- The paper introduces a Process Reward Model (PRM) that provides dense, line-level feedback to overcome sparse rewards in reinforcement learning for code generation.
- The methodology integrates PRM for both intermediate reward signals and value initialization, improving benchmark pass rates on LiveCodeBench and InHouseBench.
- Extensive experiments demonstrate that strategic data labeling and reward normalization mitigate model exploitation while enhancing long-horizon code generation.
Process Supervision-Guided Policy Optimization for Code Generation
Introduction to the Research Problem
The paper "Process Supervision-Guided Policy Optimization for Code Generation" addresses the critical challenge of sparsity in reward signals for reinforcement learning (RL) applied to code generation. Conventional RL approaches in this domain rely heavily on unit test feedback, providing rewards only at the completion of code evaluation. This delayed, sparse feedback mechanism significantly hampers the learning efficiency and incremental improvements that a model can achieve. The research introduces a Process Reward Model (PRM) designed to deliver dense, line-level feedback during the code generation process, mimicking the iterative refinement approach of human programmers.
Methodology and Approach
The proposed method integrates dense reward signals via a PRM into the RL framework, enhancing exploration and credit assignment during training. The approach consists of two main components:
- Binary Search-Based Data Labeling: The PRM training data is automatically labeled using a binary search method to identify the first incorrect line in generated code. This enables efficient labeling of code prefixes concerning correctness.
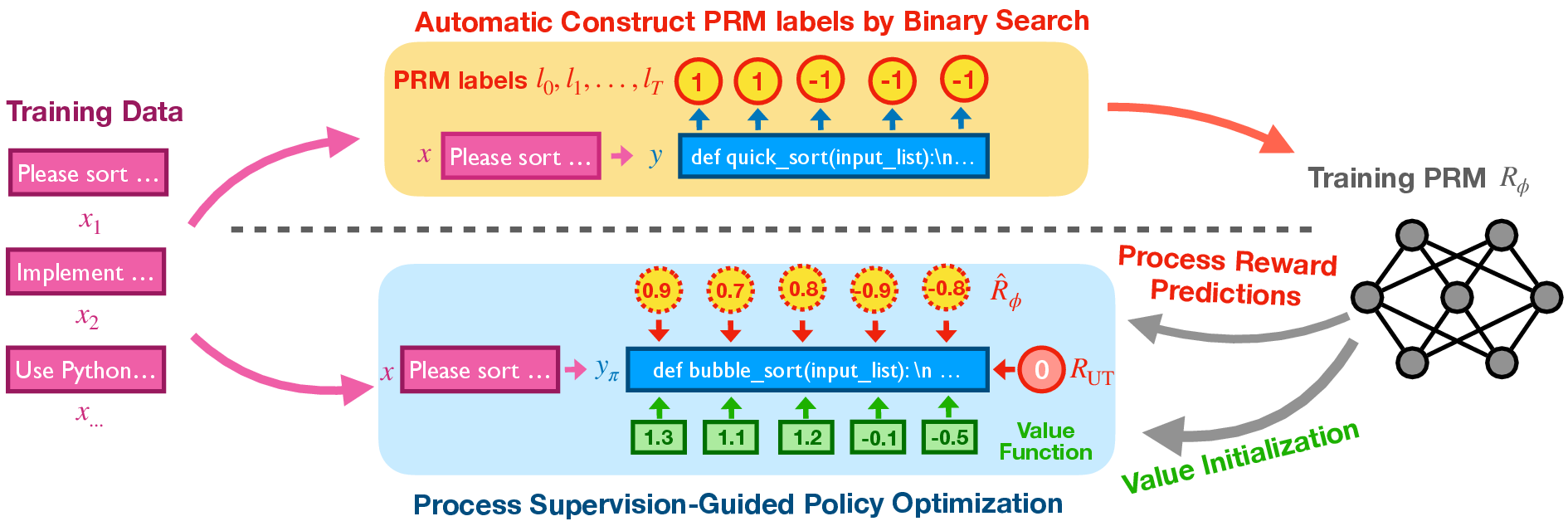
Figure 1: Overview of the method, illustrating the process of data labeling and integration of PRM into RL training.
- PRM Integration into RL Training: The PRM is utilized both as a source for dense rewards and as a tool for initializing the value function in RL algorithms. This dual integration is proposed to significantly boost performance by providing continuous intermediate feedback and stabilizing value function estimates.
