- The paper introduces the Preference As Reward (PAR) method that reshapes RL rewards by centering and bounding to effectively mitigate reward hacking.
- It employs a sigmoid function on centered rewards to achieve rapid initial learning and stable convergence, validated on models like Gemma2-2B and Llama3-8B.
- Experimental results show that PAR outperforms traditional reward shaping alternatives, ensuring robust alignment on benchmarks such as AlpacaEval 2.0.
Reward Shaping to Mitigate Reward Hacking in RLHF
Introduction
Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning extensive LLMs with human values, yet it is prone to reward hacking. Reward hacking arises when an agent optimizes for deficiencies in the reward function, undermining its intended behavior, thus degrading alignment. This paper explores the prevalent reward shaping methods to address this issue and introduces the Preference As Reward (PAR) approach, exploiting the latent preferences within the reward model for reinforcement learning signals. Evaluations on models such as Gemma2-2B and Llama3-8B exhibit its effectiveness in overcoming reward hacking, achieving state-of-the-art performance on benchmarks like AlpacaEval 2.0, while ensuring robustness and data efficiency.
Design Principles and PAR Method
This work proposes three key design principles for effective reward shaping: bounding the RL reward, encouraging rapid initial growth followed by gradual convergence, and utilizing centered rewards as a function. These principles guide the development of the PAR technique, applying a sigmoid function to centered rewards—the discrepancy between proxy rewards and reference rewards. This function is designed for rapid learning and stable convergence, leveraging latent preferences mimicking human evaluation processes. Thus, the RL reward is interpreted as a preference score between the policy and reference responses.
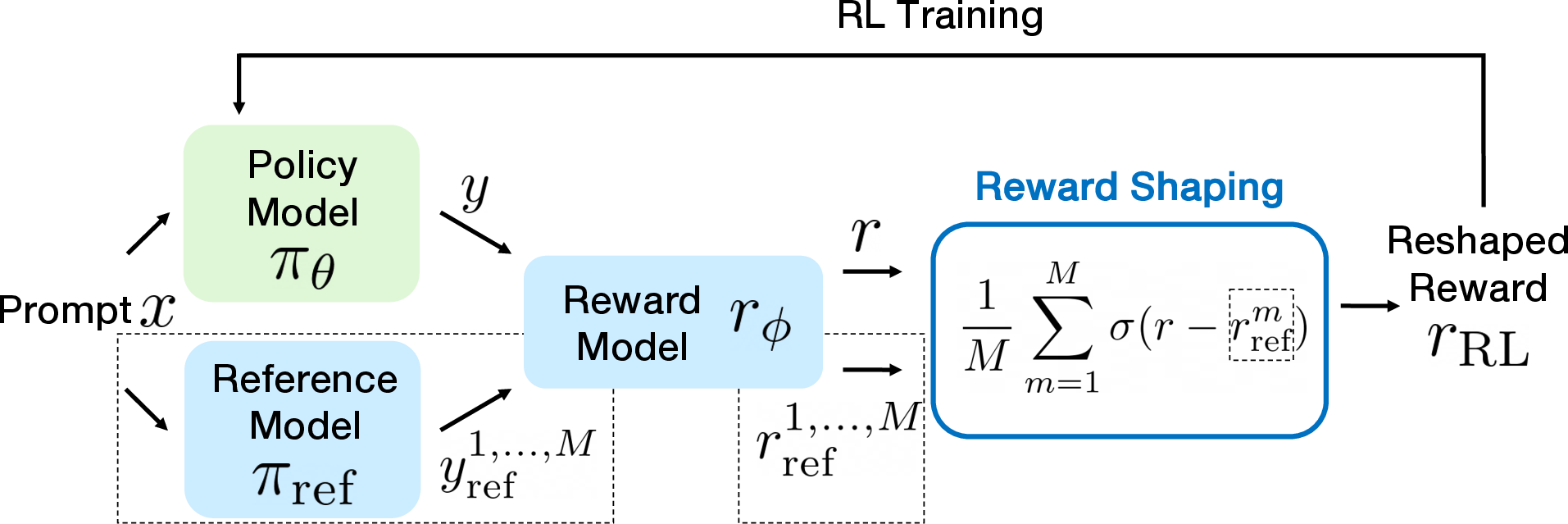
Figure 1: RLHF training pipeline with reward shaping. Responses from the policy model are evaluated by the reward model, producing proxy rewards. These rewards are then reshaped before being used to update the policy via RL.
Evaluation and Results
Experiments highlight PAR's superior effectiveness in reward shaping compared to alternatives like WARM and Minmax while proving robust against reward hacking over extended training periods.
Experimental Setup
Two base models, Gemma2-2B and Llama3-8B, were evaluated using datasets such as Ultrafeedback-Binarized and HH-RLHF, and PPO algorithm training was conducted. The evaluation metrics included Proxy Reward and Winrate curves.
Principles Validation
The validation of the three design principles is manifested through empirical testing of various sigmoid-like functions, establishing rapid initial growth and bounded rewards as critical factors in successful RL training.
