- The paper introduces an xLSTM-SENet system that uses exponential gating and bidirectionality to overcome traditional LSTM memory mixing issues in speech enhancement.
- The paper employs a parallel encoder-decoder architecture to simultaneously denoise magnitude and phase spectra, achieving competitive performance on the VoiceBank+Demand dataset with metrics like PESQ and STOI.
- The paper demonstrates that integrating xLSTM blocks leads to superior performance compared to standard LSTM layers and state-of-the-art models, while also offering scalability for resource-constrained environments.
xLSTM-SENet: xLSTM for Single-Channel Speech Enhancement
The paper, "xLSTM-SENet: xLSTM for Single-Channel Speech Enhancement," explores the application of the Extended Long Short-Term Memory (xLSTM) architecture in single-channel speech enhancement tasks. xLSTM offers linear scalability and addresses memory mixing limitations associated with traditional LSTMs. The research introduces the xLSTM-SENet system, evaluating its performance against state-of-the-art Mamba and Conformer-based models.
Introduction
Speech enhancement (SE) is essential in noisy environments to improve the intelligibility and quality of speech signals. While Conformer-based models have shown superior SE performance on the VoiceBank+Demand dataset, their scalability is limited by input sequence length due to the quadratic complexity of attention mechanisms. Alternatively, RNNs and LSTMs offer linear scalability but face challenges regarding memory management and parallelization.
The xLSTM architecture enhances LSTMs by integrating exponential gating, matrix memory, and bidirectionality, thus removing memory mixing without compromising complexity or efficiency.
Method: xLSTM-SENet Architecture
The xLSTM-SENet utilizes an encoder-decoder structure that integrates the xLSTM blocks into the magnitude-phase spectrum (MP-SENet) architecture, focusing on parallel denoising of both magnitude and phase spectra.
Figure 1: Overall structure of our proposed xLSTM-SENet with parallel magnitude and phase spectra denoising.
Model Details
- Feature Encoder: Utilizes consecutive convolutional blocks and dilated DenseNets to enhance feature representation. This setup aims at reducing computational complexity by halving the frequency dimension.
- xLSTM Blocks: Each block comprises time and frequency components with bidirectional mechanisms to efficiently capture intricate temporal and frequency dependencies.
- Decoders: The system features separate decoders for the magnitude mask and wrapped phase spectrum, facilitating precise reconstruction of cleaned speech signals.
Results and Analysis
The proposed xLSTM-SENet was tested on the VoiceBank+Demand dataset and compared against several existing SE models. The experimental setup utilized 2-second audio crops and downsampling to $\SI{16}{kHz}$ for efficiency, with performance evaluated using PESQ, STOI, CSIG, CBAK, and COVL metrics.
xLSTM-SENet demonstrated competitive performance with established Mamba and Conformer models, specifically excelling with a configuration of four TF-xLSTM blocks.
