Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Abstract: Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, "FTCT" (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: can Transformer models (the kind behind many chatbots) connect pieces of knowledge they learned separately and use them together to solve new problems? The authors build a controlled, puzzle-like test to see if Transformers can do “compositional reasoning” — that is, combine small facts into longer chains of reasoning they’ve never seen before.
What questions did the study ask?
The researchers focused on three questions, written here in everyday language:
- When can Transformers connect separate facts to reason correctly?
- What training choices (like the kind of data or model size) make this ability show up?
- How do Transformers do this internally — what’s happening inside the model when it succeeds?
How did the researchers test this?
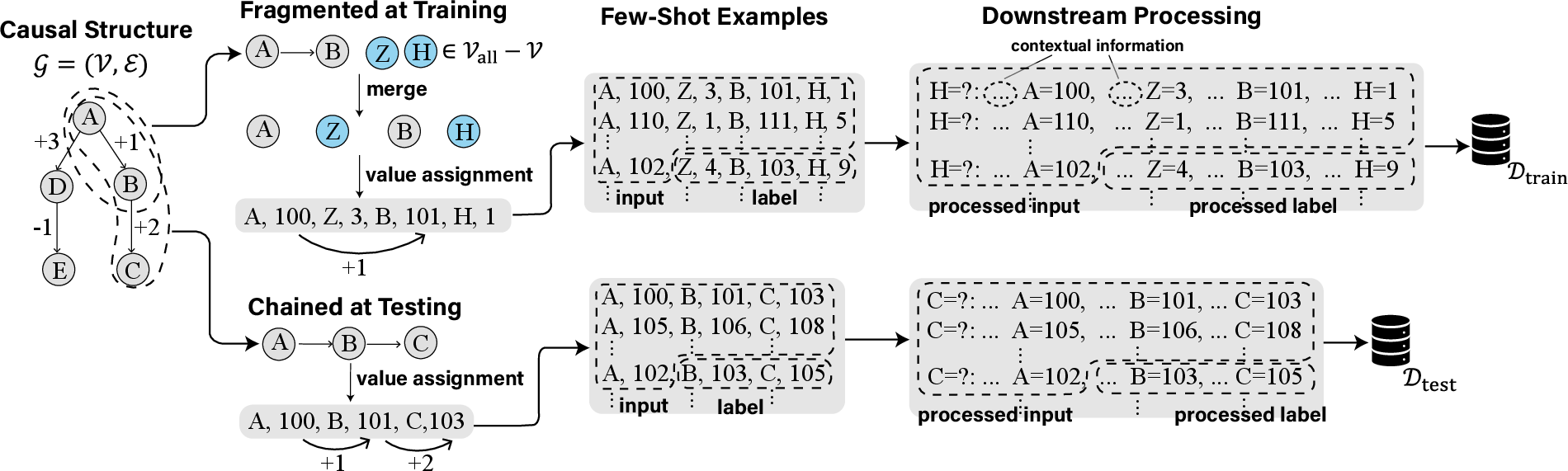
They created a synthetic (made-up but carefully designed) task called FTCT: Fragmented at Training, Chained at Testing.
Here’s the idea in plain terms:
- Imagine a map of linked facts: A leads to B, and B leads to C, where each link applies a simple rule like “add 1” or “subtract 2” to a number. So if A = 100 and the rule from A→B is “+1,” then B = 101. If from B→C the rule is “+2,” then C = 103.
- During training, the model only sees short fragments like “A → B,” mixed with unrelated noise (extra letters and numbers that don’t matter). It never sees the full chain “A → B → C.”
- During testing, the model must solve full chains (like “A → B → C”), which means it has to connect the fragments it learned earlier.
To help the model think step by step, the researchers used few-shot Chain-of-Thought (CoT) prompts. That means they gave the model a small number of example lines showing the reasoning process, and then asked it to solve a new, similar line. Importantly, the examples at test time include complete reasoning chains — combinations the model never saw during training — so succeeding here means real generalization.
They measured success in three simple ways:
- Whole chain accuracy: did the model produce the full correct chain (right steps in the right order with the right numbers)?
- Vertices (order) accuracy: did it list the right items in the right order (like A, then B, then C)?
- Values accuracy: given the right previous step, did it compute the next number correctly (like turning A=100 into B=101 using “+1”)?
