- The paper introduces RewardAgent, a novel framework integrating human preferences with factual and instruction-following verifications for more reliable reward models.
- It details three core components—Router, Verification Agents, and Judger—that collaboratively ensure accuracy and strict adherence to instructions.
- Experiments on benchmarks like RM-Bench, JudgeBench, and IFBench show that RewardAgent significantly outperforms traditional reward models in best-of-n search and LLM training.
Agentic Reward Modeling: Integrating Human Preferences with Verifiable Correctness Signals for Reliable Reward Systems
Agentic Reward Modeling represents an innovative approach to improving the reliability of Reward Models (RMs) by integrating human preferences with verifiable correctness signals. The conventional methods predominantly focus on aligning RMs with human preferences, consequently introducing subjective biases that can diminish the reliability of these models in real-world applications. This paper introduces a novel framework called RewardAgent, designed to enhance RMs by synthesizing human preference rewards with verifiable signals such as factual accuracy and instruction adherence.
Framework of RewardAgent
RewardAgent is a structured implementation of agentic reward modeling. It comprises three key components: Router, Verification Agents, and Judger. The Router dynamically determines which verification agents to invoke based on specific task requirements. The Verification Agents evaluate the correctness of responses in terms of factuality and instruction adherence, while the Judger integrates these evaluations with human preference scores to assign a comprehensive reward.
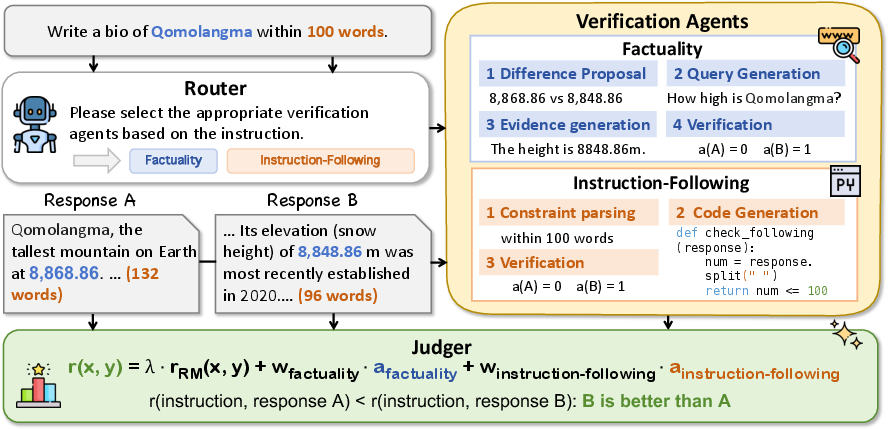
Figure 1: The framework of RewardAgent, including three modules: Router, Verification Agents, and Judger.
Verification Agents
Factuality Verification: This agent implements a process that includes identifying inconsistencies between response pairs, generating queries to retrieve supporting evidence, and verifying the factual accuracy using the acquired information. The process is designed to be efficient, reducing the computational overhead typically associated with such tasks.
Instruction-Following Verification: This agent evaluates adherence to hard constraints specified within instructions, utilizing methods such as Python code generation to verify compliance with constraints. This approach is particularly effective in evaluating surface-form constraints, which are not easily assessed using traditional reward models.
Experimental Validation
RewardAgent's effectiveness was demonstrated through comprehensive experiments on multiple benchmarks, including RM-Bench, JudgeBench, and a newly constructed benchmark, IFBench, which evaluates the adherence to multi-constraint instructions. The results indicate that RewardAgent significantly outperforms existing reward models in these evaluations, showcasing its ability to produce more reliable reward systems.
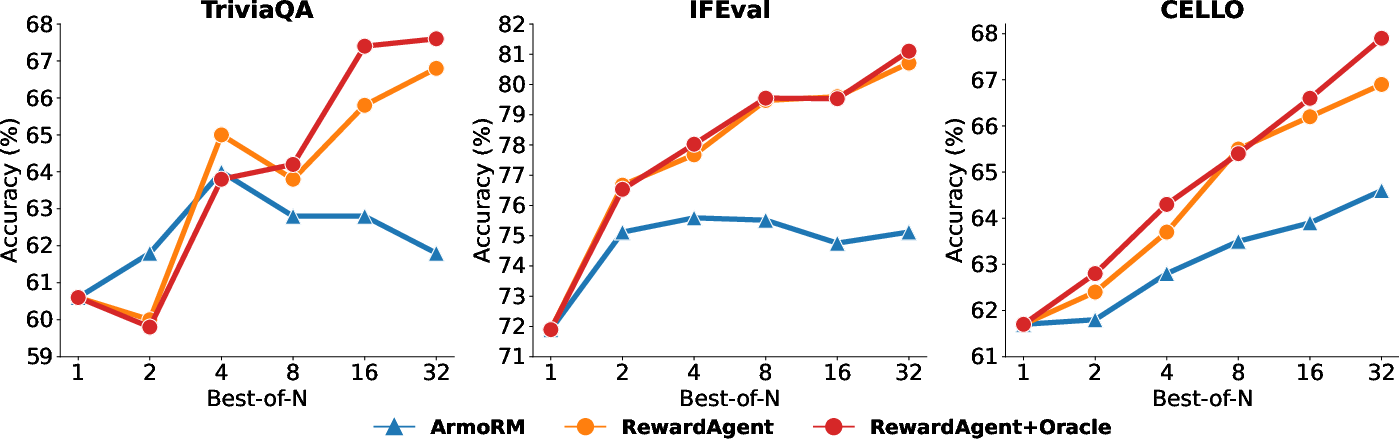
Figure 2: Best-of-n results (\%) on TriviaQA, IFEval, and CELLO using the base reward model ArmoRM and RewardAgent to search. ``+Oracle'' denotes using the oracle setting of RewardAgent as mentioned in \cref{sec:exp_analysis.
Best-of-N Search
The RewardAgent was evaluated on its ability to conduct best-of-n searches, which are crucial for optimizing inference outputs in real-world applications. Experiments utilizing datasets such as TriviaQA and CELLO demonstrated that RewardAgent could effectively enhance response selection, outperforming base reward models in identifying superior responses.
Training LLMs with RewardAgent
Beyond inference, the potential of RewardAgent was further validated through its application in training LLMs using Direct Preference Optimization (DPO). By constructing training datasets that account for both preference annotations and correctness signals, models trained with RewardAgent data exhibited superior performance across various NLP benchmarks compared to those trained with conventional datasets.
Conclusion
The integration of human preferences with correctness signals through RewardAgent marks a significant step towards cultivating more reliable and interpretable reward models. This dual-faceted approach not only elevates the quality and reliability of LLM outputs but also lays a foundation for future explorations in refining reward systems. Building upon this framework, future work can explore more diverse verifiable signals and adaptive planning mechanisms, further advancing the efficacy and robustness of agentic reward modeling systems.