- The paper introduces CodeJudge-Eval, a novel benchmark that evaluates LLMs on code judgment rather than code generation.
- It employs diverse test cases and filtering mechanisms to challenge models in detecting errors and assessing genuine code understanding.
- Experimental results show that even advanced LLMs struggle with code judging, highlighting a need for improved training and architecture.
CodeJudge-Eval: Assessing LLMs as Code Judges
Introduction
The introduction of CodeJudge-Eval represents a shift in evaluating the code understanding capabilities of LLMs from code generation to code judgment. While traditional benchmarks like HumanEval and APPS focus on generating functioning code from natural language prompts, they often fail to encompass full comprehension due to limitations like incomplete test cases and susceptibility to data leakage. CodeJudge-Eval addresses these gaps by evaluating LLMs' abilities to judge the correctness of pre-existing solutions, offering a more nuanced understanding of the models' capabilities in code analysis and understanding. This novel benchmark probes deeper into LLMs' proficiency by positioning them as adjudicators of code correctness.
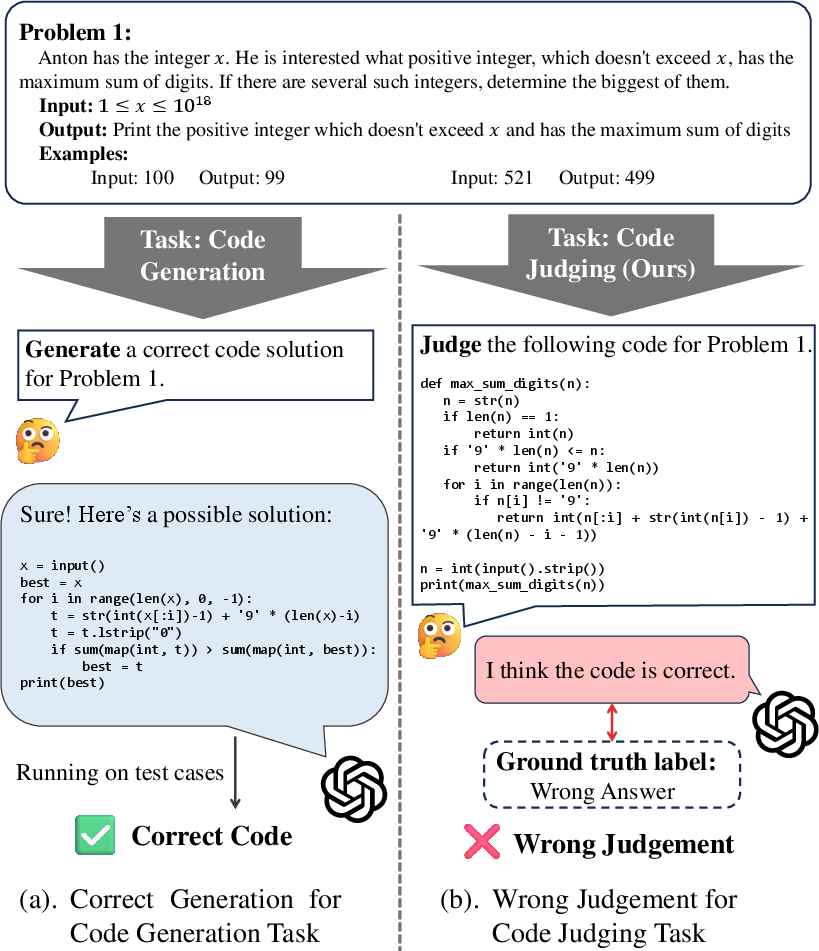
Figure 1: Comparing code generation with code judging task, we observe that a model's ability to generate correct code does not necessarily imply it can accurately judge other codes for the same problem.
Benchmark Design and Implementation
CodeJudge-Eval is meticulously designed to include a wide variety of problems sourced from the APPS test set and employs a fine-grained judging system. The benchmark features diverse difficulty levels and error types, challenging models to discern between correct and erroneous solutions without relying heavily on memorization. The evaluation pipeline includes generating potential solution codes using multiple LLMs, followed by rigorous execution against a comprehensive set of test cases to determine accuracy and identify the nature of any errors.
