- The paper introduces L2D, a novel finetuning method that integrates a diffusion process into pre-trained language models for adaptive, scalable reasoning.
- The methodology uses Gaussian diffusion in token embedding space with a dedicated diffusion path and cross-entropy loss, preserving original LM weights.
- Empirical results show L2D improves accuracy on complex tasks like math and coding, achieving over 90% of performance gains with just 15 diffusion steps.
LLMs to Diffusion Finetuning
Introduction and Motivation
"LLMs to Diffusion Finetuning" (2501.15781) introduces L2D, a finetuning method designed to imbue pre-trained LMs with the scalable compute properties characteristic of diffusion models. While autoregressive LMs provide state-of-the-art performance across a range of reasoning and generation tasks, they lack flexible test-time reasoning depth—computation per prediction is essentially fixed. In contrast, diffusion models, effective mostly in vision domains, enable iterative, variable-compute generation, adaptively scaling to task complexity or accuracy requirements. However, pure diffusion models in language domains have not matched autoregressive LM performance, likely due to inductive bias mismatches and training inefficiencies.
L2D aims to combine the advantageous properties of both paradigms. Rather than training a diffusion LM ab initio, L2D reframes pre-trained autoregressive LMs as single-step diffusion models, appending a lightweight, trainable diffusion path and leveraging parameter-efficient finetuning, akin to LoRA. This enables monotonically increasing accuracy with additional inference steps, on-demand compute scaling, and the integration of classifier-free guidance—all while preserving the original model weights and single-step generation capability.
L2D: Diffusion-Augmented Finetuning for LLMs
L2D employs Gaussian diffusion in the token embedding space, parameterizing and training a diffusion path alongside the frozen pre-trained LM. Unlike typical continuous-output diffusion, the framework uses a cross-entropy loss over the vocabulary logits, maintaining compatibility with standard LM objectives and facilitating direct transfer and augmentation of extant LM capabilities.
Formally, the method introduces a separate transformer-like diffusion path, initialized from the main LM parameters, and only a small fraction of new parameters (less than 6% of the main LM in the default 1B/8B models). The diffusion path manipulates a ‘diffusion token’ xt representing noisy mixtures of a target token embedding and pure Gaussian noise, integrated into the main LM’s hidden state only at the final layer. Conditioning on timestep t (with sinusoidal embeddings and time-conditioned normalization), the diffusion path is trained to reconstruct the target token via cross-entropy against the vocabulary, given the corrupted token embedding.
Inference proceeds as a discretized ODE denoising process, either via standard Euler or higher-order ODE solvers (e.g., midpoint, RK4), starting from pure noise and iteratively approaching the target token embedding—at each step, sampling the predicted next token from the LM logits. The pre-trained LM path is evaluated once per output token, minimizing compute overhead per step.
L2D Model Architecture and Conditioning
The L2D architecture is modular and parallelizes the diffusion path efficiently. A key trait is that the diffusion path’s residual merges with the main path only at the final layer, ensuring that the original single-step LM output is unchanged at t=0, and the influence of the diffusion path increases with t.
Conditioning mechanisms are broad: beyond context and timestep, classifier-free guidance is employed by learning embeddings for task or domain labels, enabling fine-grained control over model outputs at inference. For instance, tuning the guidance strength wg allows trading off generality and task-specificity dynamically (see Figure 1).
