- The paper introduces Dynamic Tanh (DyT) as an effective alternative to normalization layers in Transformers, achieving comparable performance.
- It validates the approach with extensive experiments in computer vision and language modeling, showing similar training dynamics to standard normalization methods.
- Replacing normalization layers with DyT simplifies architectural design and may accelerate training and inference while maintaining accuracy.
Overview
The paper "Transformers without Normalization" (2503.10622) introduces a novel approach to eliminating normalization layers in Transformers by employing a simple technique referred to as Dynamic Tanh (DyT). The significance of normalization layers, particularly Layer Normalization (LN), in stabilizing training and improving convergence is well-documented. However, this study demonstrates the feasibility of using DyT as an alternative to normalization layers, without a loss in performance, across various Transformer-based architectures.
Dynamic Tanh: Concept and Implementation
Dynamic Tanh (DyT) is inspired by the observation that Layer Norm often exhibits tanh-like input-output mappings. By substituting the normalization layers with DyT, defined as DyT()=tanh(α) where α is a learnable parameter, Transformers maintain impressive performance levels without the need for complex statistical computations typically associated with normalization layers. The DyT operation squashes the output into a bounded range and adjusts the input's scale adaptively through α. This approach aligns closely with the linear transformation tendencies of LN layers (Figure 1).
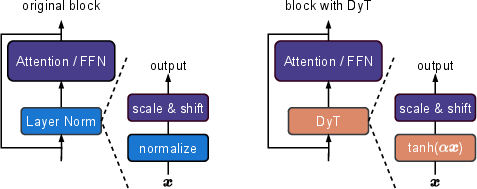
Figure 1: Left: original Transformer block. Right: block with our proposed Dynamic Tanh (DyT) layer.
Analysis of Normalization Behavior
The analysis of normalization layers in Vision Transformer (ViT) models and other Transformer architectures like wav2vec 2.0 reveals that deeper normalization layers induce an S-shaped curve, similar to tanh functions when plotting input vs. output relationships (Figure 2). This non-linearity is intrinsic to the function of normalization layers, contributing significantly to the representation capacity of neural networks.
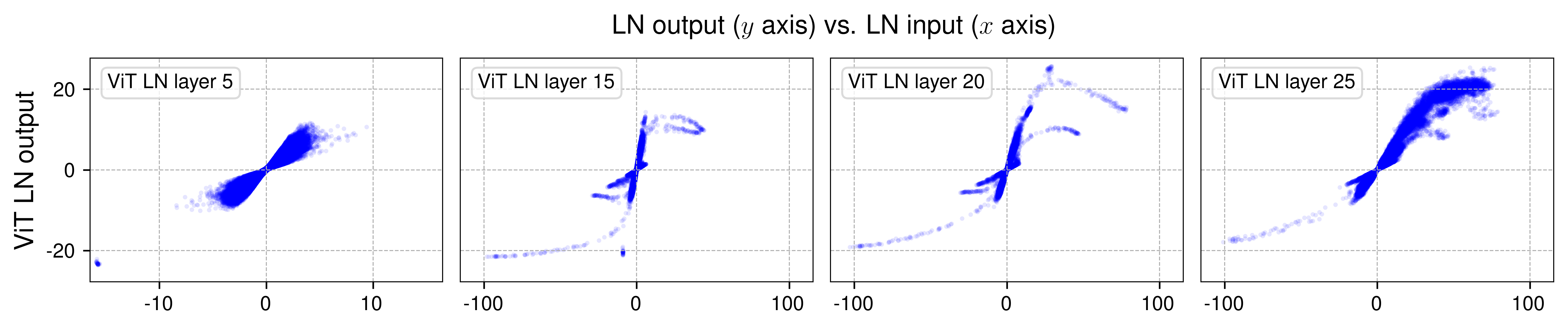

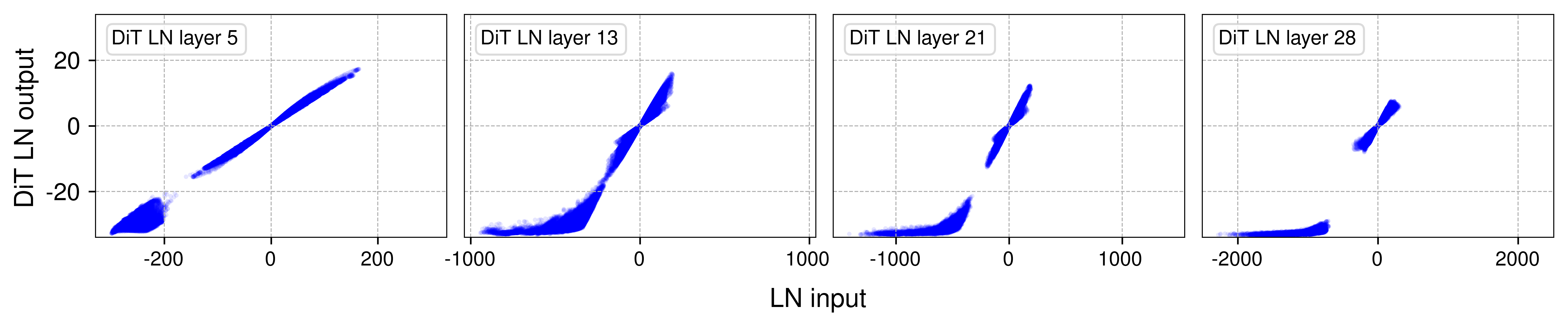
Figure 2: Output vs. input of selected layer normalization (LN) layers in Vision Transformer (ViT) and wav2vec 2.0.