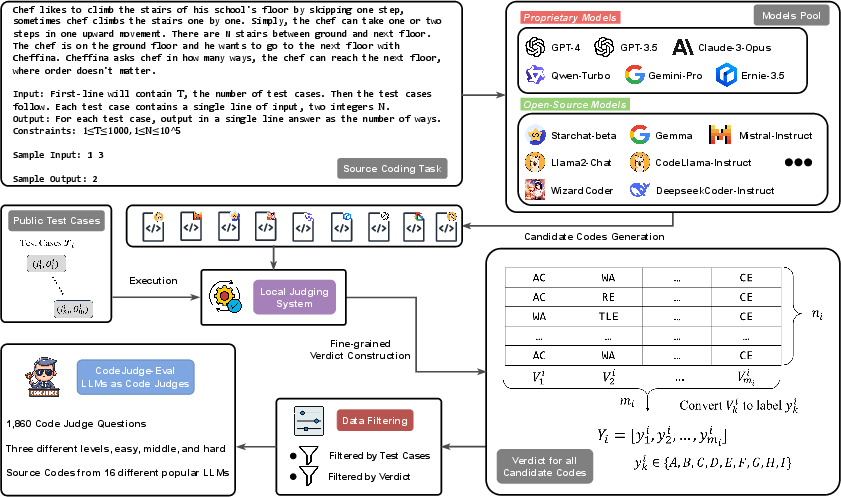
Figure 2: An overview of our pipeline for constructing the CodeJudge-Eval benchmark.
Filtering mechanisms are applied to ensure the robustness of the dataset, particularly focusing on the number of test cases per problem to eliminate those insufficiently challenging for effective error detection. This filtering enhances the integrity of the benchmark by preventing models from defaulting to memorization strategies, thus aligning with the core objective of genuine code understanding evaluation.
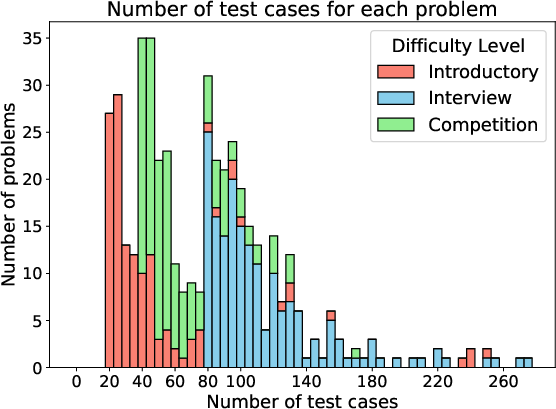
Figure 3: A stacked histogram on the number of test cases in the filtered problems. Different filtering thresholds are applied based on different difficulty.
Experimental Evaluation
The empirical results from applying CodeJudge-Eval highlight the substantial challenges it poses. Proprietary LLMs like GPT-4o and Claude-3.5-Sonnet, while outperforming many open-source models, still manifest significant gaps in code judgment performance, with macro F1 scores peaking modestly even on simpler tasks. These findings underscore a disconnect between code generation proficiency and code comprehension.
