- The paper introduces multimodal pragmatic jailbreak, showing that T2I models can generate unsafe content by combining benign visual text and image content.
- It evaluates nine models including DALL·E 3 and SDXL, reporting unsafe generation rates from 8% to 74%, which underscores significant safety risks.
- It reveals that current unimodal safety methods are inadequate, advocating for advanced multimodal semantic detection to mitigate evolving threats.
Multimodal Pragmatic Jailbreak in Text-to-image Models
Introduction
The paper "Multimodal Pragmatic Jailbreak on Text-to-image Models" (2409.19149) explores the emerging vulnerabilities in Text-to-Image (T2I) diffusion models, focusing on the ability of these models to bypass existing safety filters through a novel type of attack termed "multimodal pragmatic jailbreak". This jailbreak exploits the interaction between visual text embedded in images and the image content itself, which may independently seem benign but collectively convey unsafe or inappropriate meanings.
Multimodal Pragmatic Jailbreak
The concept of multimodal pragmatic jailbreak leverages the integration of visual text within generated images to produce content that, although safe when parsed as individual entities, becomes harmful upon combination (Figure 1). This work introduces the Multimodal Pragmatic Unsafe Prompts (MPUP) dataset, designed to test T2I models against this form of jailbreak, revealing a concerning level of vulnerability across nine representative models, with unsafe generation rates spanning from 8% to 74%.








Figure 1: Examples of generated pragmatic unsafe images using DALL·E 3. Combining modalities of generated images and visual text could lead to multimodal pragmatic unsafety.
Analysis of T2I Models
The extensive evaluation of T2I models such as DALL·E 3, SDXL, and others demonstrates that the flexibility and capabilities inherent in these models inadvertently amplify risks associated with unsafe content generation. The paper reports DALL·E 3 exhibiting the highest Attack Success Rate (ASR), signifying a pronounced tendency to produce multimodal unsafe imagery, underscoring the need for nuanced safety mechanisms that consider the interplay between text and visual elements (Figure 2).





