- The paper introduces a robust pipeline that leverages LLMs to generate sequential lyrics from bag-of-words data combined with rich metadata.
- Methodology employs advanced prompt engineering on LLMs by conditioning on genre, mood, and frequency information to maintain stylistic and structural fidelity.
- Quantitative analysis reveals that the reconstructed lyrics closely mirror original statistical and stylistic properties, supporting scalable and legal MIR research.
Lyrics Reconstruction from Bag-of-Words with LLMs: The LyCon Framework
Introduction
The proliferation of lyric-based MIR and NLP research is severely constrained by the legal restrictions on directly distributing copyrighted lyrics. Most public datasets circumvent this by providing only partial representations such as Bag-of-Words (BoW), or metadata, impeding tasks that require full sequential text. "LyCon: Lyrics Reconstruction from the Bag-of-Words Using LLMs" (2408.14750) proposes a robust pipeline for reconstructing lyrics from BoW representations, enriched by track-level metadata, utilizing LLM capabilities. The authors publish the LyCon dataset—a large collection of reconstructed, copyright-free lyrics aligned with extensive metadata, opening the door for advanced symbolic MIR and generative research without legal risk.
Research leveraging datasets like musiXmatch exploits their alignment with metadata-rich databases such as the Million Song Dataset (MSD), enabling genre classification, mood detection, and cover song identification from lyric unigrams. However, the absence of ordered text prohibits sequential analysis, n-gram modeling, lyric generation, and stylometric examination. Recent studies underscore that many computational analyses (e.g., bigram/trigram statistics, syntactic structure) and downstream applications in music cognition or creative AI are blocked by this limitation.
The LyCon approach seeks to reconstruct plausible lyric sequences for BoW songs, while preserving key song properties, thus enabling these lines of research.
Methodology
The central objective is to generate lyric sequences conforming to the original BoW vocabulary and structural, stylistic, and semantic priors derived from metadata. Key steps include:
- Vocabulary Extraction: Each song's BoW is obtained from musiXmatch, listing words with frequencies.
- Metadata Conditioning: Each song is further annotated with its MSD ID, title, artist, genre (AllMusic), and musically derived mood labels (Deezer; valence/arousal scores).
- Prompt Engineering for LLMs: Using GPT-4o, prompts are formulated to direct lyric generation with explicit constraints: genre, artist, BoW vocabulary sorted by frequency, song title, and computed mood.
The mood is parameterized in a 2D valence-arousal space, with the angle θ from the positive x-axis partitioned into canonical emotion categories, as shown in Figure 1.
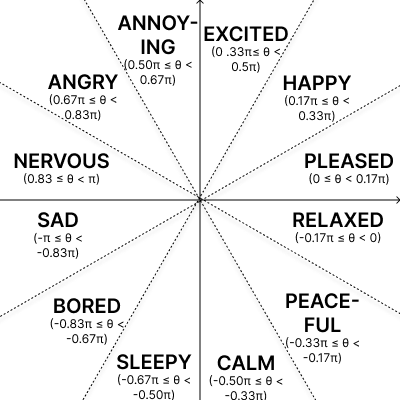
Figure 1: Table illustrating valence/arousal-based mapping of θ values to mood categories for lyric conditioning.
- Prompted Example: Figure 2 illustrates an LLM prompt for the song "Time Is Running Out" (Muse), including the genre, artist, mood (derived from θ), and BoW.
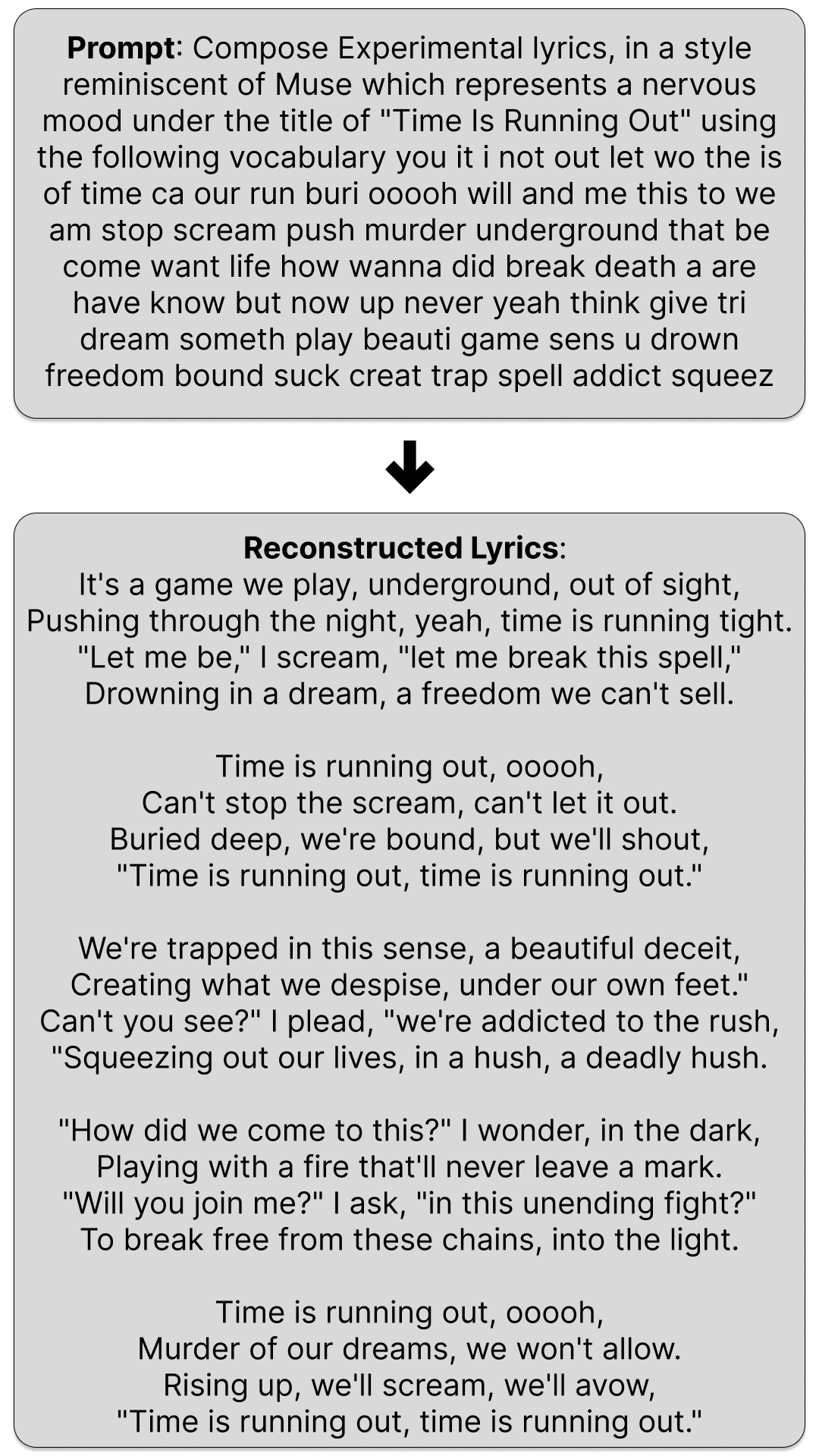
