- The paper introduces AF-KAN, leveraging diverse activation functions and parameter reduction techniques to enhance image classification performance.
- It employs various activation functions like SiLU, GELU, and SELU with unique function combinations to overcome the limitations of ReLU-based models.
- Experimental results on MNIST and Fashion-MNIST show AF-KAN achieving competitive accuracy with significantly fewer parameters than traditional networks.
AF-KAN: Activation Function-Based Kolmogorov-Arnold Networks for Efficient Representation Learning
The paper "AF-KAN: Activation Function-Based Kolmogorov-Arnold Networks for Efficient Representation Learning" introduces a new variant of Kolmogorov-Arnold Networks (KANs) called AF-KAN. This model integrates diverse activation functions and parameter reduction techniques to optimize network performance, particularly in image classification tasks.
Introduction to AF-KAN
AF-KAN extends the traditional KANs by incorporating a broader range of activation functions and function combinations. The motivation behind AF-KAN is to address the limitations of ReLU-KAN, which primarily uses ReLU functions, thereby constraining feature extraction due to ReLU's inability to handle negative values. AF-KAN introduces other activation functions like SiLU, GELU, and SELU, seeking to enhance the versatility and performance of KANs.
AF-KAN also implements parameter reduction techniques, such as attention mechanisms and data normalization, to reduce the number of parameters without sacrificing network performance. These techniques make AF-KAN comparable to Multilayer Perceptrons (MLPs) in terms of parameter count, offering an efficient representation learning model suitable for image classification tasks.
Methodology
The AF-KAN model builds upon the foundational principles of KANs, which rely on the Kolmogorov-Arnold Representation Theorem. This theorem facilitates the decomposition of multivariate functions into sums of univariate functions, thereby forming the theoretical basis for KAN-style architectures.
Activation Function Combinations
AF-KAN employs various function combinations derived from activation functions inspired by those used in ReLU-KAN. The default function type, referred to as "quad1," uses combinations like (p×q)2, where p=act(x−l) and q=act(h−x). Alternative function types include sum and cubic combinations, each offering different representational capabilities.
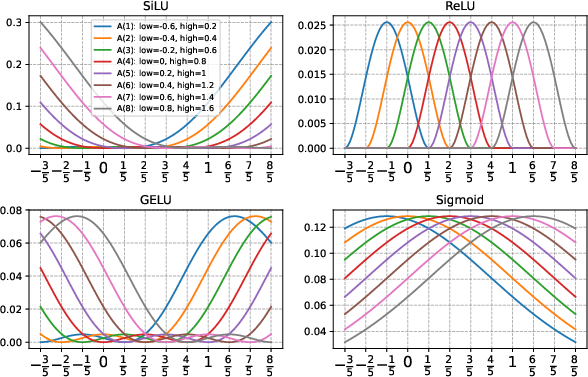
Figure 1: Simulate the plots of the function A using several activation functions. This function is configured with a grid size of G=5, a spline order of k=3, and the function type quad1.
Parameter Reduction Techniques
AF-KAN integrates global and spatial attention mechanisms to reduce parameter count efficiently. Global attention considers all elements across a tensor to compute attention weights, whereas spatial attention leverages spatial data dimensions. Attention mechanisms play a critical role in parameter efficiency and feature extraction, making AF-KAN as parameter-efficient as MLPs, while enabling robust representation capabilities.
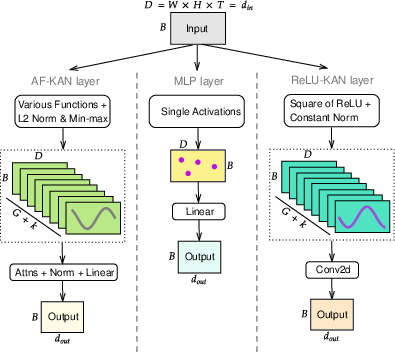
Figure 2: Flow of an input through AF-KAN, MLP, and ReLU-KAN layers. Left: AF-KAN enables a broader range of functions using L2 norm, min-max scaling, and attention mechanisms to reduce parameters. Center: MLP applies a single activation function and linear transformation. Right: ReLU-KAN uses the "Square of ReLU" with a constant norm and a 2D convolutional layer.
