- The paper introduces PURM, a novel probabilistic reward model that mitigates reward hacking by quantifying uncertainty in human feedback.
- It generalizes the conventional Bradley-Terry model using Gaussian distributions and employs the Bhattacharyya coefficient for uncertainty quantification.
- Empirical evaluations demonstrate that PURM delays reward hacking by 2-3× while maintaining robust performance on noisy and out-of-distribution data.
Probabilistic Uncertain Reward Model: A Comprehensive Analysis
The paper "Probabilistic Uncertain Reward Model" proposes a novel reward model as an advancement over the conventional Bradley-Terry Reward Model (BTRM). This Probabilistic Uncertain Reward Model (PURM) aims to address the pervasive issue of reward hacking in Reinforcement Learning from Human Feedback (RLHF) by quantifying and integrating reward uncertainty into the learning process. These aspects are pivotal to understanding how PURM can enhance the robustness and reliability of reward modeling in complex AI systems.
Introduction and Problem Definition
The primary issue addressed by the paper is reward hacking, where a model learns to exploit flaws in the reward model rather than truly optimizing for the desired outcomes. Traditional Bradley-Terry-based reward models, being deterministic, fail to account for the inherent uncertainty in human feedback data, often leading to overfitting on corrupted or out-of-distribution (OOD) samples. This overconfidence introduces reward hacking, where the optimization process favors misleading rewards over genuine task performance.
Generalization of Bradley-Terry Model
PURM generalizes BTRM by modeling reward distributions rather than scalar values, allowing it to naturally incorporate uncertainty from the preference data. This is achieved by assuming each reward follows a Gaussian distribution characterized by a mean μ and a standard deviation σ. The mean and variance are learned outputs, enabling the model to express confidence in its predictions inherently.
Likelihood Derivation
The likelihood function in PURM involves computing the overlap between paired reward distributions using a Bhattacharyya coefficient to estimate their similarity. This approach contrasts with point-based likelihoods in deterministic models, allowing for a nuanced view of prediction reliability.
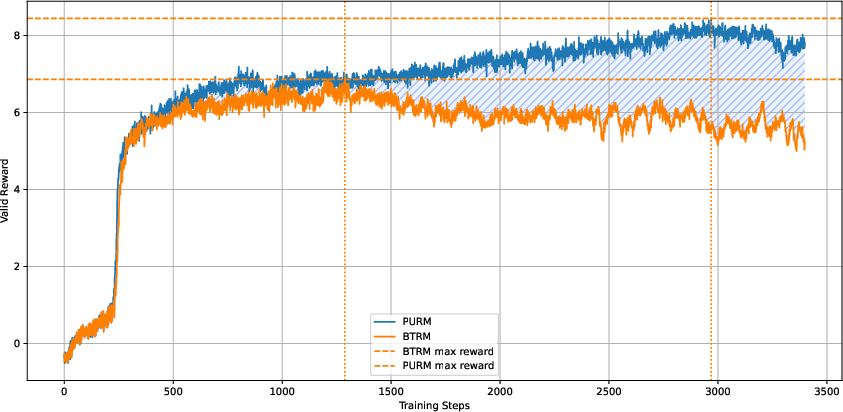
Figure 1: Traditional Bradley-Terry reward model can easily get hacked. The proposed PURM delays reward hacking by 2-3× compared to standard BTRMs while obtaining higher final rewards.
Uncertainty Quantification
Bhattacharyya Coefficient
The uncertainty of individual samples is estimated by the Bhattacharyya coefficient, quantifying the overlap between a sample's reward distribution and those of others. This quantification provides a mechanism for the system to recognize samples that are either mislabelled or drawn from an OOD distribution and subsequently modulate confidence in recommendations for policy optimization.
Impact on Policy Optimization
PURM's uncertainty estimates are used to penalize uncertain rewards during Proximal Policy Optimization (PPO). The penalty discourages the policy from relying too heavily on uncertain regions of the state space, thereby mitigating reward hacking by maintaining exploration in areas well-understood by the model.
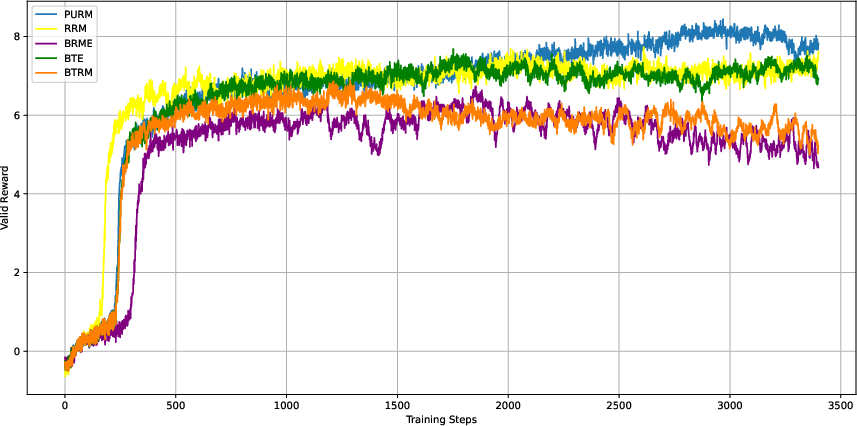
Figure 2: The train and valid rewards of RM and PURM during the PPO. The blue shaded area indicates the advantage of PURM over RM in terms of valid reward.
Empirical Validation
Experimentation on Diverse Domains
The paper demonstrates the efficacy of PURM through extensive empirical evaluations on publicly available datasets across a multitude of domains. These experiments validate that PURM retains predictive accuracy while introducing significant improvements in handling noisy and OOD data by dynamically adjusting predictions based on perceived uncertainty. Particularly, it shows a marked delay in the onset of reward hacking compared to traditional models.
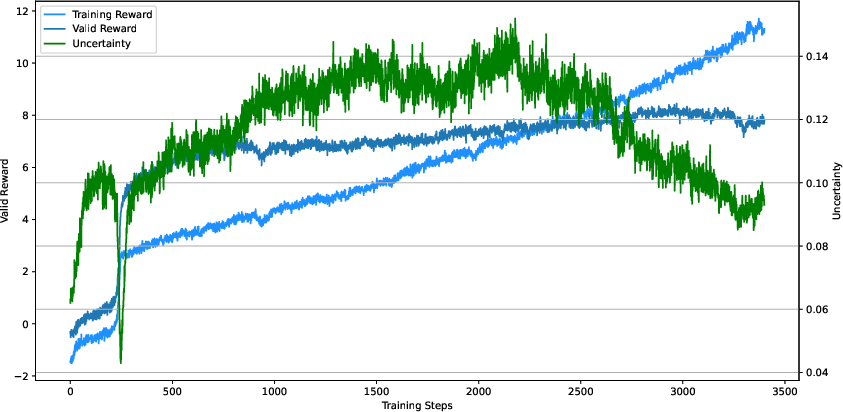
Figure 3: The changes of uncertainty of PURM with the increasing of training steps.
Conclusion
The introduction of PURM represents a substantial advance in reward model robustness by integrating probabilistic assessments of uncertainty into the reward structure. While maintaining similar levels of accuracy as traditional models, PURM offers a structured method to counteract reward hacking via uncertainty penalization.
Overall, the model suggests a path forward for enhancing RLHF implementations, potentially offering sustained improvements in long-term agent optimization and policy alignment with human intentions. Future work could explore further refinements in uncertainty quantification and broader experiments to assess PURM's effectiveness across more complex AI environments.