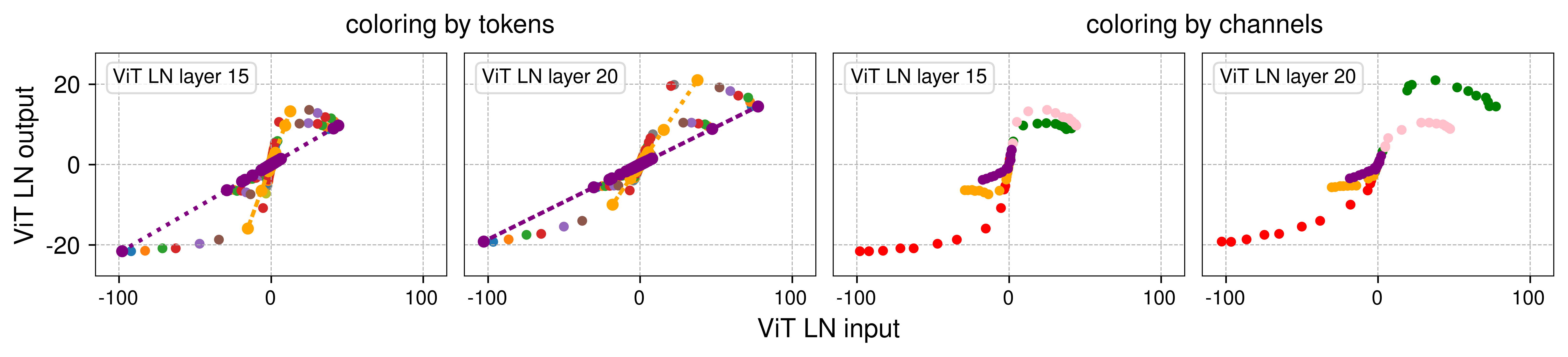
Figure 3: Output vs. input of two LN layers, highlighting the linear behaviour by tokens and channels.
Empirical Validation
The paper validates the proposed DyT by conducting extensive experiments across diverse settings, including computer vision and language modeling tasks. For supervised learning in vision, DyT-enhanced networks often match or exceed those trained with traditional normalization layers. Training loss curves for ViT-B and ConvNeXt-B reflect similar dynamics between LN and DyT models, reinforcing this claim (Figure 4).
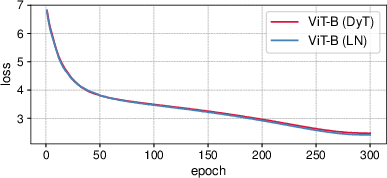
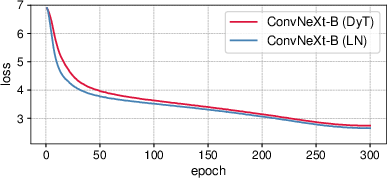
Figure 4: Training loss curves for ViT-B and ConvNeXt-B models.
In the context of LLMs such as LLaMA, DyT also achieves competitive pretraining loss outcomes against models using RMSNorm, with losses closely aligned throughout training (Figure 5).
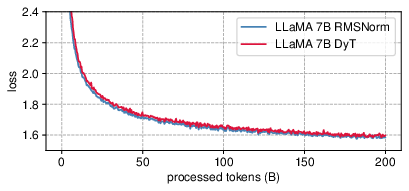
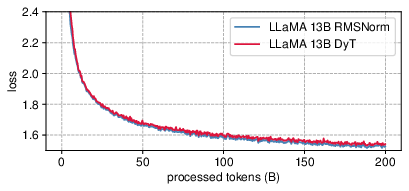
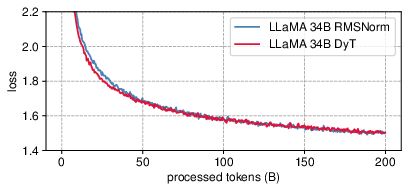
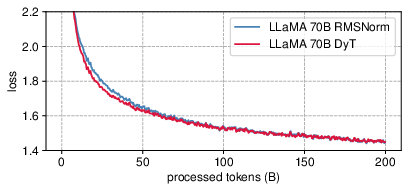
Figure 5: LLaMA pretraining loss for DyT and RMSNorm models.
Architectural Implications
Introducing DyT layers as straightforward replacements for normalization removes the need for calculating activation statistics, potentially accelerating training and inference speeds. This study indicates that DyT not only simplifies architectural design but may also enhance computational efficiency, making it appealing for efficiency-focused applications.
Ablations and Comparisons
The performance of DyT under varied configurations was assessed by replacing tanh with other functions (Figure 6) and altering the initialization of α. The findings underscore tanh’s effectiveness due to its smooth and zero-centered nature, while α plays a crucial role in scaling inputs effectively.
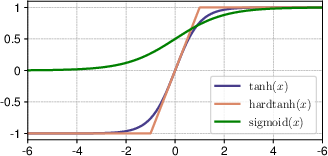
Figure 6: Curves of squashing functions: tanh, hardtanh, and sigmoid, with tanh being the most effective in DyT layers.
Moreover, comparisons with other methods that operate without normalization layers, such as Fixup and SkipInit, reveal DyT as superior in maintaining accuracy across standard Transformer benchmarks.
Conclusion
The study challenges established conventions in neural network design by effectively demonstrating that Transformers can be trained without normalization layers. Dynamic Tanh stands out as a viable alternative, offering simplicity while preserving or enhancing performance in multiple domains. This research broadens the scope for future architectural innovations and efficiencies, suggesting a reevaluation of the perceived necessity of normalization layers in deep learning frameworks.

