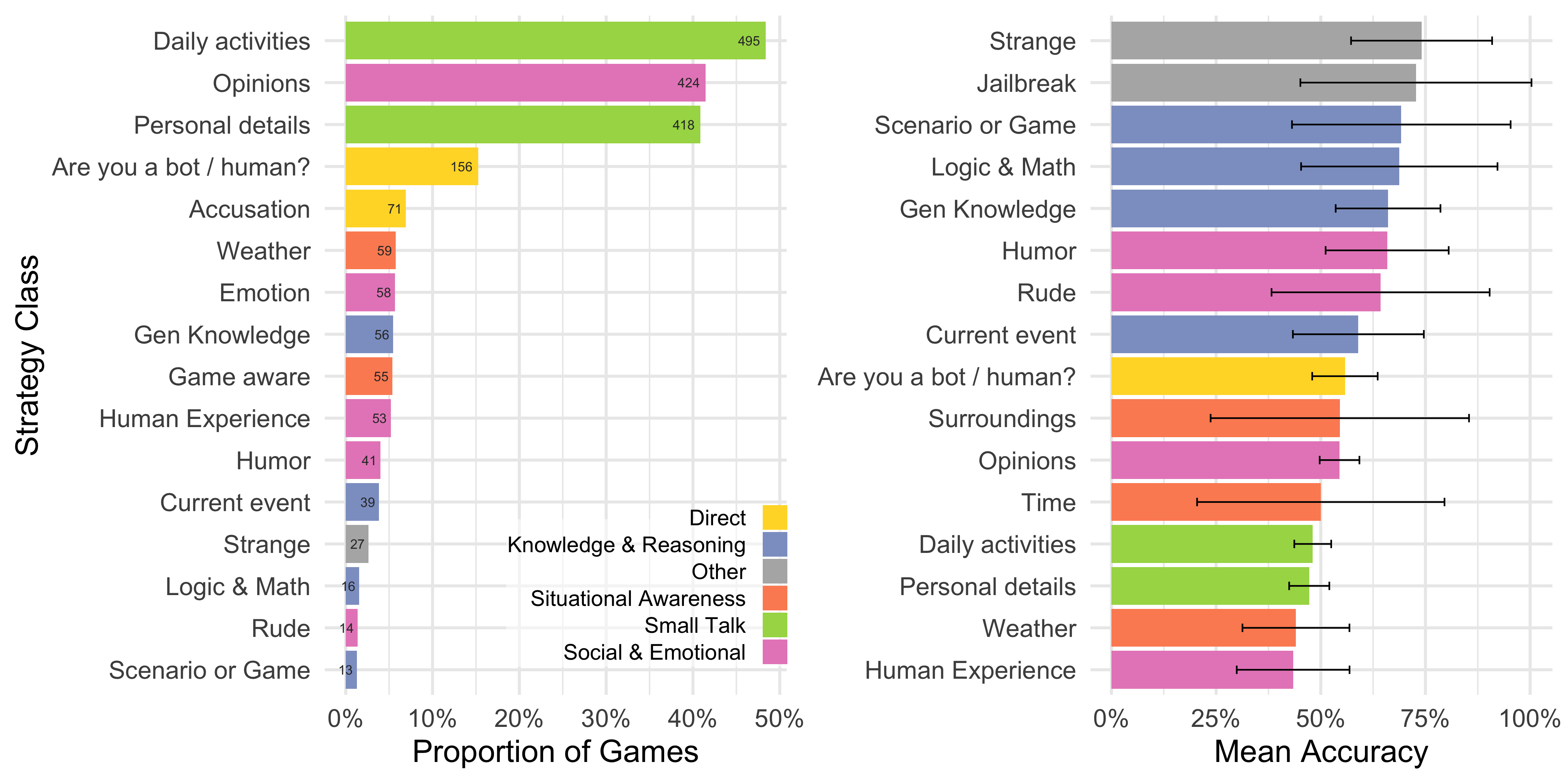
Figure 4: Classification of strategies employed by interrogators, revealing the prevalence of small talk and probing social-emotional qualities.
The analysis of reasons provided by interrogators revealed that linguistic style and interactional dynamics were the most frequently cited factors, while knowledge and reasoning were less emphasized. This suggests that interrogators were more attuned to the social and emotional aspects of conversation than to traditional measures of intelligence. Furthermore, the most accurate verdicts focused on question handling and instances where witnesses lacked knowledge, highlighting the complexity of the Turing test for modern LLMs, which must appear to feign ignorance on certain topics.
