- The paper establishes a novel benchmark (KT) to assess CodeLMs by measuring their ability to compress data using generated code.
- It rigorously evaluates models on both natural and synthetic sequences using a domain-specific language and varied experimental setups.
- Empirical findings reveal that current models struggle with natural data compression, highlighting the need for advancements in reasoning and pattern recognition.
The KoLMogorov Test: A Benchmark for Compression by Code Generation
The paper "The KoLMogorov Test: Compression by Code Generation" (2503.13992) introduces the KoLMogorov-Test (KT), a novel benchmark aimed at measuring the reasoning capabilities of Code Generation LLMs (CodeLMs) by testing their ability to compress data sequences through code generation. The research highlights the intersection of compression methods with artificial intelligence and evaluates the proficiency of current models in producing concise programs that replicate given data sequences.
Introduction and Background
The concept of compression is fundamentally linked to intelligence, encapsulated by Kolmogorov complexity, which is defined as the length of the shortest program that can produce a given sequence. This theoretically optimal compression technique is uncomputable due to its relation to the halting problem. Current code-generating models like GPT4-o and Llama-3.1 exhibit limitations in approaching this ideal; they lack enhanced reasoning, planning, and search capabilities.
Algorithmic Information Theory and Compression: The paper outlines how generative models can be analogous to compression algorithms, where maximizing likelihood corresponds to maximizing compression. The theoretical framework involves the use of universal priors and likelihoods related to the sequence output, paralleling Solomonoff's theory of inductive inference.
Experimental Setup
The KoLMogorov-Test evaluates the ability of CodeLMs to generate programs that reproduce sequences efficiently, using both naturally occurring and synthetic sequence data.
Data Modalities: The test utilizes audio, text, and DNA data sequences. For synthetic sequences, a domain-specific language (DSL) facilitates the generation of program-sequence pairs, each representing logical, composed sub-sequences.

Figure 1: Our main experimental settings.
Modeling and Benchmarks: Models are tasked with producing the shortest executable programs. The evaluation metrics include accuracy, compression rates relative to Gzip baselines, and precision related to program size versus direct sequence compression. The test benefits from an essentially infinite number of problem instances of varying difficulty, providing robust evaluation ground.
Main Findings
The results reveal that current models struggle with the KT, especially on natural data.
Performance on Natural Data: Flagship models like Llama-3.1-405B and GPT4-o perform suboptimally on natural sequences, indicating the challenge KT poses to existing architectures. Prominent models err at high rates, indicating a need for further advancements.
Synthetic Data Achievements: Models trained specifically on synthetic datasets exhibit significant improvements in achieving lower compression rates, outperforming established methods like Gzip under controlled conditions.
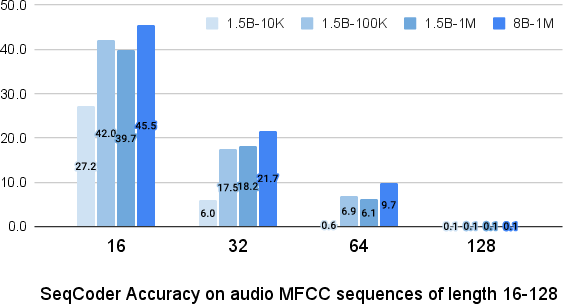
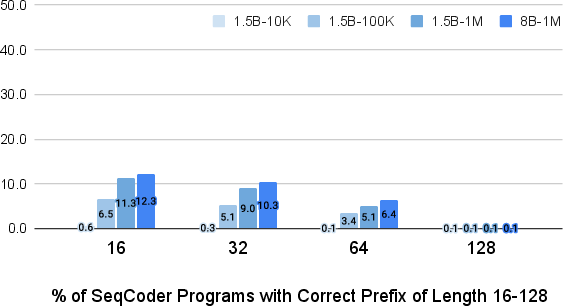
Figure 2: Accuracy for our SeqCoder-1.5B on Audio MFCC sequences of lengths 16-128. Models trained on more examples are significantly better on short sequences, but all models struggle on longer ones.
Error Analysis: An analysis of model errors showed a propensity for repetition and failure in symbolic reasoning, particularly evident in incorrect execution of logical patterns.
Implications and Future Directions
The KoLMogorov-Test serves as a formidable benchmark, highlighting areas where current models lack capabilities in reasoning and efficient pattern recognition. It underscores the potential for CodeLMs to act as more accurate world models, paving the way for innovations in telecommunication efficiencies and cross-modal data handling.
Future Research Directions: Advancements in RL-based training, exploration of alternate data modalities, and increased focus on longer sequence processing are potential areas for future exploration. Innovations in synthetic data tailoring and strong domain adaptation techniques could alleviate current limitations.
Practical Implications: The work suggests the transformative impact refined CodeLMs could have on data industries, especially in tasks involving data transmission and storage. Although theoretical breakthroughs are required for substantial real-world applications, the KT establishes a solid foundation for future model evaluations.
Conclusion
The KoLMogorov-Test provides critical insights into the limitations and potential of current code generation models concerning data compression through programmatic synthesis. The benchmark establishes a new standard for evaluating model reasoning capabilities, offering a challenging test-bed that can drive progress in artificial intelligence and data compression methodologies. As CodeLMs evolve, meeting the KT's demands may lead to groundbreaking changes in how models interact with complex data across varied domains.

