- The paper introduces a novel sentence-wise speech summarization framework that bridges ASR and traditional summarization through real-time processing.
- It presents two new datasets—Mega-SSum for English and CSJ-SSum for Japanese—to support extensive and cross-linguistic evaluation.
- The research employs LM-based knowledge distillation to enhance end-to-end models, significantly boosting performance metrics like ROUGE-L and BERTScore.
Sentence-wise Speech Summarization: Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Introduction and Motivation
The field of automatic speech recognition (ASR) has significantly expanded, primarily focusing on generating verbatim transcriptions of spoken language. However, these transcriptions often lack readability due to spoken-style and repetitive expressions. Sentence-wise speech summarization (Sen-SSum) is introduced as a novel paradigm designed to mediate between ASR and traditional speech summarization (SSum). Unlike conventional SSum, which is unsuitable for real-time processing as it typically sums up entire spoken documents at once, Sen-SSum offers real-time, concise summaries post each sentence, bridging a critical gap in efficient spoken content processing.
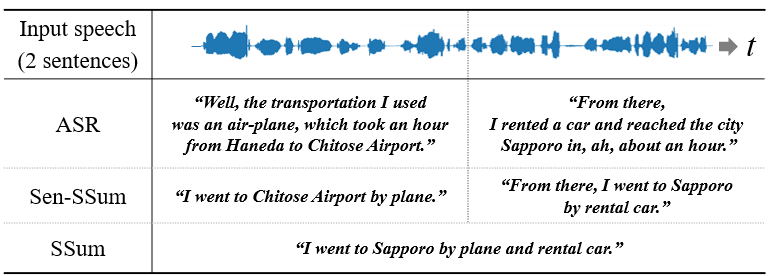
Figure 1: Examples of ASR, Sen-SSum, and SSum. Sen-SSum combines real-time processing and conciseness.
Datasets
The study contributes significantly by introducing two new datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Mega-SSum, a large-scale English dataset, consists of 3.8M synthesized speech samples based on the Gigaword dataset. The use of a multi-speaker text-to-speech model ensures high-quality speech synthesis. In contrast, CSJ-SSum focuses on Japanese language summarization from the Corpus of Spontaneous Japanese, offering a robust cross-linguistic evaluation platform. Such datasets are pivotal in advancing methodologies in Sen-SSum research by providing comprehensive and large-scale resources that reflect both synthesized and real spoken language scenarios.
Methodological Approaches