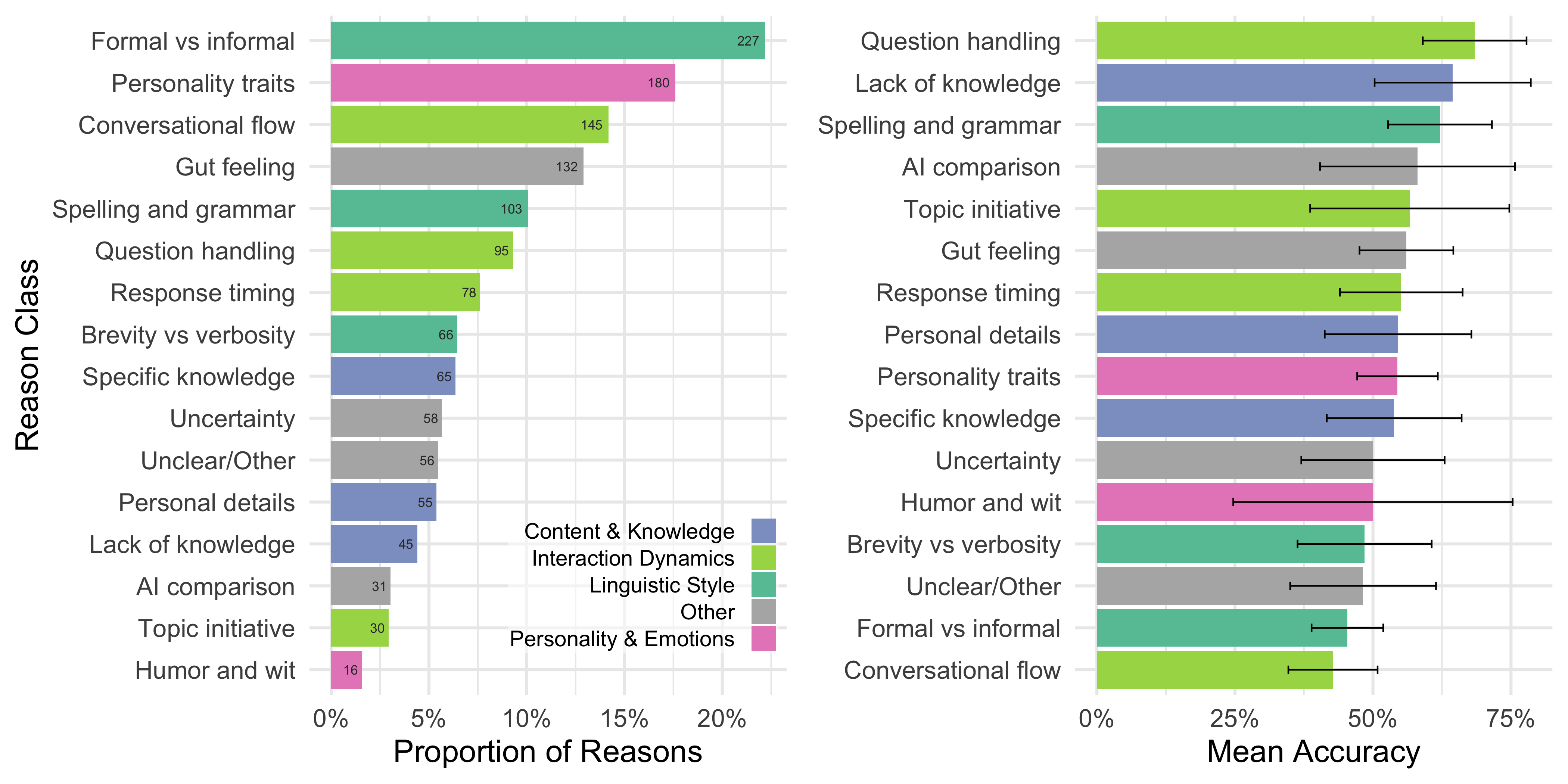
Figure 5: Proportion of interrogator reasons and mean accuracy of verdicts, indicating the importance of linguistic style and conversational flow.
Implications and Future Directions
The finding that contemporary LLMs can pass the Turing test has significant implications for debates about the nature of intelligence and the potential societal impacts of AI. The study demonstrates that these systems can successfully imitate human conversation to the point of being indistinguishable from real people, raising concerns about the potential for deception, social engineering, and the erosion of trust in online interactions. One can see in the example conversations in (Figure 6) how difficult it can be to identify the AI in practice.
Figure 6: Four example games illustrating the challenges interrogators faced in distinguishing between human and AI witnesses.
The study also highlights the importance of prompting in achieving human-like conversational abilities, suggesting that the system's behavior is not solely attributable to the model itself but also to the humans who craft the prompts. This raises questions about the extent to which LLMs can be considered truly intelligent or merely sophisticated imitators.
Future research should explore alternative implementations of the Turing test, such as longer tests or the use of expert interrogators, to further challenge the capabilities of LLMs. Additionally, investigations into the impact of common ground and shared assumptions on the ability to distinguish humans from AI could provide valuable insights. Understanding how to detect deception by AI systems and developing effective mitigation strategies are also crucial areas for future research.
Conclusion
The paper "LLMs Pass the Turing Test" (2503.23674) provides compelling empirical evidence that contemporary LLMs can successfully imitate human conversation in a standard three-party Turing test. This finding has significant implications for debates about the nature of intelligence, the potential societal impacts of AI, and the ongoing quest to develop more robust and reliable methods for evaluating AI systems. As machines become increasingly similar to humans, it is essential to understand the nuances of human-like behavior and to develop strategies for ensuring that AI technologies are used responsibly and ethically.