Experiments and Results
Experiments conducted on MNIST and Fashion-MNIST datasets demonstrate that AF-KAN substantially outperforms other KANs, such as ReLU-KAN, and remains competitive with traditional MLPs in terms of validation accuracy, even with fewer parameters.
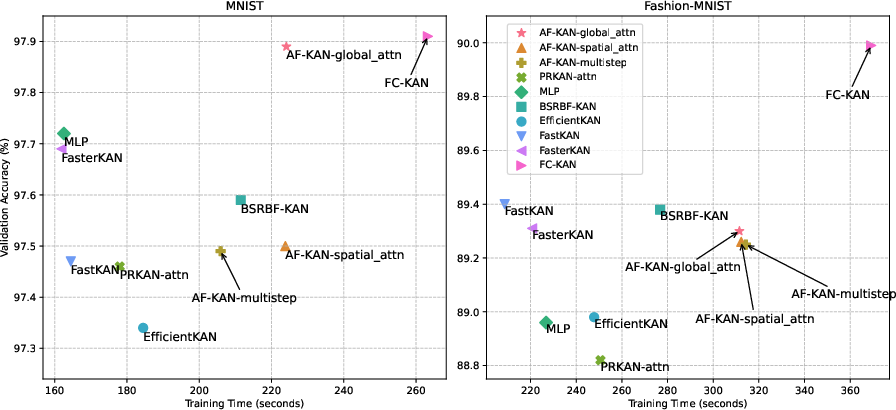
Figure 3: The comparison of AF-KAN variants with other models of the same network structure in terms of training time and validation accuracy. AF-KANs, MLP, and PRKAN use approximately 52K parameters, while other models range from 400K to 560K parameters.
AF-KAN achieves its best performance when employing SiLU as the activation function and utilizing quad1 as the function type. Additionally, it showcases significant performance gains by adapting smaller grid sizes and third-order spline orders, suggesting that proper configuration is vital to maximizing AF-KAN's efficacy.
Training Time and Computational Cost
One notable disadvantage of AF-KAN is the requirement for longer training times and increased FLOPs compared to other models. This is primarily due to incorporating additional components and enhancing feature extraction through attention mechanisms. While this trade-off is considered acceptable given the performance benefits, further optimization could help enhance the balance between efficiency and computational cost.
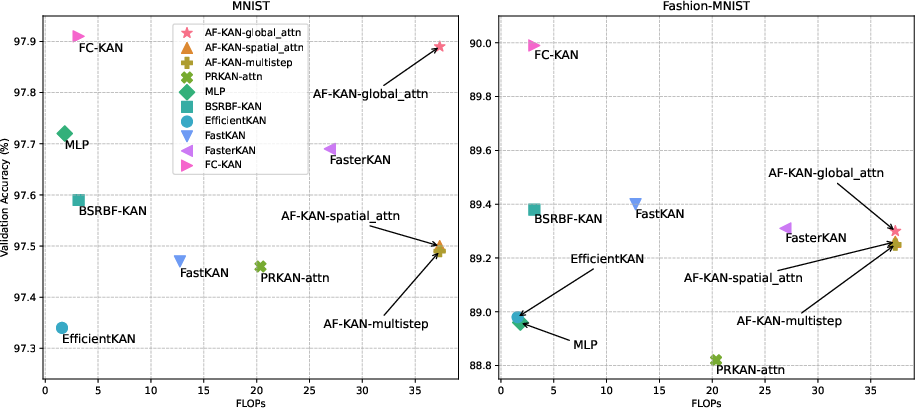
Figure 4: The comparison of AF-KAN variants with other models of the same network structure in terms of flops and validation accuracy.
Conclusion
AF-KAN presents an effective and parameter-efficient approach to representation learning in neural networks by integrating diverse activation functions and parameter reduction techniques. While AF-KAN shows promise in outperforming traditional KANs and remaining competitive with MLPs, future work could focus on optimizing its computational efficiency and expanding its applicability to more complex and larger-scale datasets. Through continued refinement and experimentation, AF-KAN could establish itself as a viable alternative for efficient representation learning in various domains.