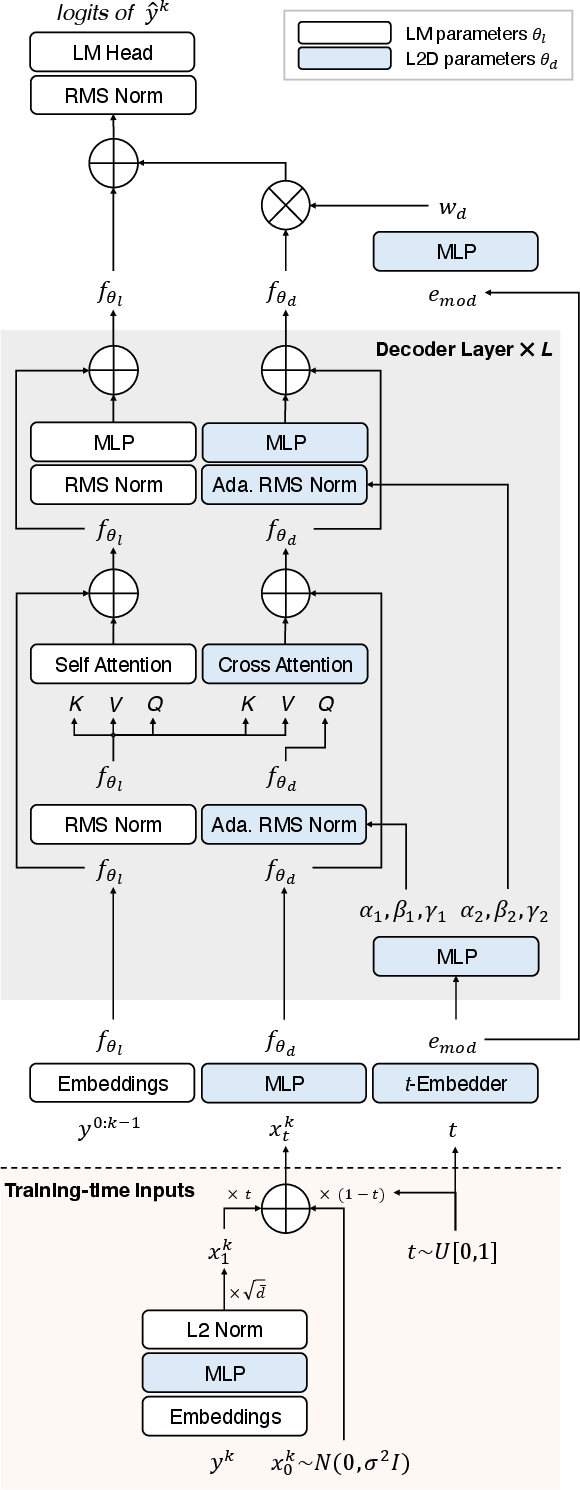
Figure 2: L2D design overview. Diffusion tokens xt1:k are constructed during training, feeding into a dedicated diffusion path that augments the base LM at the final layer.
Empirical Results
Compute-Scaling and Adaptive Inference
A central property of L2D is monotonically increasing performance with increased inference steps. When evaluated on categories such as math and coding, accuracy improves with higher diffusion steps, analogous to the performance saturation observed with diffusion models in vision (see Figure 3). Notably, over 90% of the attainable improvement is achieved with just 15 forward passes of the diffusion path, preserving efficiency.
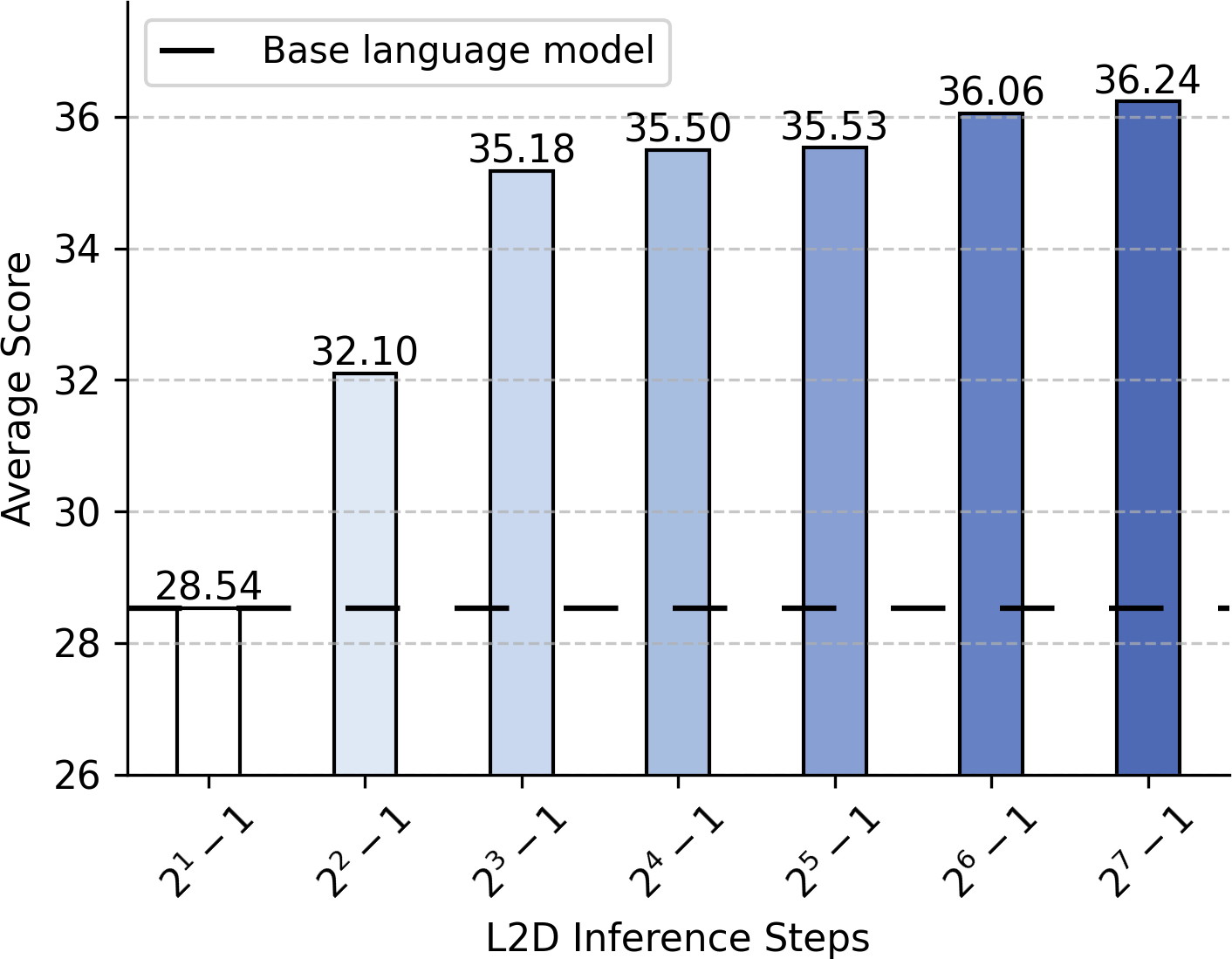
Figure 3: Test-time compute scaling with L2D—more diffusion steps yield higher accuracy.