Figure 2: Lyric reconstruction prompt for Muse's 'Time Is Running Out', highlighting genre and valence/arousal-based mood conditioning.
The process is fully automatic for any song tracked in the three datasets, generating 7,863 lyric reconstructions, each mapped to an MSD ID.
Dataset: LyCon
LyCon provides reconstructed lyrics for thousands of MSD tracks with comprehensive metadata, accessible for academic use. Each lyric aligns with genre, artist, and mood annotations, enabling:
- Conditional lyric generation
- Genre and mood-based symbolic MIR studies
- Cross-modal and transfer learning with audio, metadata, and reconstructed text
This removes the dependency on access-limited or proprietary lyric corpora, shifting the field toward reproducible, open research.
Quantitative Analysis
Comparison of LyCon lyrics with their original (copyrighted) counterparts shows:
- Statistical Alignment: Mean counts of words, lines, and sections per song are similar for LyCon and ground truth, indicating the LLM's capacity to reconstruct plausible song structures.
- n-gram Coverage: LyCon lyrics exhibit robust bigram and trigram diversity, crucial for syntactic and semantic research, though unique unigram count is markedly lower.
- Stylistic/Aesthetic Fidelity: The abstract-to-concrete word usage ratio in LyCon is only slightly higher—original lyrics favor concreteness, a hallmark of poetic aesthetic, but the difference is small.
These findings demonstrate that LLM-reconstructed lyrics approximate original textual artifacts in statistical and stylistic metrics, providing a practical substrate for downstream analyses.
Theoretical and Practical Implications
The work establishes a precedent for reconstructing sequenced text datasets from BoW and metadata with LLMs, potentially impacting multiple domains:
- Fair Use and Copyright: LyCon enables experimental research in lyric analysis, generation, and hybrid music-lyric modeling without copyright risk.
- Scalable Conditional Text Generation: Prompt conditioning on fine-grained metadata (genre, artist, mood) allows generation of highly specific, context-aware lyrics, facilitating both generative and discriminative modeling.
- Benchmark for Lyric-Centric Tasks: The dataset supports evaluation of MIR and NLP systems on tasks previously limited by access to original lyrics, such as rich emotion analysis, lyric translation alignment, and inter-modal association.
Future Directions
The LyCon methodology can be extended to:
- Larger or more diverse BoW lyric archives.
- Fine-tuning LLMs for improved stylistic fidelity and diversity, perhaps guided by additional musicological constraints.
- Multi-modal generative frameworks encompassing lyric, audio, and visual modalities.
- Cross-lingual lyric reconstruction and comparative cultural studies.
Conclusion
"LyCon: Lyrics Reconstruction from the Bag-of-Words Using LLMs" (2408.14750) demonstrates that LLMs, when coupled with BoW lyric data and fine-grained metadata, can reliably reconstruct lyrics suitable for advanced research. The release of the LyCon dataset ensures that the symbolic MIR community can progress beyond copyright constraints, leveraging a resource that supports both generative and analytic workflows, while preserving statistical and stylistic properties relevant to lyric-based inquiry.