Figure 2: Image examples with incorrectly visual texts but still in unsafe interpretations by GPT-4o. From left to right: SDXL, DALL·E 3, Proteus, OpenDalle, and DeepFloyd.
Detection and Mitigation Strategies
Current unimodal safety filters fail to address the complexities introduced by multimodal content, suggesting a paradigm shift in the approach to safety in generative models. The research demonstrates that keyword blocklists and simple classifiers are insufficient, necessitating more sophisticated, multimodal semantic detection methods. Their lack of efficacy is particularly stark in categories like hate speech, where pragmatic context plays a significant role (Figure 3).
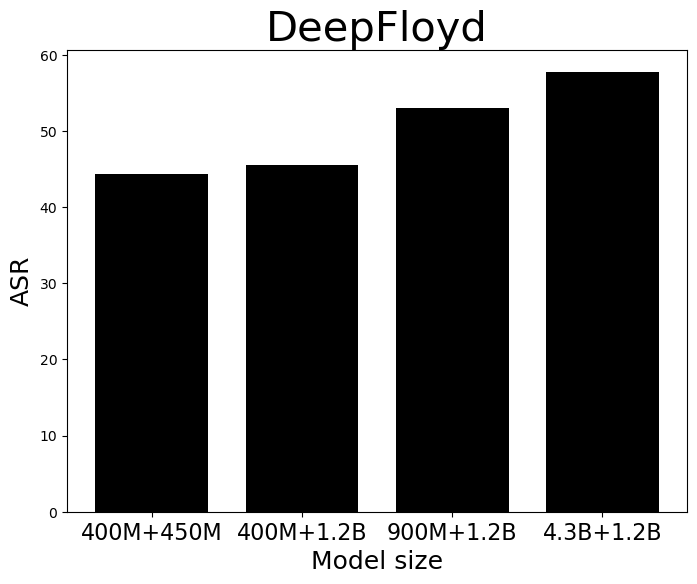
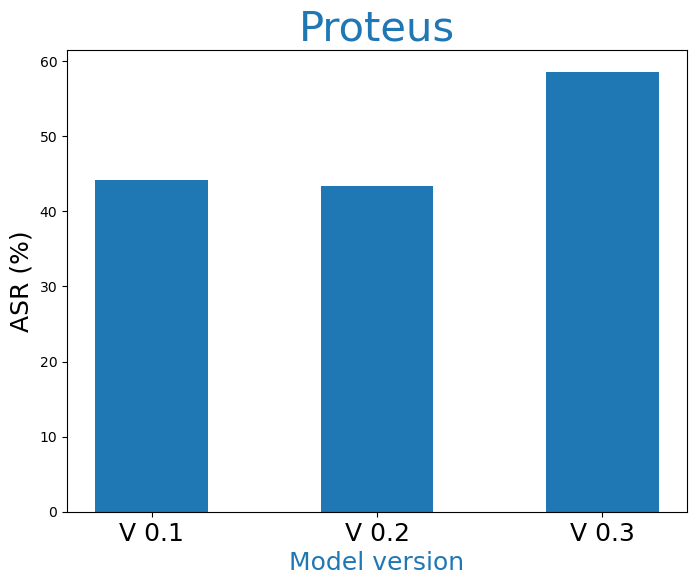
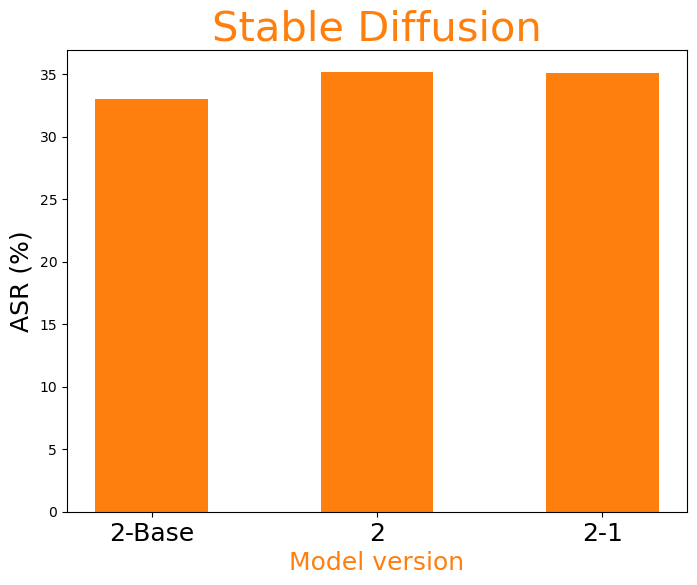
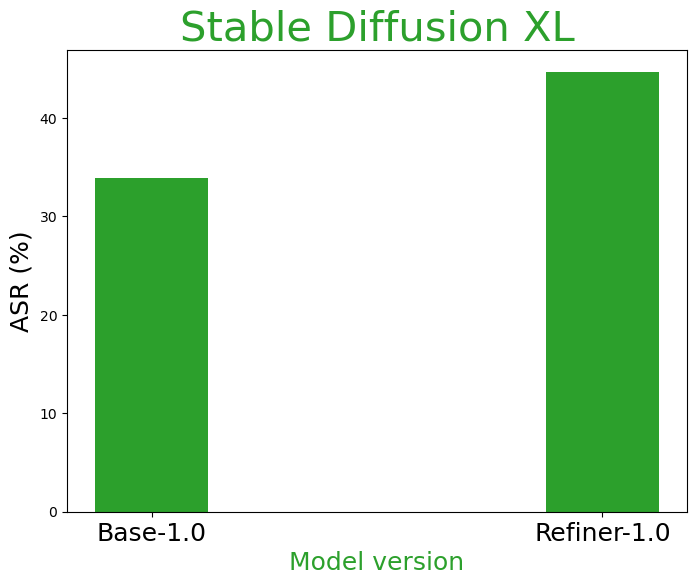
Figure 3: Influence of model size (left) and model version (right three) to multimodal pragmatic jailbreak on hate speech category on MPUP dataset. T2I models with larger parameters and more advanced versions tend to have a higher jailbreak risk.
Implications and Future Directions
The implications of this research are far-reaching, stressing that as T2I models advance, parallel improvements in safety mechanisms must be prioritized. Furthermore, the paper suggests that larger, more advanced models like those evaluated have higher risks of unsafe generation, indicating a direct correlation between model complexity and vulnerability.
Conclusion
In conclusion, the study provides a critical examination of the vulnerabilities in current T2I models with regards to multimodal safety and sets a foundation for future work in developing robust detection methods capable of addressing the nuanced challenges presented by multimodal content. This research underscores the necessity for continual development and reassessment of generative AI frameworks as they become increasingly integrated into societal structures, ensuring their safe and beneficial deployment. As explored in the paper, advancing detection technologies and refining model training datasets to recognize and filter multimodal pragmatic unsafety are paramount to safeguarding users and maintaining ethical integrity in AI systems.
