- The paper introduces RINS as an efficient inference scaling method that leverages recursive architectures to enhance both language and multimodal system performance.
- RINS demonstrates measurable gains, including a +2% increase in 0-shot ImageNet accuracy and lower perplexity scores across benchmarks.
- The study derives scaling laws and provides practical insights for integrating RINS into resource-constrained environments, improving overall inference efficiency.
Recursive Inference Scaling: A Pathway for Enhanced Language and Multimodal Systems
Introduction
The paper "Recursive Inference Scaling: A Winning Path to Scalable Inference in Language and Multimodal Systems" (2502.07503) introduces Recursive INference Scaling (RINS), a novel approach aimed at improving language modeling performance by leveraging recursive architectures during inference. RINS capitalizes on the fractal geometry of language to scale inference time, enhancing the efficiency of LLMs without altering their architecture or training compute budget. This technique not only improves language tasks but also generalizes across multimodal systems, demonstrating superior performance against state-of-the-art recursive strategies, including the notable "repeat-all-over" (RAO) strategy.
Key Contributions
Introducing RINS: The study introduces RINS as an efficient inference scaling strategy, focusing on recursive model architectures that utilize the self-similar nature of language. This recursive strategy is shown to outperform various parameter-sharing methods and enhance performance in both language and multimodal tasks.
Performance Gains: RINS exhibits significant improvements, including a +2% increase in 0-shot ImageNet accuracy for SigLIP-B/16 models. The paper presents empirical results demonstrating that RINS not only surpasses baseline models but also scales better with increased training and inference compute.
Multimodal Extension: Beyond language tasks, RINS extends its applicability to multimodal systems, maintaining its advantages in scenarios involving diverse data types. This capability underscores its utility in enhancing systems that require both language and image processing capabilities.
Stochastic RINS: The paper explores stochastic variants of RINS, which further enhances performance while offering flexibility to modulate inference computation cost without significant degradation in performance.
Detailed Analysis
Recursive Architecture: RINS partitions model architectures into two blocks and applies recursion to one, enhancing the model's capacity to process and refine input data iteratively. This recursive application is akin to scale-invariant decoding, leveraging the inherent structure of language which exhibits self-similarity at multiple levels of representation.
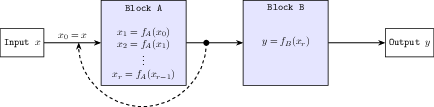
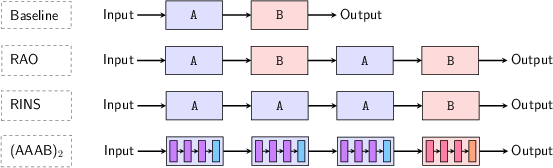
Figure 1: Recursive INference Scaling (RINS) vs. Standard model architecture.
Empirical Results: The experimental portion of the study provides a comprehensive comparison of RINS against non-recursive and RAO strategies. Results indicate that RINS consistently achieves lower perplexity scores and improves zero-shot reasoning capabilities across various benchmarks, even at scaled computational budgets.

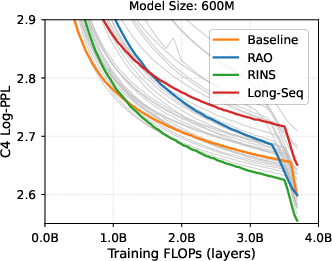
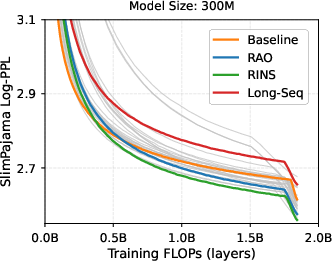
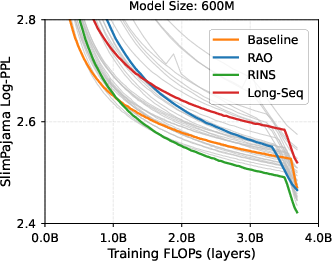
Figure 2: Performance advantage of RINS with increased computational budget in LLMs.
Data Scaling Laws: The paper derives data scaling laws for RINS, demonstrating enhancements in both the asymptotic performance limits and scaling exponents. These results provide empirical evidence that RINS effectively exploits the self-similar nature of language for improved scalability and performance.
Practical Implications: Practically, RINS offers an approach that can be seamlessly integrated into existing systems to enhance inference efficiency and output quality. This aspect is particularly beneficial in environments with stringent model size or computational constraints, such as mobile and embedded systems.
Conclusion
The study presents a compelling argument for Recursive INference Scaling as a versatile, efficient strategy for improving language and multimodal system performance. By demonstrating the empirical advantages of RINS and deriving scaling laws that underscore its efficacy, the paper positions RINS as a potent tool for researchers and practitioners seeking to optimize inference in modern AI systems. Future work may explore further refinements of RINS and its applications across broader domains, potentially extending its benefits in diverse computational frameworks.
```
This markdown essay provides a detailed examination of the paper's contributions, results, and implications, structured for an audience of experienced researchers in AI and related fields.