- The paper introduces a multimodal diffusion framework that leverages depth, segmentation, and text inputs to enhance single image super-resolution by enriching spatial context.
- It employs a Multimodal Latent Connector to distill essential token sequences, reducing computational complexity while preserving fine-grained details.
- Extensive evaluations using metrics like LPIPS and FID demonstrate improved perceptual quality and offer refined control over image enhancement.
The Power of Context: How Multimodality Improves Image Super-Resolution
Introduction
The paper "The Power of Context: How Multimodality Improves Image Super-Resolution" discusses an advanced approach to Single Image Super-Resolution (SISR) leveraging multimodal inputs to enhance visual quality. Traditional SISR techniques rely heavily on limited image priors, resulting in inferior performance when compared to recent generative models. By employing multiple modalities such as depth maps, semantic segmentation, edges, and text prompts, the study proposes a novel diffusion model framework for SISR that surpasses existing state-of-the-art methods.
Multimodal Diffusion Model Architecture
The proposed architecture incorporates auxiliary modalities in conjunction with low-resolution images to improve super-resolution results. The utilization of diverse modalities reduces uncertainty and improves fidelity by enriching the generative prior with valuable spatial and contextual information.
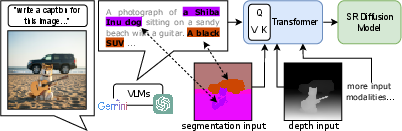
Figure 1: LLMs struggle to accurately represent spatial information, leading to coarse and imprecise image super-resolution. To overcome this limitation, we incorporate additional spatial modalities like depth maps and semantic segmentation maps. These modalities provide detailed spatial context, allowing our model to implicitly align language descriptions with individual pixels through a transformer network. This enriched understanding of the image significantly enhances the realism of our super-resolution results and minimizes distortion.
The model employs a diffusion network for effectively handling multiple modalities, achieving superior image reconstruction by encoding tokens from each modality and transforming them into a comprehensive multimodal representation. A key design feature is the Multimodal Latent Connector (MMLC), which reduces computational complexity by distilling essential information into manageable token sequences.
Training and Implementation
Training leverages pretrained diffusion models, employing large-scale datasets to ensure robust performance. The model operates efficiently by sampling from a multimodal token sequence, refining super-resolution outputs through multimodal classifier-free guidance. This guidance enables dynamic adjustments, significantly enhancing perceptual quality and minimizing hallucinations present in high guidance scales.
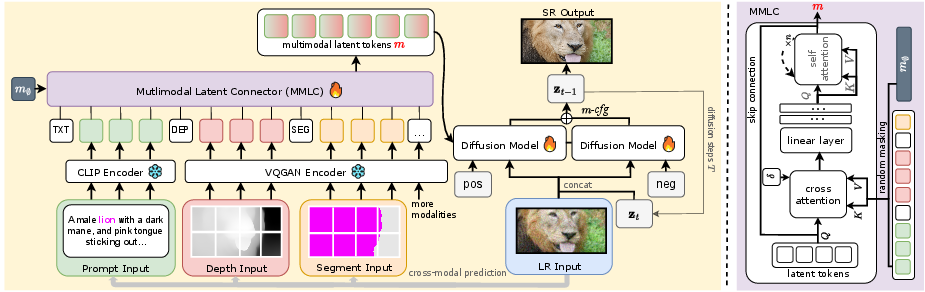
Figure 2: This diagram illustrates our multimodal super-resolution pipeline. Starting with a low-resolution (LR) image, we extract modalities like depth and semantic segmentation maps. These modalities are encoded into tokens and transformed into multimodal latent tokens (m). Our diffusion model uses these tokens and the LR input to generate a high-resolution (SR) output. A multimodal classifier-free guidance (m-cfg) refines the SR image for enhanced quality.
Extensive evaluations against multiple datasets demonstrate the model’s superiority in generating high-quality super-resolved images. Key metrics such as LPIPS, DISTS, NIQE, and FID highlight the model's strong alignment with perceptual quality. Compared to leading approaches like SeeSR and PASD, the method exhibits enhanced realism and preservation of fine-grained details.
(Figures 4-6)
Figure 3 and 5: MMSR super-resolution results on real-world images compared with state-of-the-art methods. Zoom in to appreciate the details.
Figure 4: Visual results when (not) using the MMLC module.
Controllability and Applications
The method provides unprecedented control over the super-resolution process through adjustable influence of each modality. This capability allows tailored image enhancements, such as depth-of-field effects and edge sharpness refinement, catering to varying application requirements and improving the versatility of the super-resolution task.

Figure 5: Our method allows for fine-grained control over super-resolution results by adjusting the influence of each input modality. For example, reducing the edge temperature enhances edge sharpness (first row). Lowering the segmentation temperature emphasizes distinct features, such as the star pattern on the flag (second row). Decreasing the depth temperature accentuates depth-of-field effects, like the bokeh between the foreground and background (third row). In contrast, PASD exhibits limited control over such fine-grained details.
Conclusion
By leveraging the rich contextual capacity of multimodal inputs, the proposed framework significantly enhances the SISR pipeline. The introduction of modalities such as depth and semantic segmentations provides essential spatial context, substantially lifting the performance ceiling imposed by traditional methods. Future research aims to improve the speed of inference and explore advanced mechanisms for modality-specific information extraction, further optimizing the robustness and applicability of multimodal SISR techniques.