Experimental Framework and Results
The research deploys extensive experiments on in-house datasets and benchmarks like LiveCodeBench and an internal benchmark, InHouseBench, to validate the efficiency of PRM integration into RL training. The experimental setup involves fine-tuning an in-house model, Doubao-Lite, initially through Supervised Fine-Tuning (SFT) and subsequently through RLHF (RL with Human Feedback) optimizations.
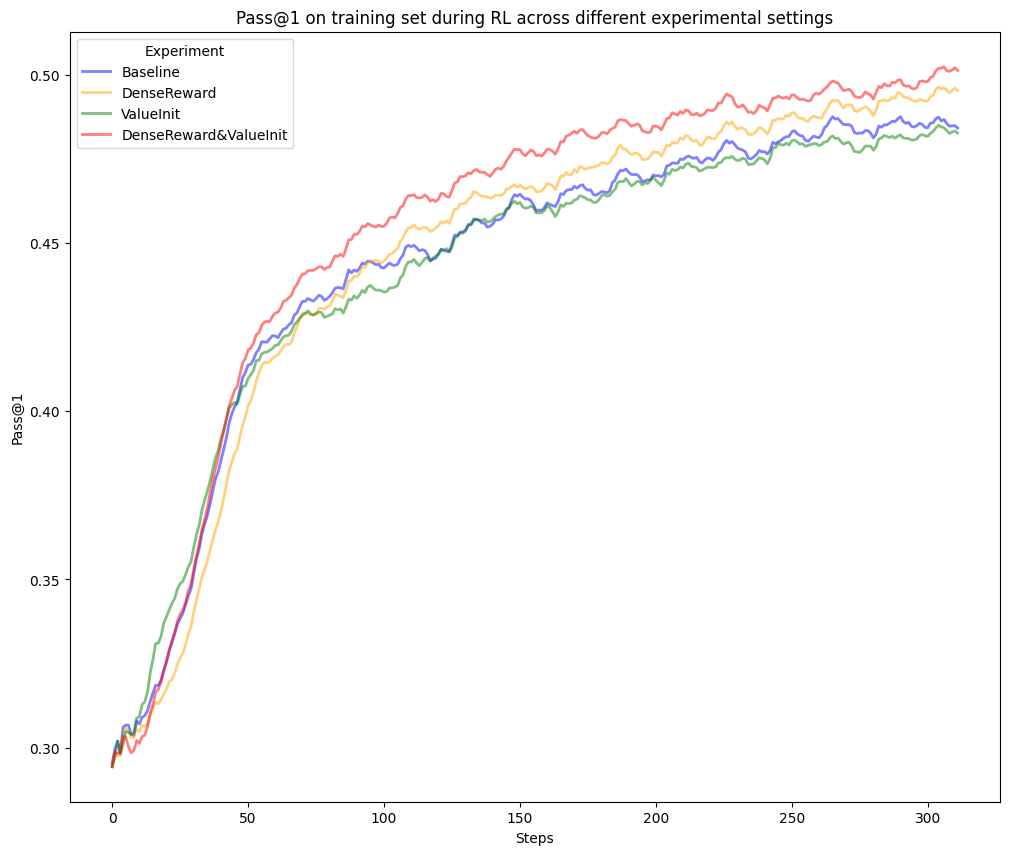
Figure 2: RL training curve comparing various configurations. The DenseReward{additional_guidance}ValueInit setting demonstrates superior performance.
Empirical results indicate that using PRM concurrently as dense rewards and for value initialization leads to significant improvements in pass rates—from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on the internal benchmark. Notably, the PRM integration into RL training enables better performance in long-horizon scenarios by offering granular feedback that refines intermediate decision-making steps.
Key Considerations and Practical Implications
The paper elaborates on crucial implementation aspects necessary for effective PRM integration:
- Data Selection Strategy: The quality of PRM training data critically influences performance. Curated subsets focusing on informative, diverse examples are emphasized over sheer volume.
- Mitigation of Reward Model Hacking: Techniques like reward length normalization and assigning neutral labels to comment lines are employed to prevent policy exploits and ensure true performance enhancements.
Overall, the findings underscore the importance of dense, process-level feedback in RL environments to facilitate more robust code generation models.
Conclusion and Future Directions
The integration of PRM for enhanced process supervision effectively addresses the inherent limitations of sparse reward signals in conventional RL frameworks for code generation. The methodology not only improves performance in generating syntactically and functionally correct code but also offers insights into better handling complex, long-horizon coding tasks. Future work can explore scaling the PRM approach to broader domains beyond code generation, further enhancing AI’s capabilities in structured reasoning tasks.