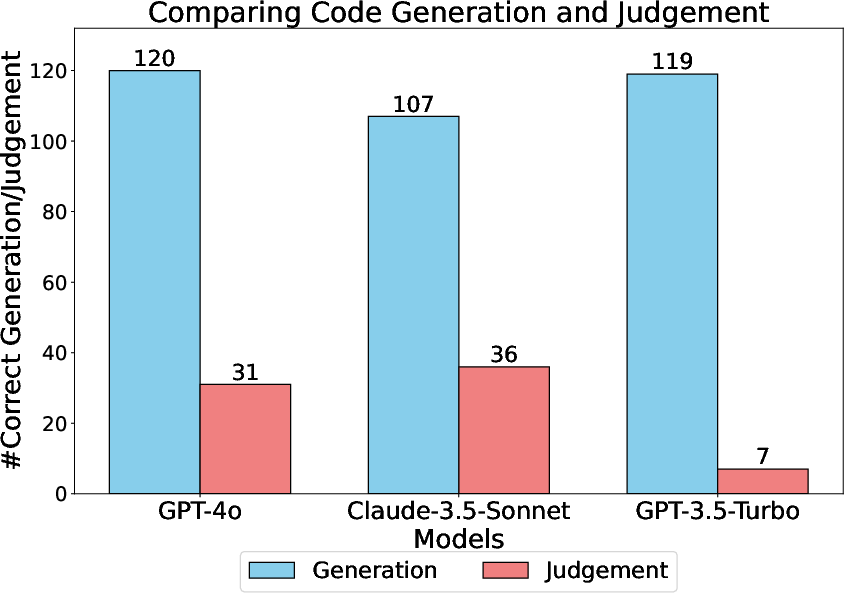
Figure 4: Analyzing whether the ability to generate correct code for a task guarantees the ability to judge the correctness of other codes for the same tasks.
Moreover, the data suggests that increasing model parameters does not linearly correlate with improved judgment accuracy, indicating that architectural and training approach aspects need re-evaluation to bridge these comprehension gaps effectively.
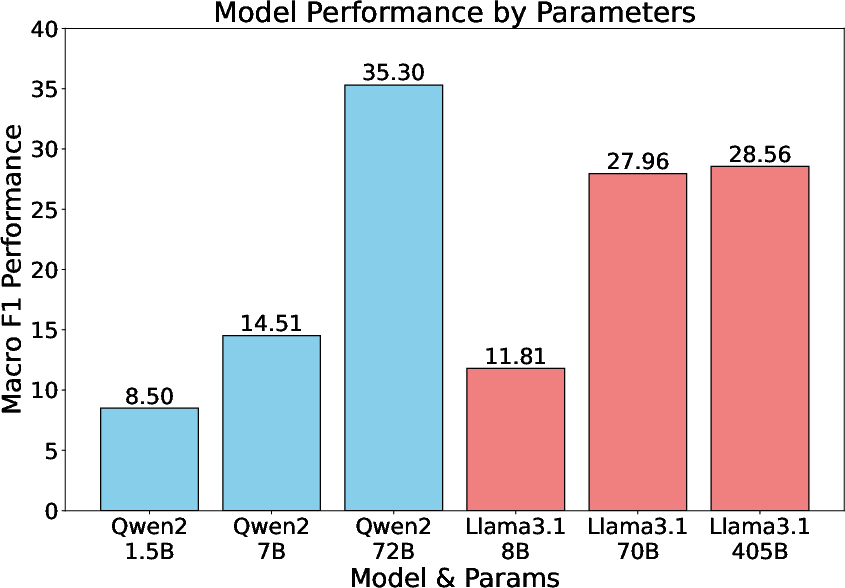
Figure 5: Scaling the number of models' parameters on our CJ-Eval Easy.
Implications and Future Work
CodeJudge-Eval provides a new lens through which the capabilities of LLMs can be assessed, emphasizing the need for refined training paradigms that better integrate understanding within model architectures. The benchmark's design inherently discourages memorization by expanding the volume and variety of solutions evaluated, demanding a more fundamental understanding of code logic and execution paths.
Remediation lies in evolving training data and methodologies to incorporate more nuanced comprehension tasks beyond code generation, potentially steering models toward enhanced reasoning abilities.
Conclusion
CodeJudge-Eval reveals an unexplored frontier in AI evaluation, illustrating that current LLMs are yet to achieve comprehensive code understanding. The findings call for continued innovation in LLM architectures and training regimens aimed at fostering genuine comprehension, thus elevating the potential of AI in code-driven applications. As the field progresses, benchmarks like CodeJudge-Eval will be pivotal in guiding the development of truly intelligent systems capable of sophisticated reasoning and judgment.