The Sen-SSum task has been explored using both cascade and end-to-end (E2E) models. Cascade models integrate dedicated ASR and TSum components, leveraging the pre-training benefits on extensive text corpora to ensure robust NLP capabilities. In contrast, E2E models encapsulate the speech-to-summary transformation into a single encoder-decoder architecture, focusing on parameter efficiency and minimizing error propagation inherent in multi-stage processes. However, these models often falter due to the scarcity of annotated speech-summary pair datasets, necessitating innovative training solutions.
Knowledge Distillation Strategy
To enhance the performance of E2E models, the paper proposes a knowledge distillation approach whereby pseudo-summaries created by cascade models serve as additional training inputs for E2E models. This method exploits the cascade model's linguistic prowess to imbue E2E models with richer summarization capabilities without directly acquiring large annotated datasets. The empirical studies demonstrate that this strategy markedly improves E2E model performance, suggesting that linguistic insights can be successfully transferred via pseudo-summaries.
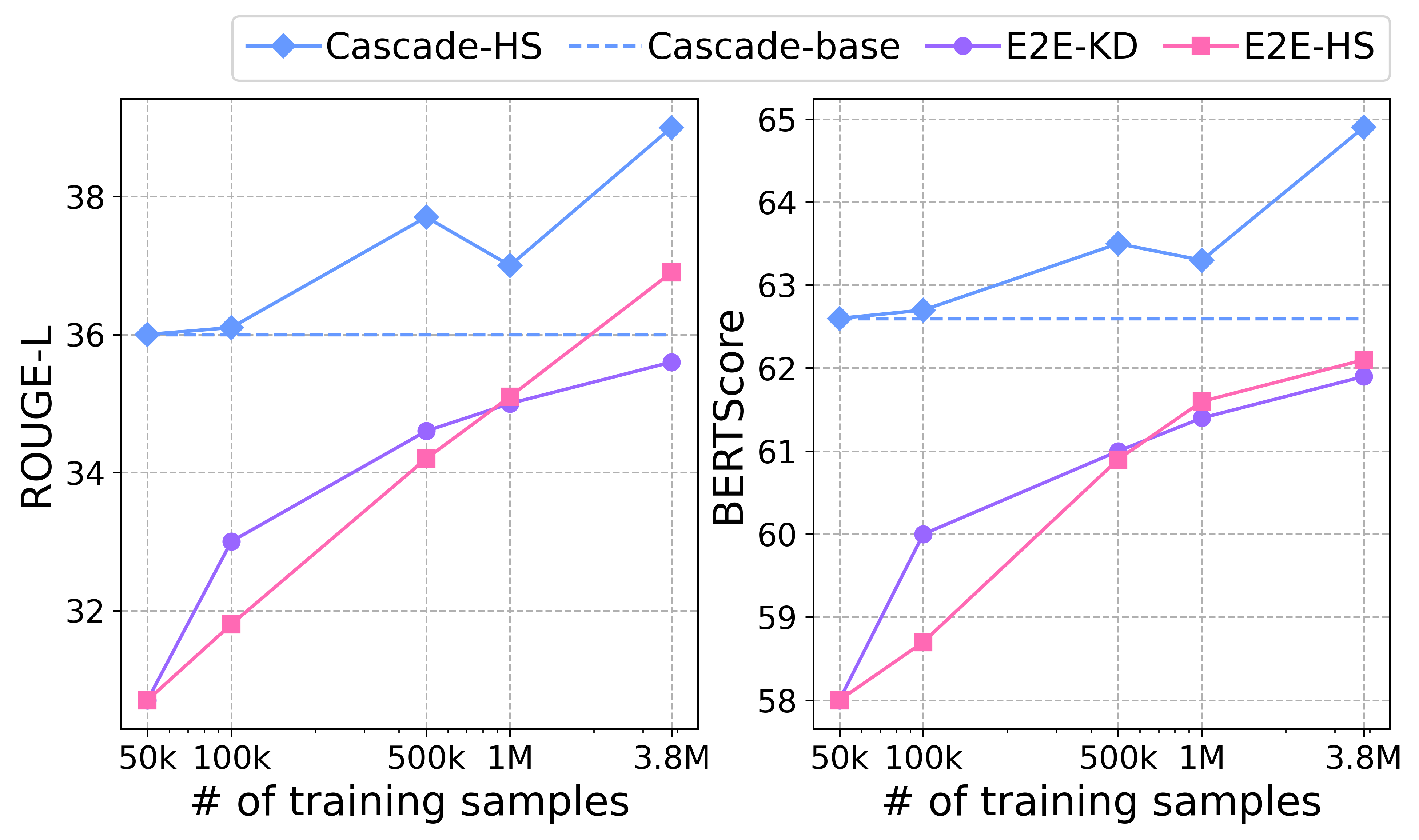
Figure 2: ROUGE-L (uparrow) and BERTScore (uparrow) by cascade and E2E models trained with various numbers of human summaries ``\textsf{
-HS}''.*
Experimental Results
Quantitative analysis using metrics such as ROUGE-L and BERTScore indicates that the cascade model surpasses the baseline E2E models due to superior pre-trained LLM integration. However, application of the pseudo-summary-driven knowledge distillation closes this performance gap significantly, as reflected in the comparable metric scores. A nuanced review through A/B testing with ChatGPT highlights a subjective quality preference towards cascade model outputs, though distillation-driven E2E models gain favor with increased training data.
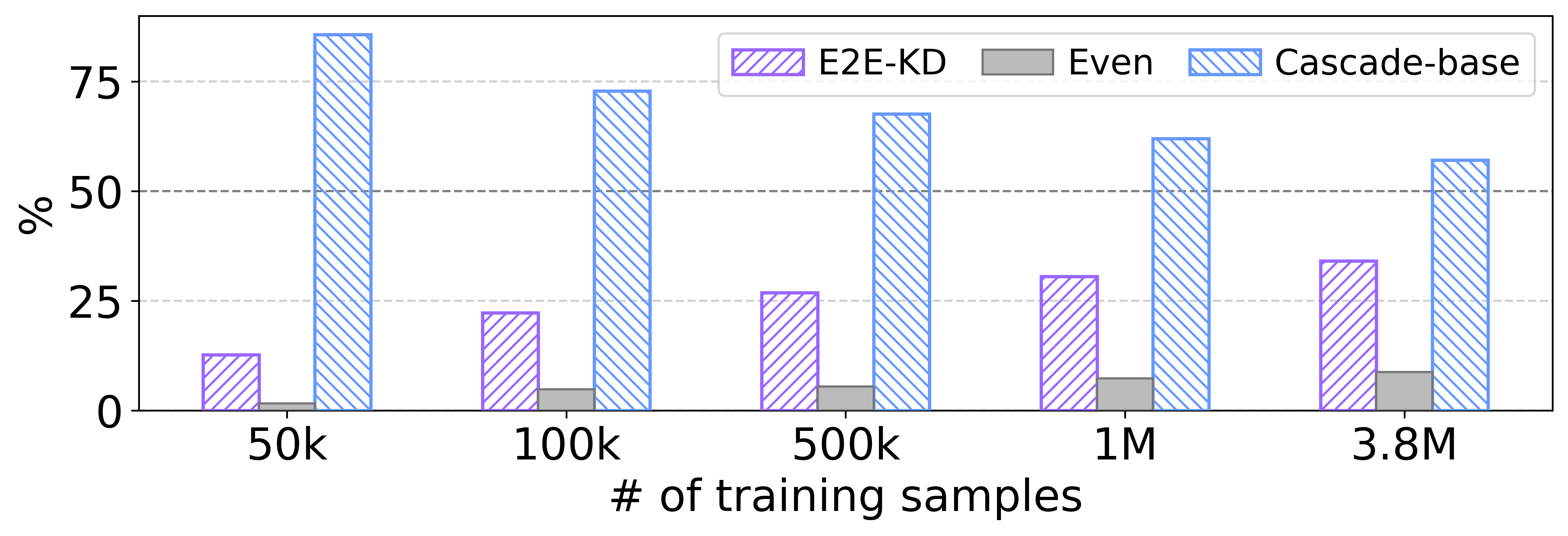
Figure 3: Results of the A/B test by ChatGPT. With more pseudo-summaries for training, more summaries by the E2E model were preferred to ones by the cascade baseline model.
