- The paper proposes Cannistraci-Hebb training with CHTss, enabling sparse neural networks to achieve performance comparable to fully connected models.
- It introduces the Bipartite Receptive Field (BRF) model to mimic brain-like connectivity and optimize network topology effectively.
- Experimental results demonstrate efficiency gains in image recognition and language modeling tasks even at 99% sparsity.
The research paper titled "Brain network science modelling of sparse neural networks enables Transformers and LLMs to perform as fully connected" (2501.19107) proposes a novel approach to improving artificial neural networks (ANNs) by leveraging principles derived from brain network science. Focus is drawn towards Cannistraci-Hebb training (CHT) and its enhancement, CHT soft rule with sigmoid gradual density decay (CHTss), which allow sparse networks to perform on par with or even better than their fully connected counterparts. This exploration promises substantial reductions in computational and memory demands while maintaining efficient network performance.
Cannistraci-Hebb Training Mechanism
Cannistraci-Hebb training (CHT) stems from a brain-inspired dynamic sparse training paradigm, specifically crafted to operate under high sparsity regimes. CHT uses a gradient-free, topology-driven link regrowth mechanism, making it especially potent in ultra-sparse network configurations. The primary challenge CHT faces lies in its inherent complexity, which scales as O(N⋅d3), hampering efficiency in denser networks. To mitigate this, the paper introduces Cannistraci-Hebb training soft rule (CHTs), which deploys a flexible, soft sampling strategy for both link removal and regrowth, significantly optimizing exploration and exploitation of network topology.
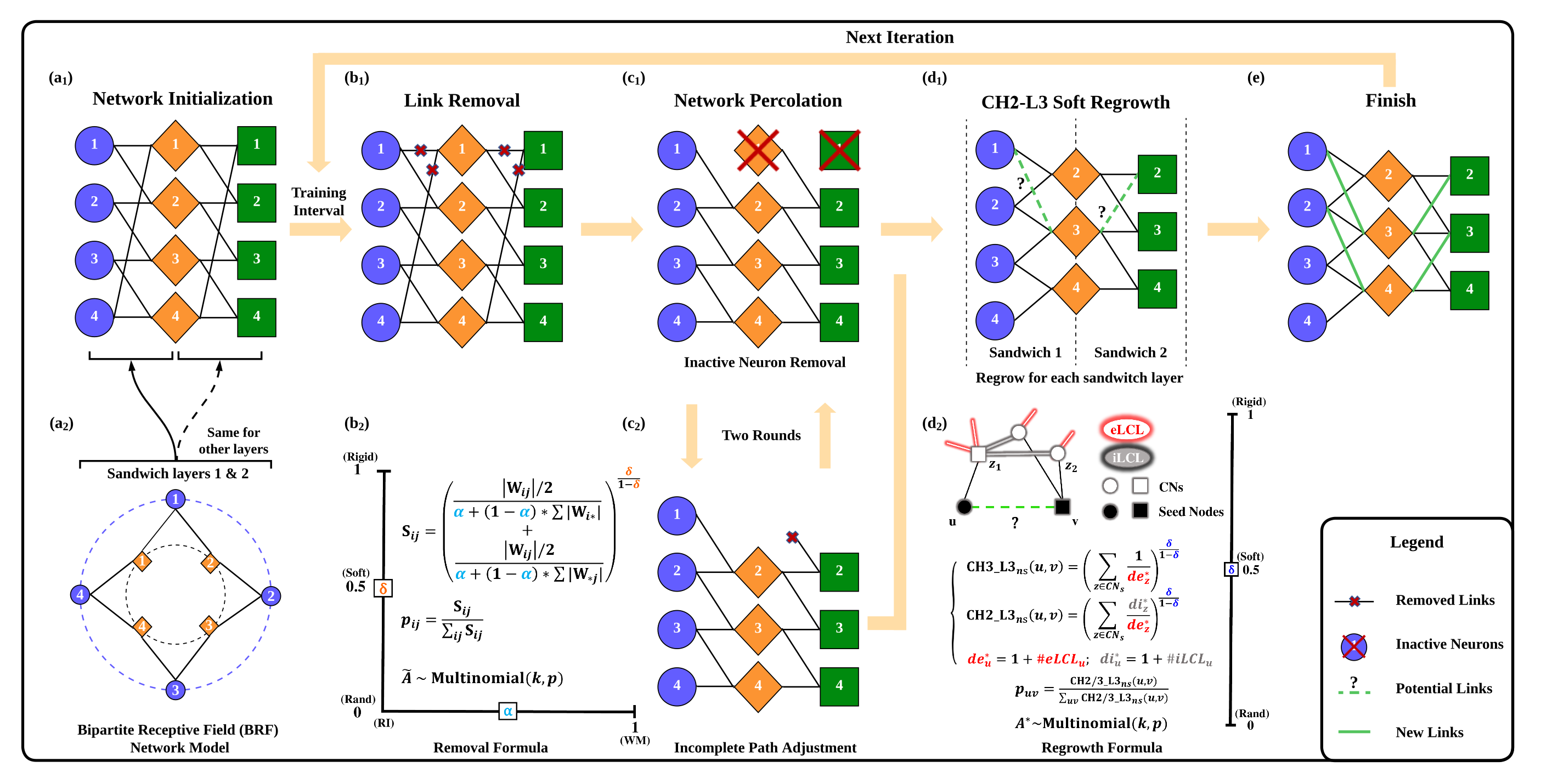
Figure 1: Illustration of the CHTs process providing a step-by-step depiction of the training iteration.
