- The paper introduces a replication of OpenAI’s o1 model by merging reinforcement learning and MCTS to enhance System-2 reasoning in coding tasks.
- It employs a Test Case Generator trained with SFT and DPO, achieving an 89.2% pass rate to ensure robust code evaluation.
- The framework refines pseudocode into executable code, addressing challenges in reward generalization and world model encoding.
o1-Coder: An o1 Replication for Coding
The paper "o1-Coder: an o1 Replication for Coding" presents a technical report that seeks to replicate OpenAI's o1 model with a primary focus on coding tasks. The authors introduce a novel framework integrating reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to bolster the model's System-2 thinking abilities, facilitating structured reasoning akin to higher-order cognitive functions.
Framework and Architecture
The framework implemented in the o1-Coder encompasses several crucial components to achieve System-2 reasoning capabilities. The core elements include a Test Case Generator (TCG), MCTS for generating reasoned code data, and iterative policy model fine-tuning that transitions from pseudocode generation to executable code production. The layered approach involves training the TCG to ensure the robustness of generated code by applying standardized test cases.

Figure 1: o1 replication efforts: upper part from academic institutions and open-source communities, and lower part from the industry.
The intricate framework further defines the coding tasks to explore RL's potential in generating and refining reasoning datasets—particularly pertinent since coding entails methodical, logical problem-solving. A key component is the dual-action strategy detailed as "think before acting" and "think while acting"—the former producing a full pseudocode outline before implementation, which was selected for its adaptability and controlled granularity.
Methodology
The methodology unfolds through a multifaceted process tailored for efficient code generation using self-play RL. The following subsections detail each component:
Test Case Generator Training
The TCG, a pivotal part of the framework, is tasked with generating test cases that define the efficacy of code outputs. Through both supervised fine-tuning (SFT) and Direct Preference Optimization (DPO), the TCG demonstrates enhanced reliability in generating quality test cases, reaching a performance of 89.2% pass rate post-DPO.
Reasoning-enhanced Code Data Synthesis
The MCTS strategy plays a critical role here, synthesizing data with reasoned pathways, evaluating the quality of code's final state using measures such as compilation success and test case pass rates. The pseudocode-grounded approach emphasizes refining logical structures prior to execution, demonstrated to significantly enhance the quality of generated code despite the initial decrease in Pass@1 metrics.

Figure 3: Generated example code with pseudocode CoT.
Reinforcement Learning Framework
Reinforcement learning is employed to guide the language-augmented Markov Decision Process (MDP), where the action space and state space are represented as sequences of tokens. This formalism is leveraged to refine policy models through RL based on both process rewards—facilitated by the Process Reward Model (PRM)—and final outcome rewards. The aggregate reward function combines these metrics, guiding iterative reinforcement learning loops for refined policy adaptations.
Discussion and Implications
Maximizing Computation-Intelligence Conversion
The analysis posits a pivotal shift towards optimal data utilization over model complexity, resonating with the trajectory observed in the broader AI research context where data scarcity challenges are addressed through RL and innovative data synthesis methodologies.