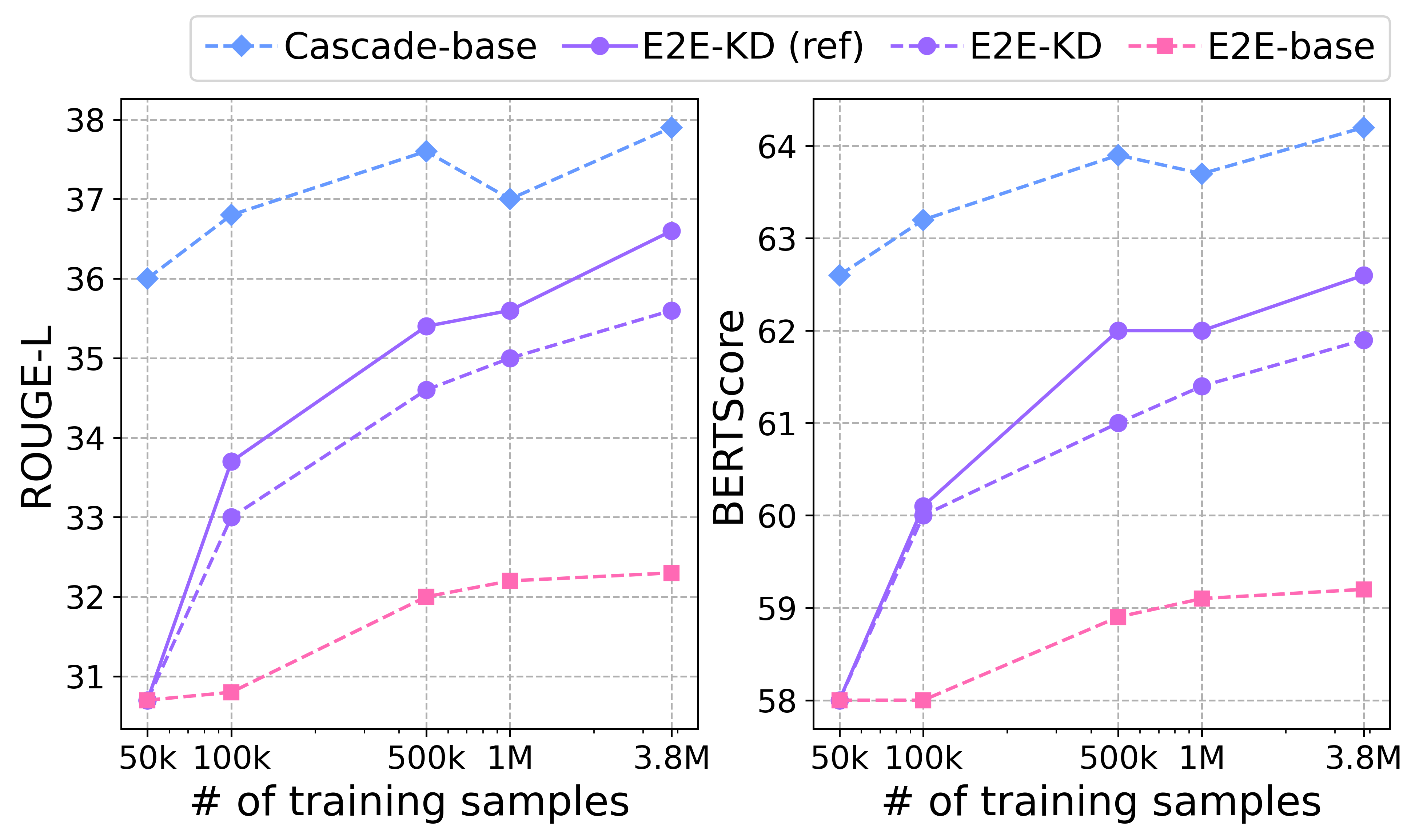
Figure 4: ``\textsf{E2E-KD (ref)} shows enhancements through refined knowledge distillation processes.
Conclusions
The research provides a novel framework for real-time, concise speech summarization via Sen-SSum, supported by comprehensive and scalable datasets. While cascade models display initial superior performance, the application of pseudo-summary knowledge distillation reveals significant potential for E2E models to achieve similar efficacy in resource-limited settings. Future investigations are encouraged to explore more integrated approaches, reducing reliance on intermediate pseudo-summaries while enhancing model adaptability to long, contextualized speech documents. The introduction of such adaptable models could represent a pivotal development in real-world applications of speech summarization technology.