Performance improvement is also predictable as a function of the diffusion process timestep (see Figure 4). Integrating advanced ODE solvers allows for adaptive, per-token determination of the needed computational budget based on local denoising error, further optimizing the compute/performance tradeoff (see Figure 5).
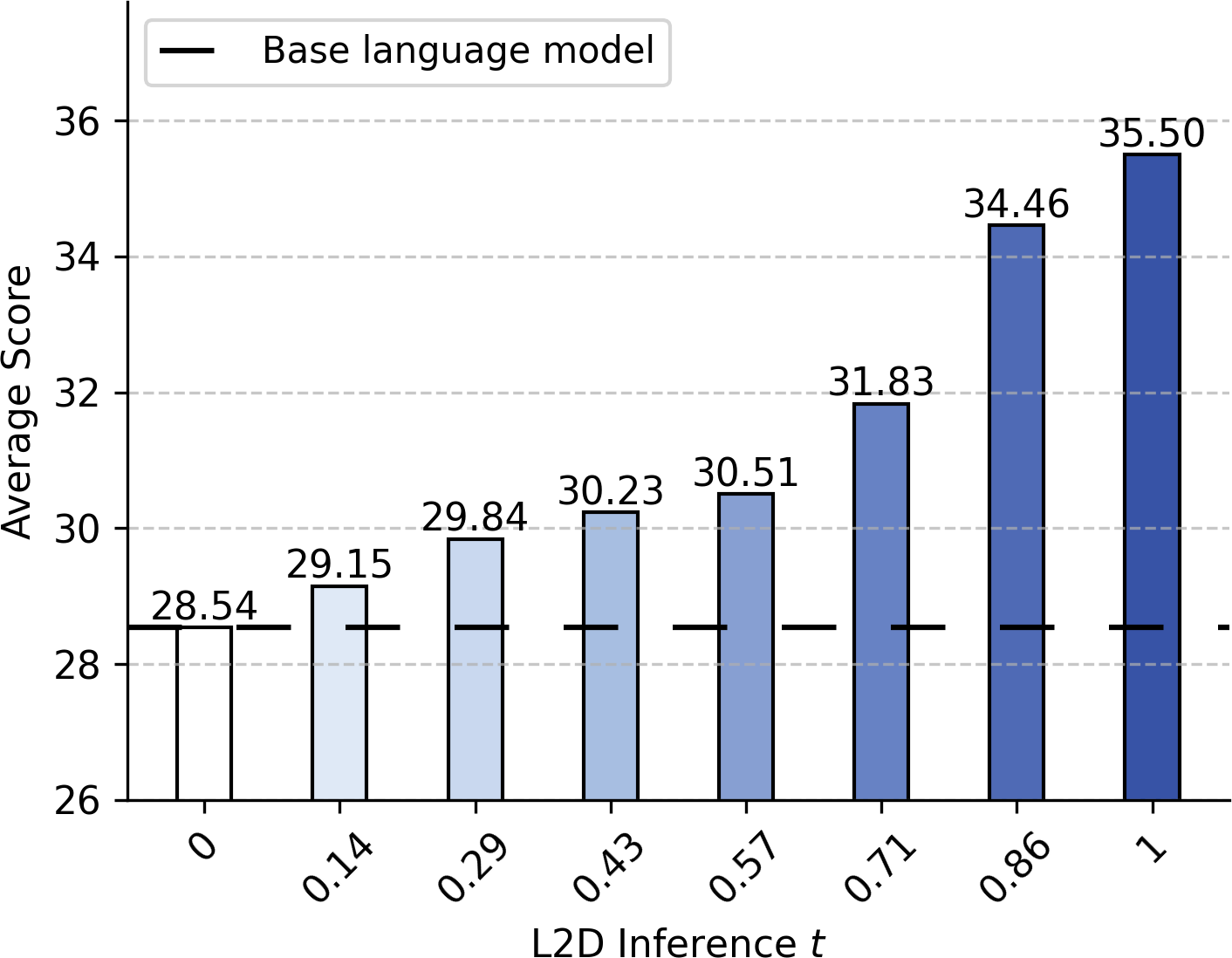
Figure 4: Evolution of performance versus diffusion timestep t within L2D’s process.
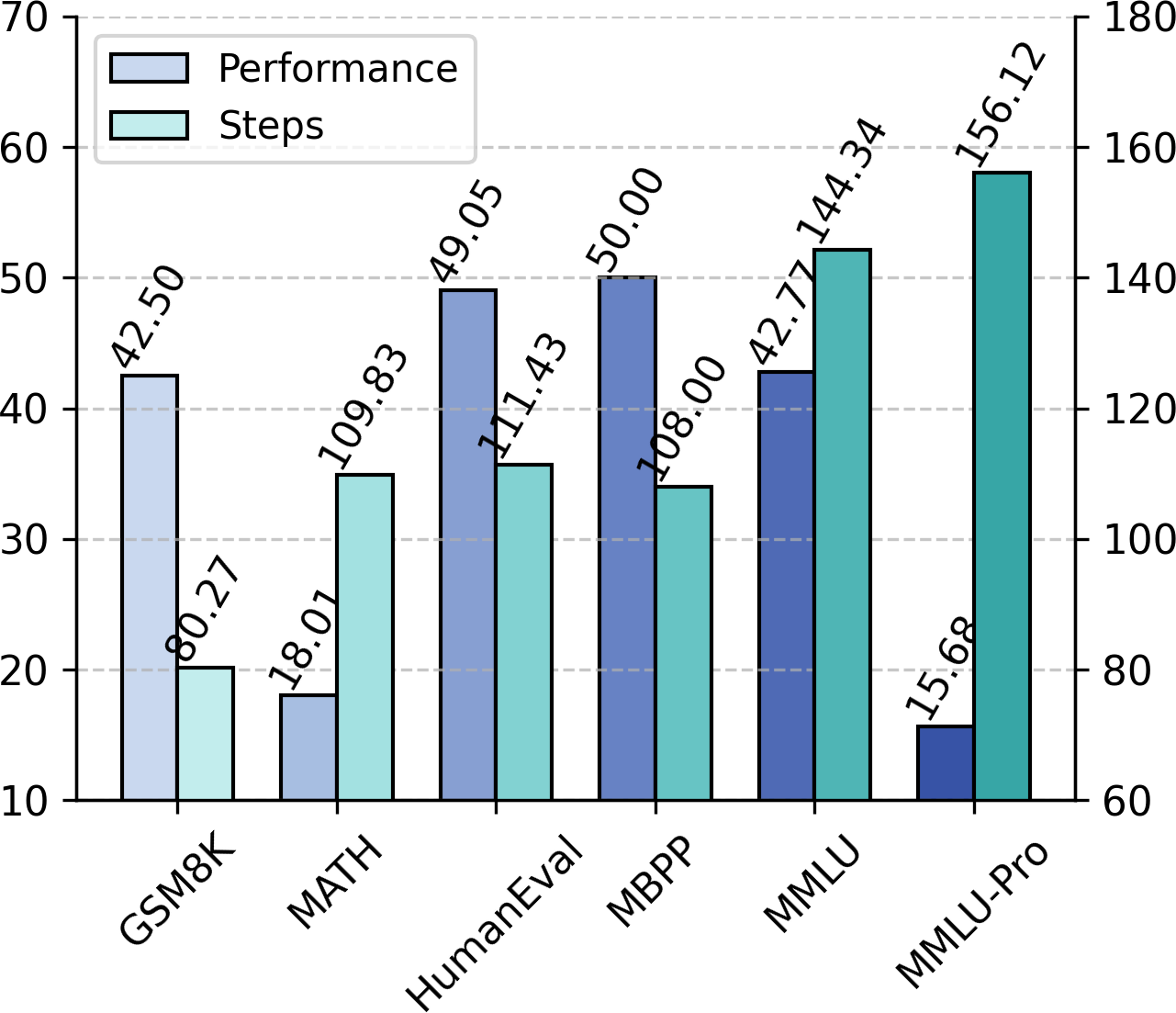
Figure 5: Adaptive scaling—comparing performance (left) and utilized steps (right) using L2D with an adaptive ODE integrator.
Comparison with Traditional Finetuning
L2D yields superior results to both full-weight and LoRA-style finetuning on all considered benchmarks for the same pre-trained Llama and Qwen models, especially on tasks requiring multi-step reasoning (math/coding). Crucially, L2D finetuning does not degrade knowledge retention or basic generation ability, unlike traditional weight optimization approaches which can harm these aspects, particularly on instruction-finetuned models.