The introduction of a matrix multiplication GPU-friendly approximation further accelerates the algorithm, reducing complexity to O(N3). This enables CHT to scale efficiently across large models, showcasing its adaptability and practical implementation viability.
Sparse Network Modeling with Bipartite Receptive Field
Another pivotal innovation presented is the Bipartite Receptive Field (BRF) model, designed to initialize sparse network topology analogous to brain-like receptive fields. Traditional network science models, like Erdös-Rényi and bipartite small-world models, fail to adequately replicate real-world neural network sparsity patterns. The BRF model resolves this by employing a parameter r, modulating the level of spatial-dependent randomness in connectivity. This model ensures receptive fields manifest with a degree-controlled adjacency matrix, offering a crucial advantage over previous methods.

Figure 2: Comparison of adjacency matrices for various network models as parameters β and r vary.
Figure 2 illustrates the matrix configurations under different parameter settings, emphasizing BRF's unique ability to tailor spatial characteristics seamlessly within network architectures.
Sigmoid-Based Density Decay Strategy
Incorporating a sigmoid-based gradual density decay strategy further refines the training process. Unlike conventional cubic decay functions, the sigmoid decay provides a smoother transition during pruning phases, thereby enhancing model stability and performance. This mechanism aligns closely with bi-directional learning paradigms observed in natural systems, effectively balancing pruning rigor with adaptive growth.
Experimental Validation
The paper thoroughly evaluates these methods across diverse network architectures and tasks, including MLPs for image classification and Transformers for machine translation. Empirical results affirm CHTs' ability to outperform dense networks in image recognition tasks even at 99% sparsity. CHTss pushes this boundary further within LLaMA models, excelling in language modeling tasks often surpassing dense configurations' performance.
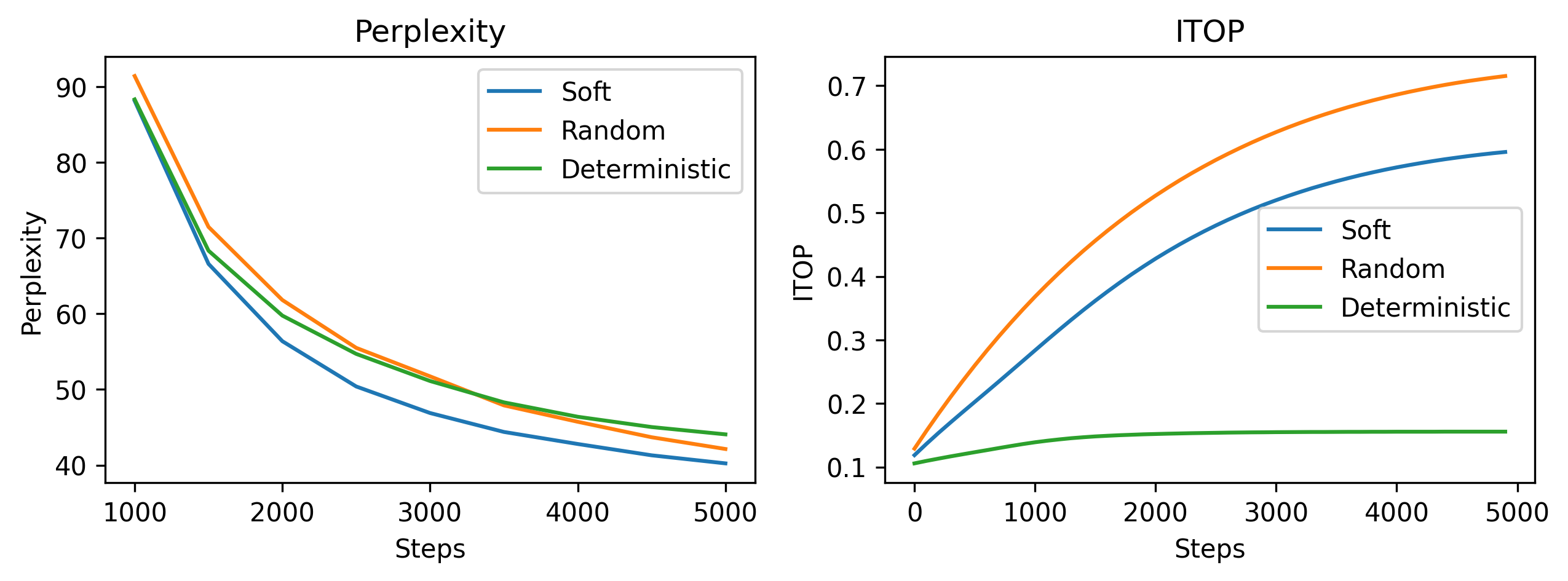
Figure 3: Impact of varying regrowth strategies on model performance metrics in large-scale LLaMA-60M setups.
Figure 3 highlights the influence of the soft regrowth method, establishing its dominance against random and deterministic counterparts through improved perplexity scores and ITOP rates.
Conclusion
This paper advances brain-inspired dynamic sparse training strategies by proposing CHTss, integrating the best of topology-driven modeling and flexible sampling strategies. These innovations facilitate ultra-efficient sparse network training, bridging the performance gap with fully connected models. Looking ahead, these techniques offer promising avenues for scalable deployment of large-scale ANN systems across various domains, needing significantly lower computational footprints while maintaining robust performance benchmarks. Further exploration in automatically tuning the sigmoid-based density decay curvature could enhance adaptability across diverse model sizes and tasks, paving the way for more refined and efficient sparse network training practices.