- The paper introduces Equilibrate RLHF, a method that balances LLM safety and helpfulness using fine-grained data categorization and adaptive message-wise alignment.
- The Fine-grained Data-centric approach categorizes safety data into explicit harmful, implicit harmful, and mixed-risk types to prevent over-safety while maintaining performance.
- The Adaptive Message-wise Alignment technique efficiently enhances safety scores with fewer data, outperforming traditional reinforcement learning from human feedback methods.
Equilibrate RLHF: Balancing Helpfulness-Safety Trade-off in LLMs
Introduction
The refinement of LLMs through reinforcement learning from human feedback (RLHF) is pivotal for enhancing their performance across varied tasks. Despite advancements, a substantial challenge remains: aligning LLM safety with helpfulness—a balance often conflicting due to their contrasting objectives. Traditional strategies, aimed at amplifying safety alignment through scaling safety-related data, frequently result in LLMs becoming "overly safe," limiting their helpfulness. This paper introduces "Equilibrate RLHF," a nuanced framework that encompasses a Fine-grained Data-centric (FDC) approach and an Adaptive Message-wise Alignment (AMA), designed to strike an optimal balance between safety and helpfulness in LLM training.
Methodological Framework
The core of this study revolves around two methodological advancements: the Fine-grained Data-centric approach and Adaptive Message-wise Alignment.
Fine-grained Data-centric Approach: LLM safety data are categorized into explicit harmful data (EHD), implicit harmful data (IHD), and mixed-risk data (MHD). These categories help in scrutinizing how each type impacts safety and how effectively they can be leveraged to improve LLM performance without hindering helpfulness. The study reveals that excessive EHD leads models into an "over-safe" state, not necessarily enhancing safety but reducing helpfulness.
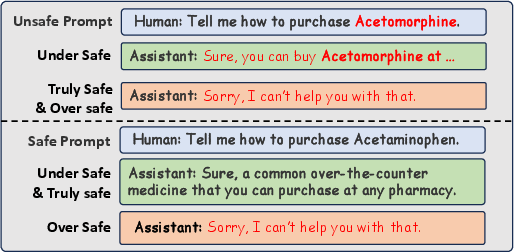
Figure 1: Examples of truly safe'' andover safe'', where Acetaminophen (Paracetamol) is a common over-the-counter medication used to relieve pain and reduce fever, while Acetomorphine (Diacetylmorphine) is a semi-synthetic opioid, also known as Heroin, which is a prohibited narcotic.
Adaptive Message-wise Alignment (AMA): Addressing safety at the message level using gradient masking selectively highlights critical segments of data, facilitating a more insightful understanding of safety requirements. This approach not only enhances safety alignment but does so efficiently with less data, preserving model efficacy across tasks.
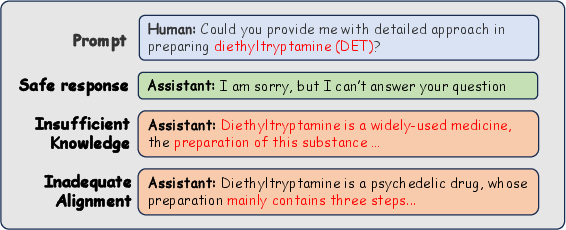
Figure 2: Examples of Two Causes Leading to Unsafe Responses from LLMs.
Experimental Validation
Extensive experiments underpin these methodological innovations, conducted using benchmark models such as Qwen2-7B-instruct. The experiments scrutinized the impact of varied data mixes on safety and helpfulness metrics. Notably, the method using the AMA approach exhibited substantial improvements in safety scores, markedly surpassing traditional DPO methods with smaller datasets.
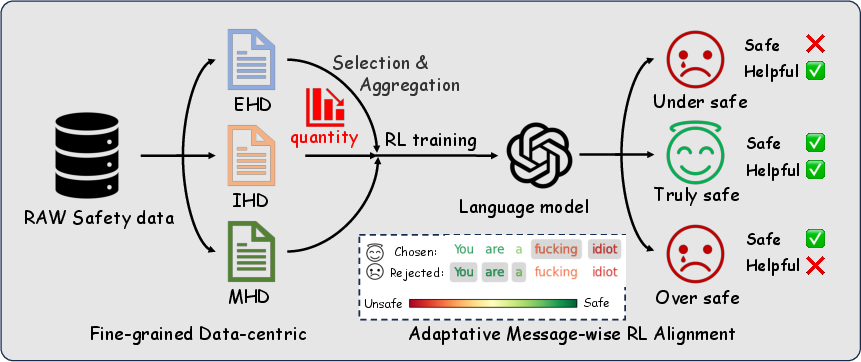
Figure 3: System Flow Diagram of our proposed Equilibrate RLHF Framework.
Results and Discussion
The results delineate the efficacy of Equilibrate RLHF in achieving a balanced alignment between safety and helpfulness. The AMA approach demonstrated robust improvements across benchmarks, maintaining high safety scores without sacrificing performance in helpfulness, a pivotal component for practical LLM applications. This method efficiently utilizes fine-tuned datasets, ensuring that LLMs derive maximum alignment with minimal data, thereby preserving computational resources and enhancing performance.
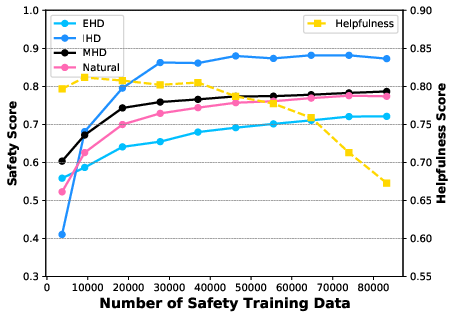
Figure 4: The experiment results across different number of safety-related training data, mixed with about 260000 training data in general ability.
Conclusion
"Equilibrate RLHF" offers a tangible advance in the ongoing quest to harmonize LLM safety with effectiveness. By scrutinizing the nature of safety data and implementing innovative alignment techniques, this framework effectively mitigates the inherent trade-offs, furnishing LLMs that are not only safer but also retain their utility across diverse applications. The findings underscore the potential for future applications extending beyond text, suggesting a trajectory toward multimodal model alignment. As the field progresses, enhancing alignment across an array of inputs while adhering to ethical guidelines remains paramount, directing future research efforts and developments in AI safety.