Analysis reveals strong complementarity: L2D can be layered on top of LoRA or fully-finetuned checkpoints, further boosting challenging-task accuracy.
Classifier-Free Guidance
Integration of classifier-free guidance enables dynamic task adaptation; stronger guidance improves domain-specific tasks like mathematical problem solving, while moderate guidance suffices for more diverse or stochastic tasks, such as coding with pass@10 evaluation (see Figure 1). Tuning wg per domain can further enhance model utility.
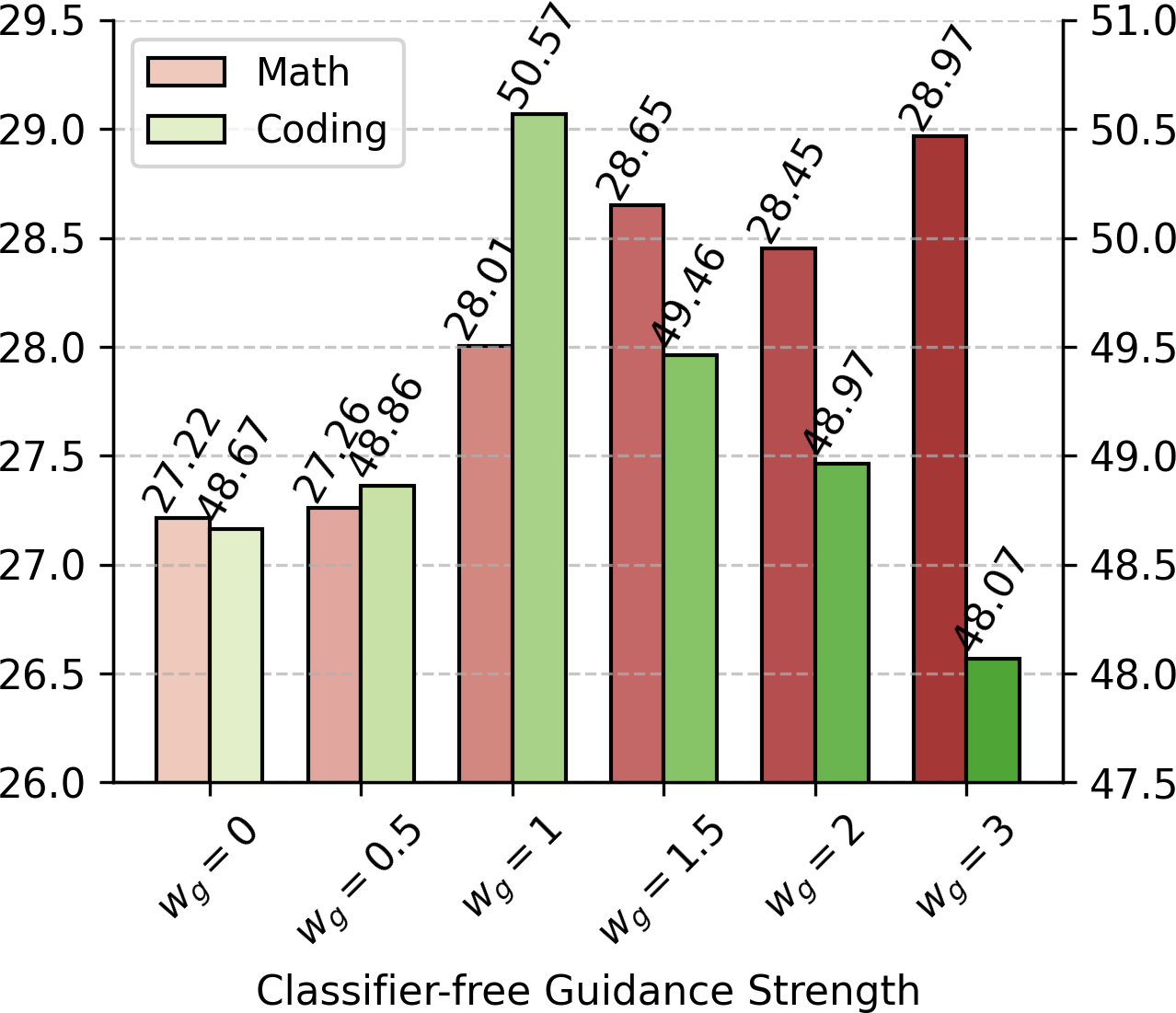
Figure 1: Impact of guidance strength wg on the performance of coding (left) and math tasks (right).
Implications and Future Directions
