CREW: Facilitating Human-AI Teaming Research
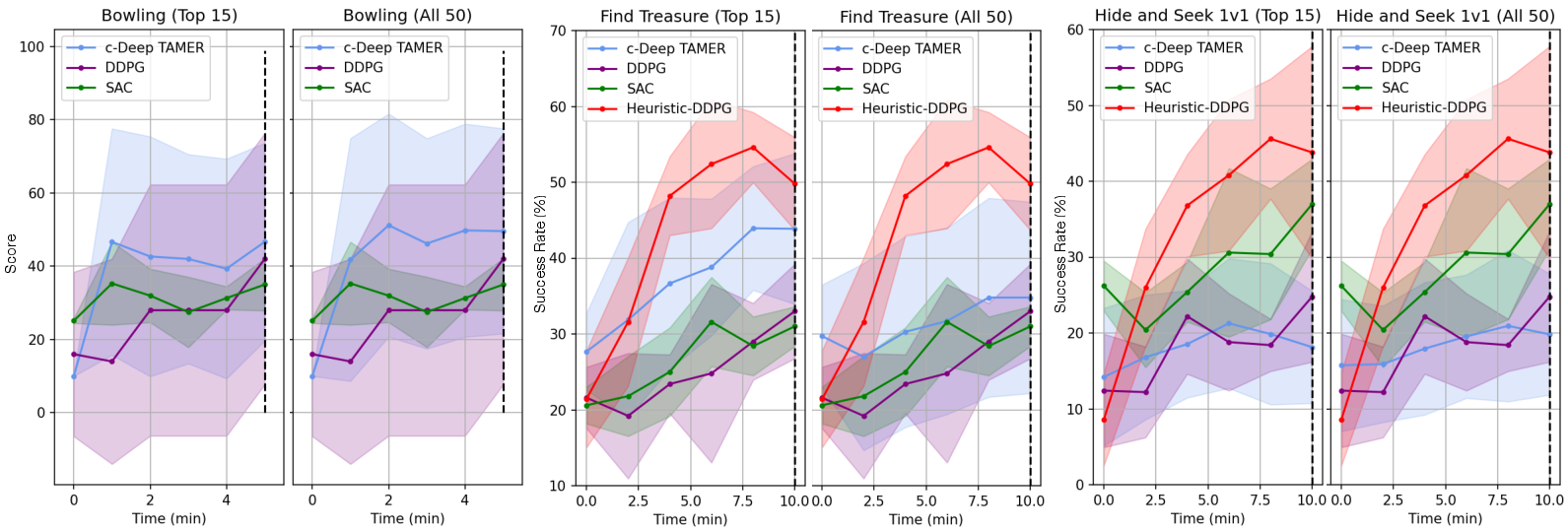
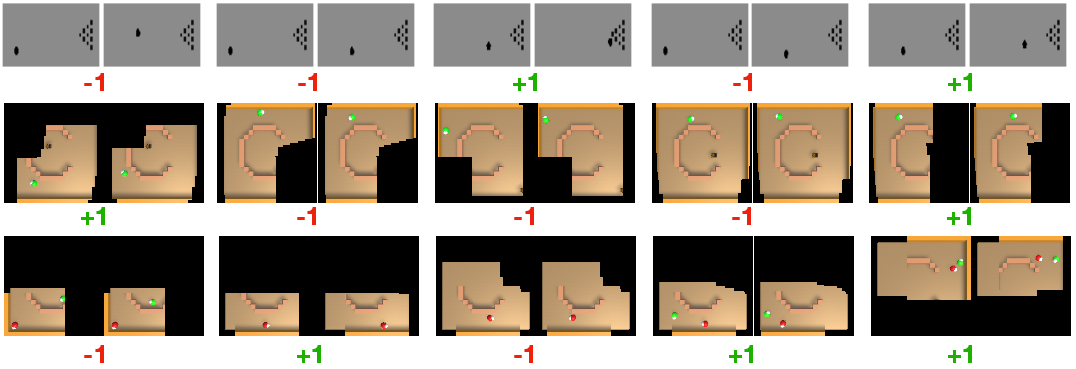
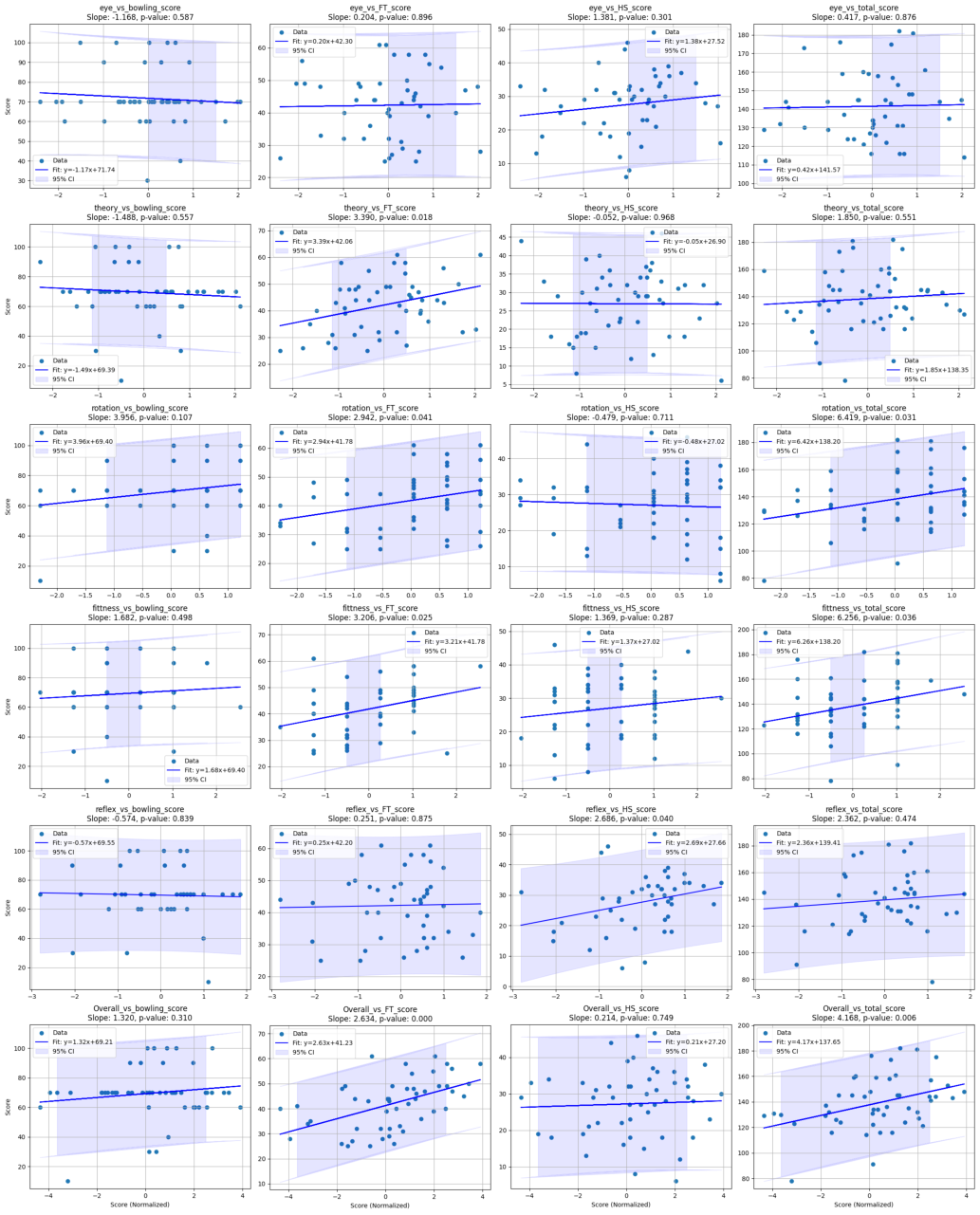
Abstract: With the increasing deployment of AI technologies, the potential of humans working with AI agents has been growing at a great speed. Human-AI teaming is an important paradigm for studying various aspects when humans and AI agents work together. The unique aspect of Human-AI teaming research is the need to jointly study humans and AI agents, demanding multidisciplinary research efforts from machine learning to human-computer interaction, robotics, cognitive science, neuroscience, psychology, social science, and complex systems. However, existing platforms for Human-AI teaming research are limited, often supporting oversimplified scenarios and a single task, or specifically focusing on either human-teaming research or multi-agent AI algorithms. We introduce CREW, a platform to facilitate Human-AI teaming research in real-time decision-making scenarios and engage collaborations from multiple scientific disciplines, with a strong emphasis on human involvement. It includes pre-built tasks for cognitive studies and Human-AI teaming with expandable potentials from our modular design. Following conventional cognitive neuroscience research, CREW also supports multimodal human physiological signal recording for behavior analysis. Moreover, CREW benchmarks real-time human-guided reinforcement learning agents using state-of-the-art algorithms and well-tuned baselines. With CREW, we were able to conduct 50 human subject studies within a week to verify the effectiveness of our benchmark.
