- The paper introduces FedMUA, a malicious unlearning attack that manipulates influential samples to mislead global model predictions.
- It employs a two-step process—Influential Sample Identification and Malicious Unlearning Generation—to achieve up to 80% attack success with minimal requests.
- A defense mechanism based on damping abnormal gradient updates is proposed to mitigate these risks and secure federated learning systems.
Exploring the Vulnerabilities of Federated Learning to Malicious Unlearning Attacks
Introduction
The paper "FedMUA: Exploring the Vulnerabilities of Federated Learning to Malicious Unlearning Attacks" (2501.11848) addresses a critical gap in federated learning (FL) concerning its susceptibility to malicious unlearning attacks. In the context of federated learning, the concept of "federated unlearning" has emerged to ensure compliance with privacy regulations such as GDPR, granting users the right to have their data removed from training models. However, the paper identifies and exploits vulnerabilities within this unlearning process through a novel attack method termed FedMUA.
Methodology and Approach
FedMUA is devised to manipulate the federated unlearning process, affecting the prediction behavior of the global model. The crux of the attack lies in misleading the global model to forget more information associated with influential samples than intended. This is achieved through a two-step process: Influential Sample Identification (ISI) and Malicious Unlearning Generation (MUG).
- Influential Sample Identification (ISI): Utilizing influence functions, this step identifies training samples that significantly impact the target prediction. By focusing on samples with negative influence function values and similar labels, attackers can effectively manipulate model outputs after unlearning.
- Malicious Unlearning Generation (MUG): To disguise malicious intent, the attacker modifies the features of these influential samples to resemble the target sample's features instead of altering labels directly. This stealthy approach ensures that the server cannot easily detect the attack, allowing the global model to misclassify targeted sample predictions.
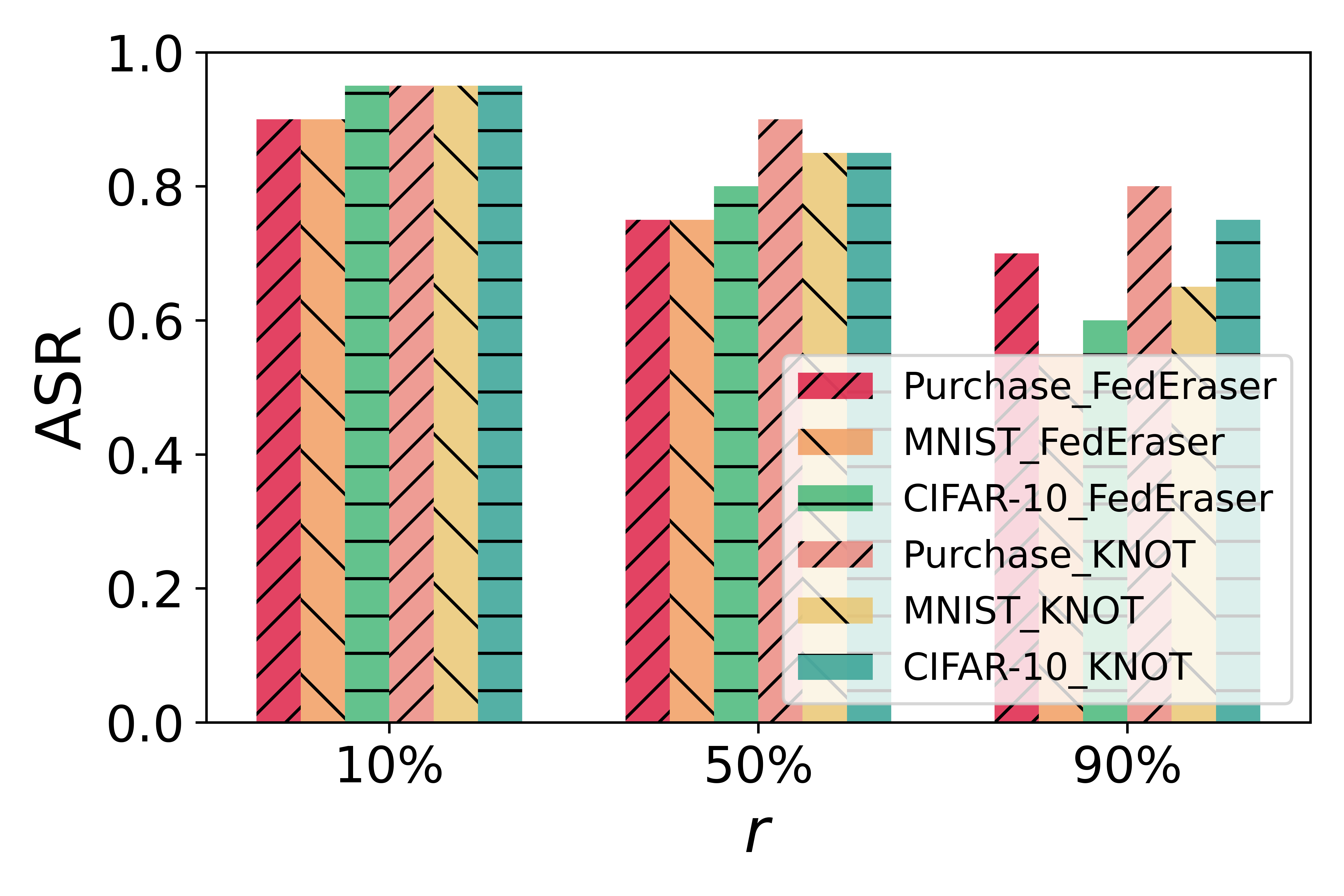