The diffusion-augmented LM paradigm instantiated by L2D enables fine-grained, adaptive test-time computation, robust to task difficulty and output modality—without retraining or weight modification of the underlying foundation model. This orthogonal capability opens new directions for modular reasoning architectures, flexible alignment schemes (by conditioning on guidance or domain), and efficient multi-task deployment. The empirical evidence suggests that scaling properties and guidance mechanisms, foundational to visual diffusion breakthroughs, can generalize to the language domain when coupled with strong autoregressive priors.
Theoretically, L2D demonstrates a promising fusion of system-1-level linguistic competence (retained from pretraining) and system-2-style, adaptive “deliberative” computation. Practically, L2D could enable LMs as drop-in diffusion modules for adaptive agents, cost-sensitive applications, and personalized models, where domain-specific expertise and compute use can be set on-the-fly.
Open research directions include further architectural innovations in the diffusion path, advanced precision schedules, personalized or user-conditioned guidance, application in multimodal domains, and leveraging larger-scale foundation models.
Conclusion
L2D offers a novel and effective method for injecting the test-time adaptability of diffusion processes into pre-trained LMs via parameter-efficient finetuning. Empirical results substantiate robust, monotonic performance scaling with additional compute, state-of-the-art guidance capabilities, and strong compatibility with existing optimization procedures, all while entirely preserving the native strengths of the autoregressive base model. This work establishes a concrete foundation for unifying the autoregressive and diffusion frameworks in NLP, with significant implications for the development of flexible, efficient, and controllable language reasoning systems.