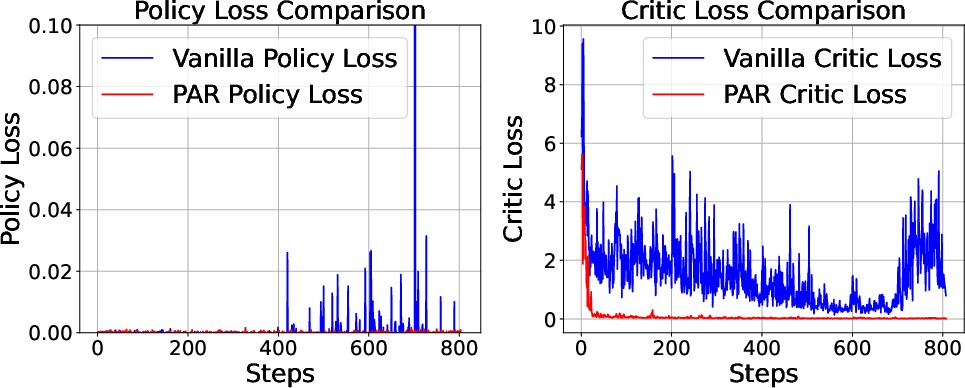
Figure 2: Loss curves from PPO training show that PAR exhibits greater stability, particularly in critic loss, compared to Vanilla training. This stability is attributed to PAR's bounded RL reward.
PAR consistently exhibited top-tier performance across evaluations pertaining to AlpacaEval 2.0 and MT-Bench, supporting the notion that reward shaping improvements enhance alignment without degrading peak performance metrics.
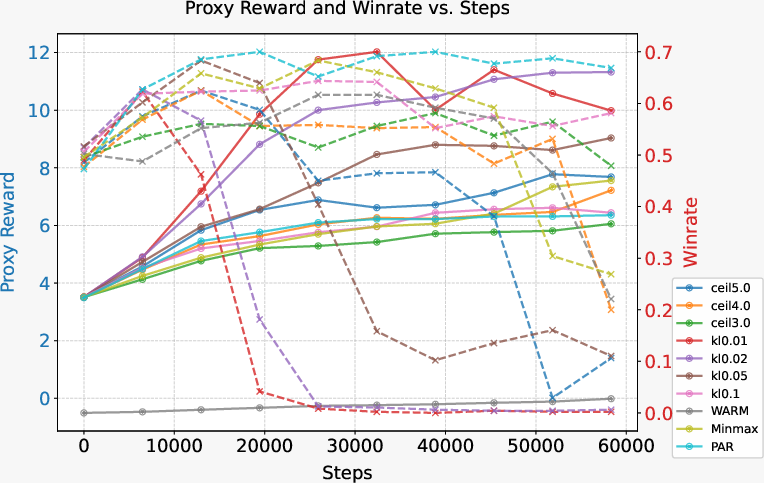
Figure 3: PPO training curves over two epochs. ceil5.0 indicates that $r_{\text{RL}$ is bounded, reinforcing the need for bounded rewards, as demonstrated by improved stability in modeling.
Discussion
The paper discusses the unsuitability of reward shaping approaches like PAR for DPO due to inherent reward model absence, while linear transformations fail to impact GRPO due to inefficacy in modifying advantage calculations. However, non-linear methods such as PAR maintain effectiveness.
Conclusion
The research provides critical insights into RLHF, establishing the importance of reward shaping based on bounded and centered rewards. PAR emerges as the preeminent method for reinforcing optimal behavior, mitigating reward hacking effectively.
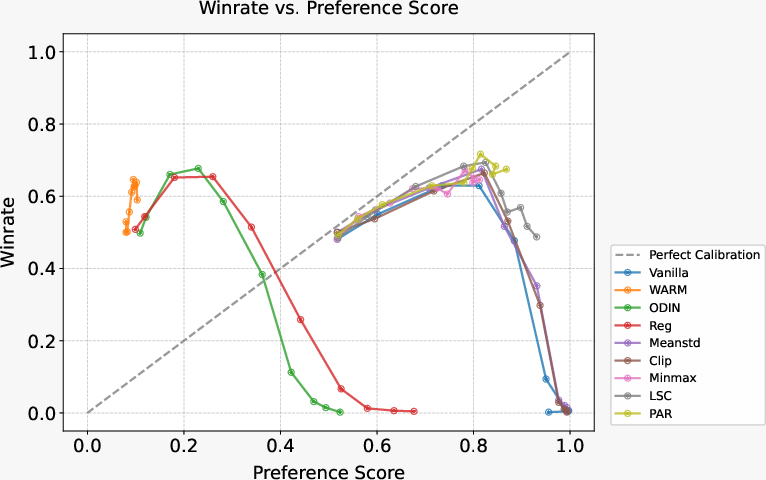
Figure 4: The calibration between hidden preference score given by reward model and winrate for different mitigation methods, illustrating PAR's alignment stability.
In sum, this paper contributes vital methodologies advancing RLHF through informed reward shaping strategies, offering substantive implications for future developments in AI alignment techniques.