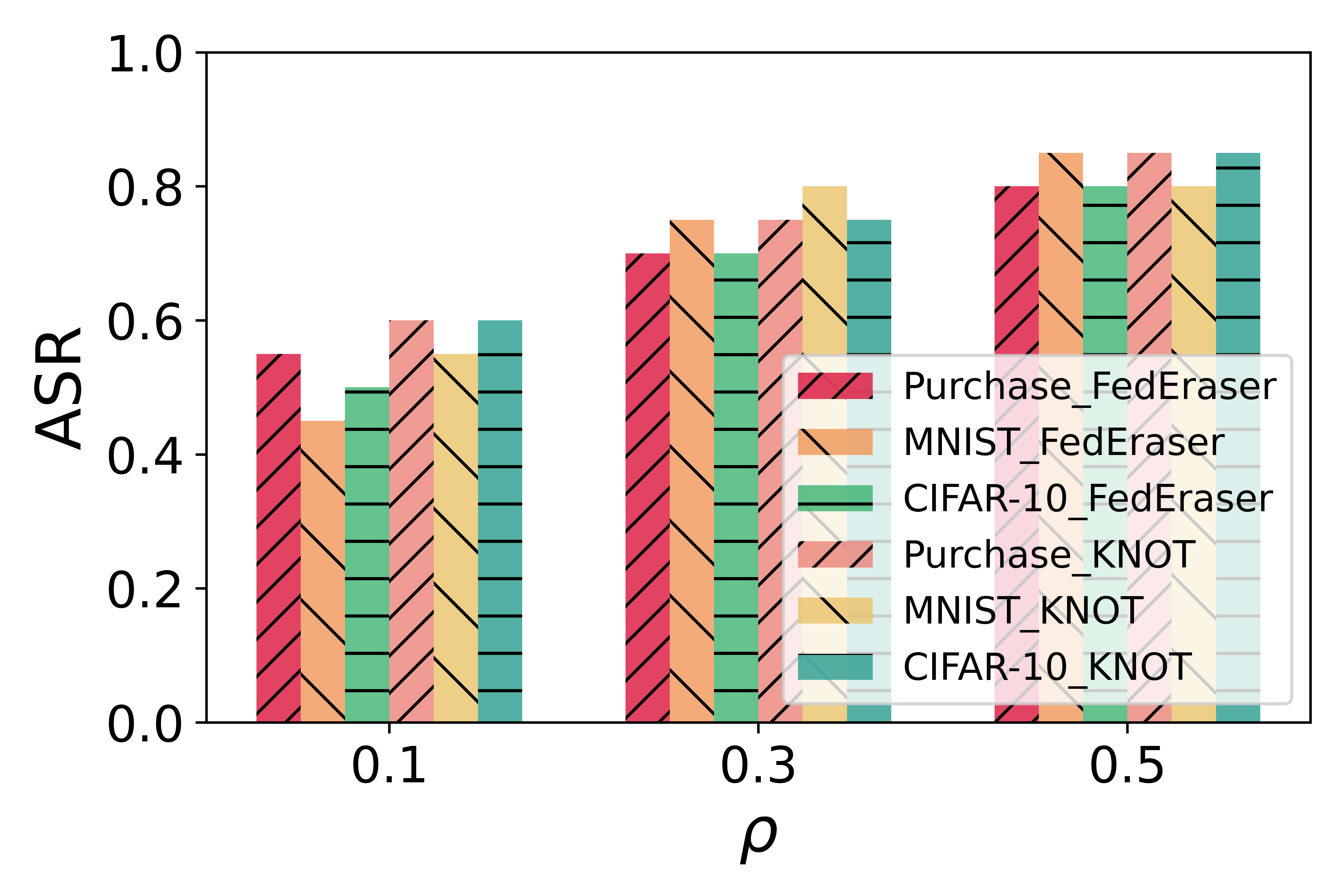
Figure 1: ASR of baseline defenses against FedMUA.
Experimental Results
The paper demonstrates FedMUA's capability through extensive experiments on multiple datasets with varying levels of complexity, such as Purchase and CIFAR-10, under different federated unlearning frameworks like FedEraser and KNOT. FedMUA achieves an attack success rate (ASR) of up to 80% by triggering a minimal 0.3% of malicious unlearning requests. This highlights the severe risk posed by malicious unlearning requests in federated learning systems. The study also evaluates ASR under various configurations, noting that simpler datasets, such as MNIST, show a lower attack success rate due to their reduced complexity and better feature learnability.
Defense Mechanism
A novel defense mechanism is proposed to counteract malicious unlearning attacks effectively. This mechanism identifies and dampens the impact of larger-than-average gradient updates, typically indicative of malicious intents, thereby preserving model performance while mitigating unlearning attacks. Visualization of gradient updates shows clear disparities between normal and malicious clients, which forms the basis of this defense strategy.
Implications and Future Directions
The findings underscore a critical vulnerability within federated learning systems, particularly under frameworks that permit data unlearning. The implications are profound for applications in security-critical environments, as malicious requests could lead to erroneous and potentially harmful model predictions. Looking forward, enhancing the robustness of federated learning against such attacks will be paramount. Future work may involve refining defense mechanisms and further exploring the attack space to bolster federated learning's resilience in adversarial settings.
Conclusion
The paper highlights the pressing need to rethink federated unlearning processes within FL frameworks, advancing a pioneering attack strategy that exposes intricate vulnerabilities. The proposed FedMUA serves both as a cautionary tale and a foundation for future work aimed at securing federated learning systems against sophisticated malicious unlearning interventions.