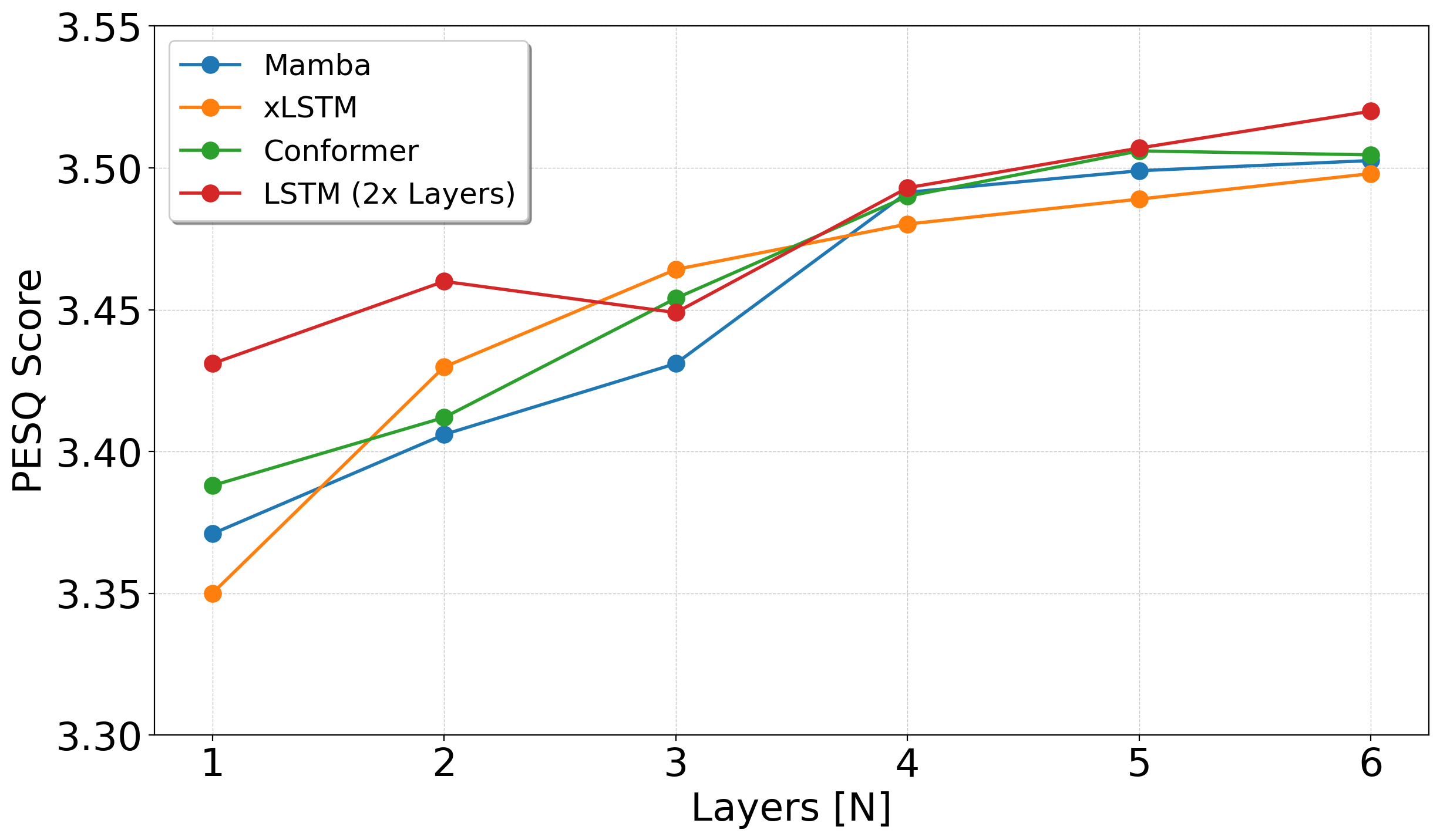
Figure 2: Scaling results on the VoiceBank+Demand dataset. The smallest (N=1) and largest (N=6) models are $\SI{1.37}{M}$ and $\SI{2.94}{M}$ parameters, respectively.
Ablation Study
Key findings from the ablation study highlighted the significance of the expansion factor, biases in layer normalization, and bidirectionality to xLSTM's efficacy. Exponential gating was observed to enhance performance marginally over sigmoid gating.
Comparison with LSTM
Experiments comparing plain LSTM blocks to xLSTM blocks showed that clustered xLSTM blocks outperform standard LSTM layers due to the additional matrix memory and exponential gating capabilities.
Conclusion
The xLSTM architecture proved viable for single-channel speech enhancement, displaying competitive or superior results to existing Mamba and Conformer models across different sizes and configurations. The enhancements in memory management and architectural design choices contribute to its effectiveness, with the xLSTM-SENet2 model outperforming existing state-of-the-art systems on benchmark datasets.
In terms of future development, the integration of xLSTM in resource-constrained environments like hearing aids and its scalability in larger configurations could foster further exploration and optimization in speech enhancement technologies.