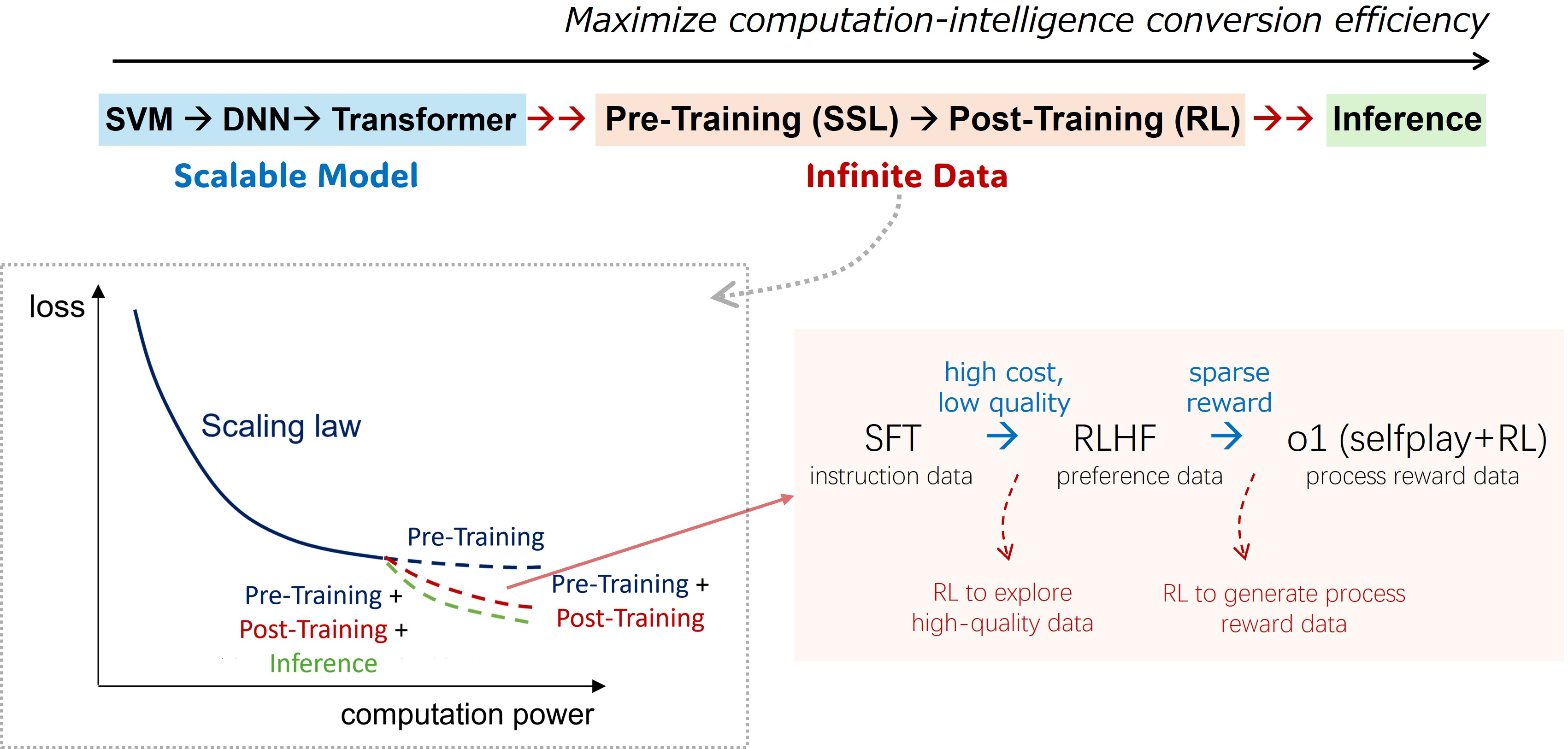
Figure 5: The trend towards maximizing computation-intelligence conversion efficiency.
Beyond Human Data Constraints
A forward-looking perspective advocates transcending limitations of human-recorded data by utilizing RL to traverse underlying thought processes, hinting at novel cognitive processes potentially developing beyond language constraints.
System-2 Integration Opportunities
The self-play RL framework enables broader System-2 task resolution, expanding potential applications across previously System-1-centered tasks such as reward modeling and machine translation, promising advancements evidenced in current initial explorations.
Anticipated Challenges: World Model Encoding
Significant challenges persist regarding reward function generalization and environment state updates for planning-based reasoning. These challenges emphasize the need for effective world model construction to efficiently translate o1-like reasoning models into tangible real-world applications, requiring further innovation in interactive and generative content environments.
Conclusion
The research presented in "o1-Coder" signifies a comprehensive stride towards replicating OpenAI's o1 model, particularly in coding-centric tasks. It highlights strategic implementations that blend RL with reasoning frameworks to empower existing models with System-2 capabilities, establishing a robust foundation for broader exploration and implementation of AI-driven coding tasks with nuanced reasoning challenges.