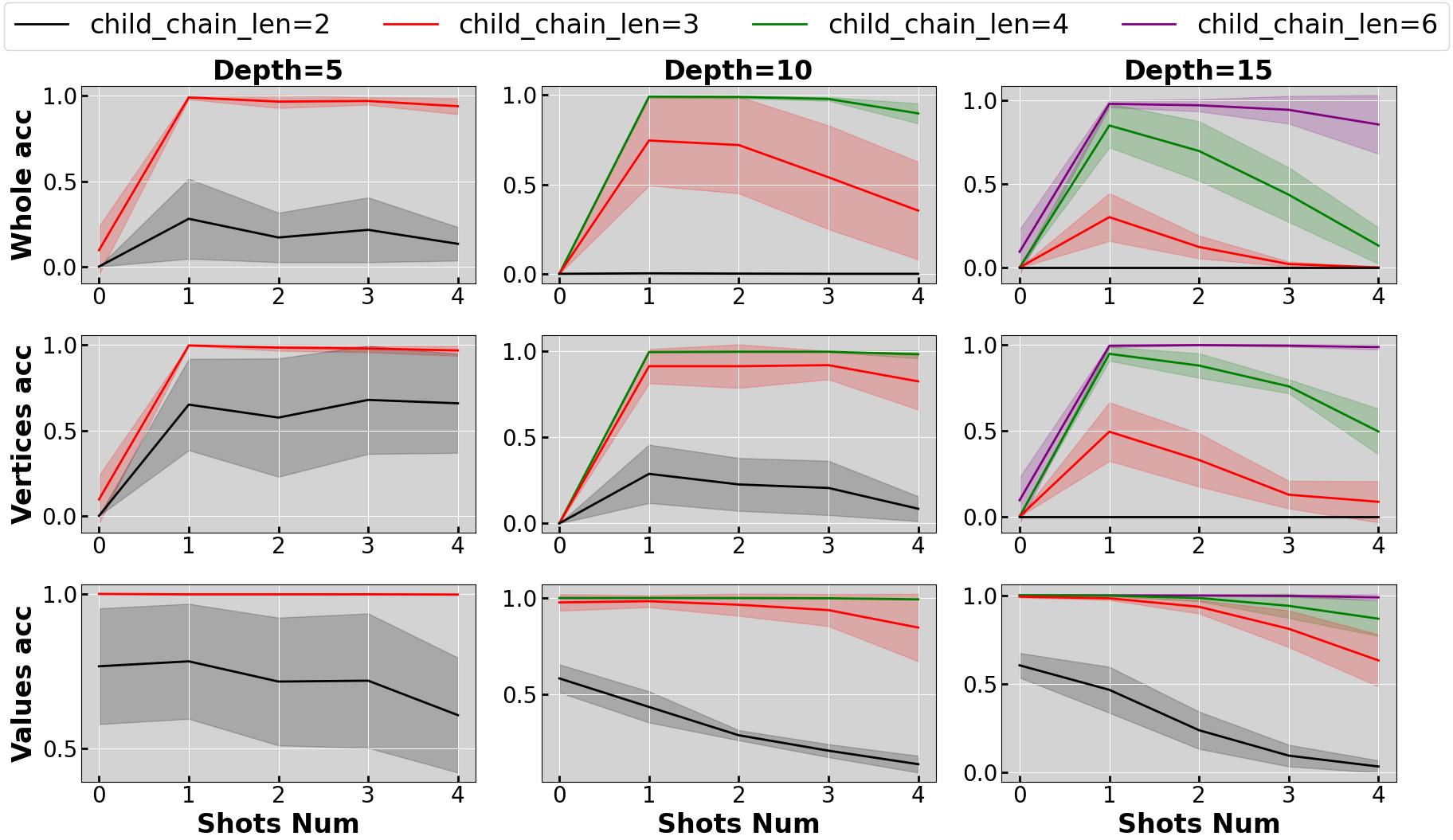
They also varied two things:
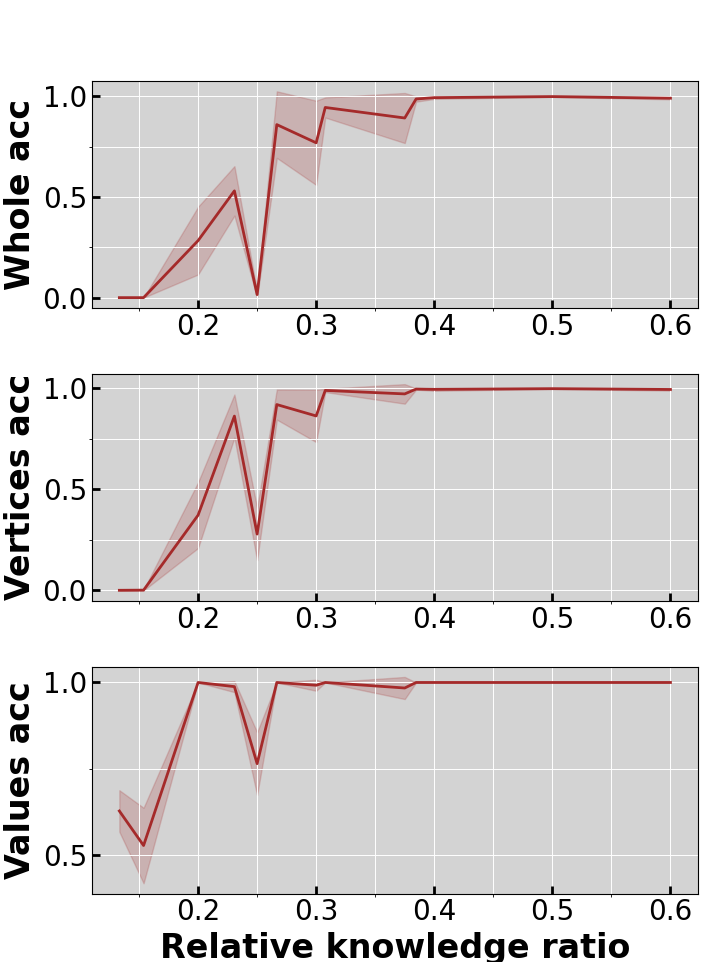
- Training–testing similarity: What fraction of a full chain the model saw during training on average (for example, about 30% of the chain vs. much less).
- Model complexity: Using Transformers with different numbers of layers and attention heads, and comparing them with simpler neural networks (MLPs).
Finally, they peeked “inside” the model using:
- Attention heatmaps: to see which parts of the input the model focuses on while thinking.
- Linear probing: a simple test to check whether the model is “looking at” the correct parent number when computing the next number.
What did they find?
Here are the main results, explained simply:
- Few-shot Chain-of-Thought examples unlock reasoning. With no examples (zero-shot), the models struggled to list the right items in order. But with a few examples (few-shot CoT), performance jumped a lot. The examples show the correct step-by-step pattern to follow, and the model copies that pattern to the new case.
- The model can compute the numbers even on new chains. Once the model knows the right order (A then B then C), it is very good at computing the correct numbers for each step, even though the full chains never appeared in training. This shows it learned the rules (like “+1” from A to B), not just memorized training examples.
- Data similarity matters, with a clear “turning point.” When training fragments covered at least about 30% of the length of the full test chains, reasoning ability “turned on” and got much better. Below that, performance stayed weak. In short: if training fragments are too short compared to test chains, the model struggles; once they’re long enough, the model generalizes.
- Model depth and attention matter. Transformers with at least 2 layers and 2 attention heads did well. Single-layer Transformers often failed to follow the correct order, and simple MLPs struggled to find the right numbers in noisy contexts. This suggests that multi-layer attention is important for both following patterns and picking out the right information.
