MoE-LPR: Multilingual Extension of Large Language Models through Mixture-of-Experts with Language Priors Routing
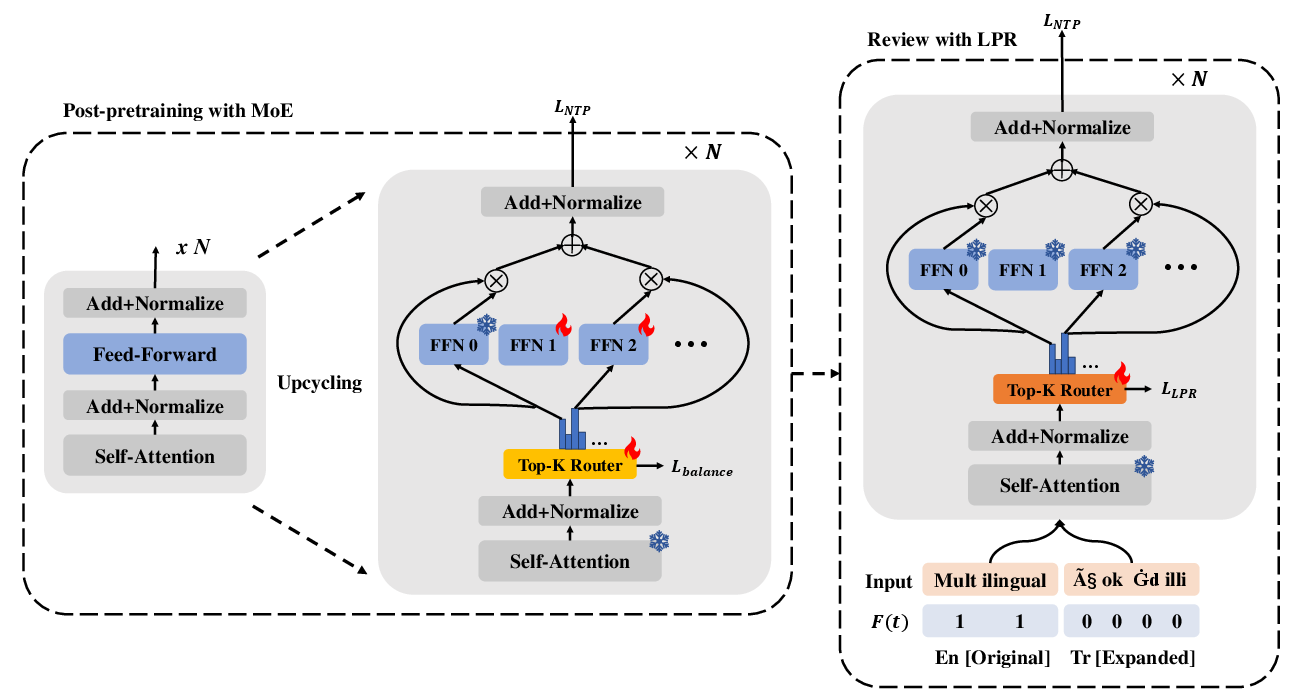
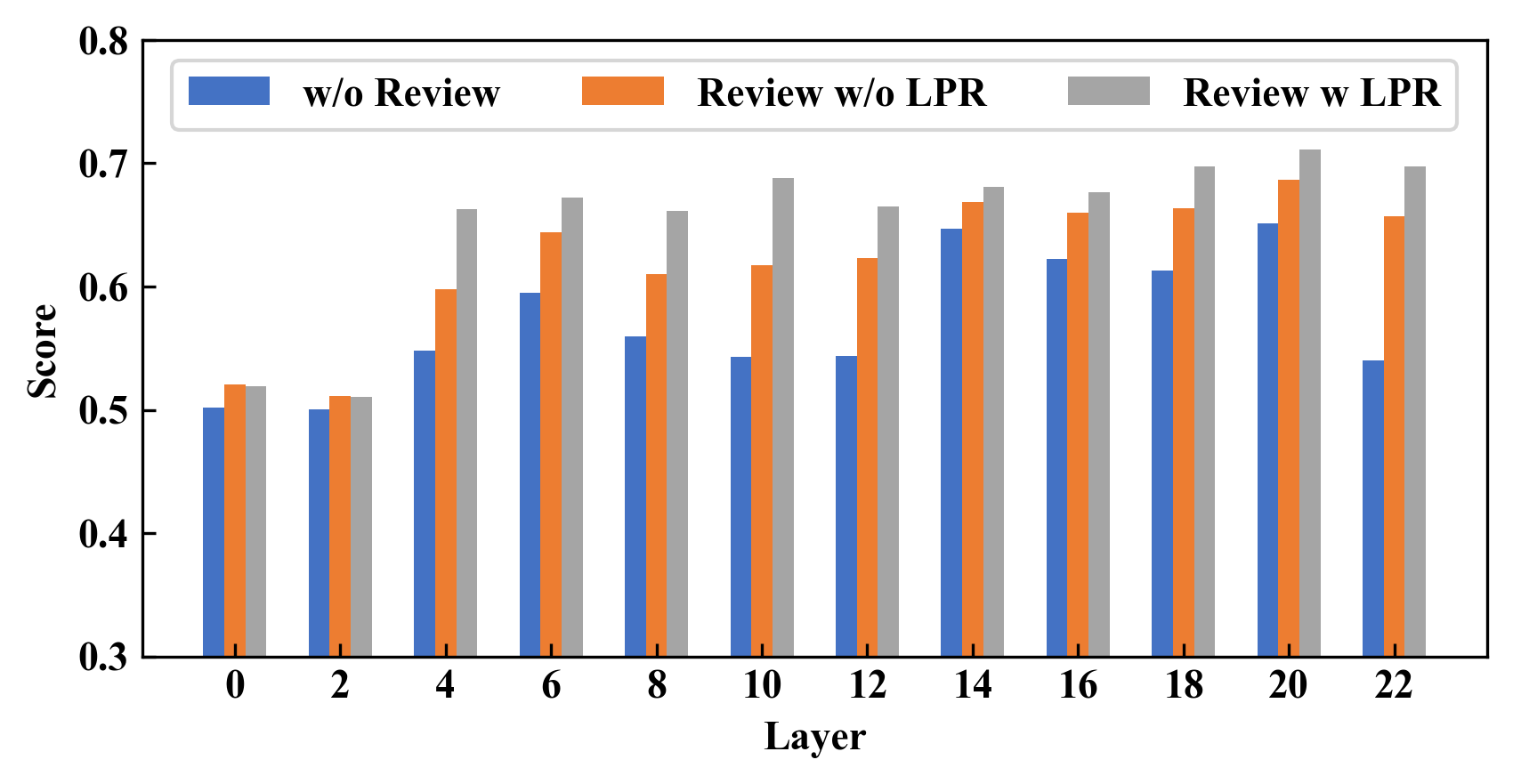
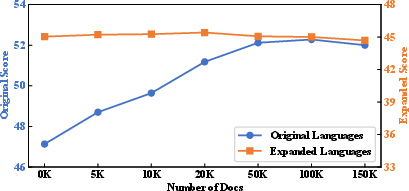
Abstract: LLMs are often English-centric due to the disproportionate distribution of languages in their pre-training data. Enhancing non-English language capabilities through post-pretraining often results in catastrophic forgetting of the ability of original languages. Previous methods either achieve good expansion with severe forgetting or slight forgetting with poor expansion, indicating the challenge of balancing language expansion while preventing forgetting. In this paper, we propose a method called MoE-LPR (Mixture-of-Experts with Language Priors Routing) to alleviate this problem. MoE-LPR employs a two-stage training approach to enhance the multilingual capability. First, the model is post-pretrained into a Mixture-of-Experts (MoE) architecture by upcycling, where all the original parameters are frozen and new experts are added. In this stage, we focus improving the ability on expanded languages, without using any original language data. Then, the model reviews the knowledge of the original languages with replay data amounting to less than 1% of post-pretraining, where we incorporate language priors routing to better recover the abilities of the original languages. Evaluations on multiple benchmarks show that MoE-LPR outperforms other post-pretraining methods. Freezing original parameters preserves original language knowledge while adding new experts preserves the learning ability. Reviewing with LPR enables effective utilization of multilingual knowledge within the parameters. Additionally, the MoE architecture maintains the same inference overhead while increasing total model parameters. Extensive experiments demonstrate MoE-LPR's effectiveness in improving expanded languages and preserving original language proficiency with superior scalability. Code and scripts are freely available at https://github.com/zjwang21/MoE-LPR.git.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.