- What’s happening inside the model? The authors propose that the Transformer learns an “underlying program” with two parts:
- In-context learning: the model copies the pattern of steps from the few-shot examples (for example, “after A comes B”). This is linked to “induction heads,” small attention circuits known to copy patterns.
- Parent retrieving: when asked for the next number, the model looks back to the previous relevant number (the “parent”) and applies the correct rule (like “+1”). Linear probing showed the model specifically attends to the parent’s value and ignores unrelated numbers, which is exactly what you want.
They also give a theoretical result: in principle, a 2-layer Transformer is powerful enough to implement this “program” and perform well on both training and testing in this setup.
Why does this matter?
This study shows, in a clean, controlled setting, that Transformers can do true compositional reasoning: they can connect separate pieces of knowledge and use them together to solve new problems. It also shows:
- Prompts matter: giving a few clear examples of step-by-step reasoning can make a big difference.
- Data design matters: if training fragments are reasonably similar to test tasks (around 30% of the full chain length or more), models are much more likely to generalize.
- Architecture matters: multi-layer attention is important for pattern-following and focusing on the right information.
Big picture: While this is a synthetic task, it suggests that modern LLMs aren’t only memorizing; they can learn small “programs” for reasoning, especially when guided by good examples. That’s encouraging for building AI systems that learn from scattered information and still reason reliably. It also hints at how to improve models in practice: use better prompts, provide the right kind of training data, and rely on architectures that support multi-step attention and pattern copying.
Collections
Sign up for free to add this paper to one or more collections.