- Nakama. URL https://github.com/heroiclabs/nakama?tab=readme-ov-file.
- Unity netcode. URL https://unity.com/products/netcode.
- Weights & biases. URL https://wandb.ai/site.
- Dqn-tamer: Human-in-the-loop reinforcement learning with intractable feedback. arXiv preprint arXiv:1810.11748, 2018.
- Deep reinforcement learning from policy-dependent human feedback. arXiv preprint arXiv:1902.04257, 2019.
- Explainable artificial intelligence for autonomous driving: A comprehensive overview and field guide for future research directions. arXiv preprint arXiv:2112.11561, 2021.
- A. Bandini and J. Zariffa. Analysis of the hands in egocentric vision: A survey. IEEE transactions on pattern analysis and machine intelligence, 45(6):6846–6866, 2020.
- Deriving machine attention from human rationales. arXiv preprint arXiv:1808.09367, 2018.
- Semantic photo manipulation with a generative image prior. arXiv preprint arXiv:2005.07727, 2020.
- Spatial abilities for architecture: Cross sectional and longitudinal assessment with novel and existing spatial ability tests. Frontiers in psychology, 11:609363, 2021.
- C. J. Boes. The history of examination of reflexes. Journal of neurology, 261(12):2264–2274, 2014.
- Torchrl: A data-driven decision-making library for pytorch. arXiv preprint arXiv:2306.00577, 2023.
- On the utility of learning about humans for human-ai coordination. Advances in neural information processing systems, 32, 2019.
- Visual hide and seek. In Artificial Life Conference Proceedings 32, pages 645–655. MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info …, 2020.
- Visual perspective taking for opponent behavior modeling. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13678–13685. IEEE, 2021a.
- Visual behavior modelling for robotic theory of mind. Scientific Reports, 11(1):424, 2021b.
- Ai-employee collaboration and business performance: Integrating knowledge-based view, socio-technical systems and organisational socialisation framework. Journal of Business Research, 144:31–49, 2022.
- Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Trust engineering for human-ai teams. In Proceedings of the human factors and ergonomics society annual meeting, volume 63, pages 322–326. SAGE Publications Sage CA: Los Angeles, CA, 2019.
- Children’s understanding of spatial relations: Coordination of perspectives. Developmental psychology, 7(1):21, 1972.
- Derail: Diagnostic environments for reward and imitation learning. arXiv preprint arXiv:2012.01365, 2020.
- B. Green and Y. Chen. The principles and limits of algorithm-in-the-loop decision making. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW):1–24, 2019.
- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018.
- Human-ai collaboration: The effect of ai delegation on human task performance and task satisfaction. In Proceedings of the 28th International Conference on Intelligent User Interfaces, pages 453–463, 2023.
- Human–machine teaming is key to ai adoption: clinicians’ experiences with a deployed machine learning system. NPJ digital medicine, 5(1):97, 2022.
- Gan-based interactive reinforcement learning from demonstration and human evaluative feedback. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 4991–4998. IEEE, 2023.
- Reward learning from human preferences and demonstrations in atari. Advances in neural information processing systems, 31, 2018.
- Unity: A general platform for intelligent agents. arXiv preprint arXiv:1809.02627, 2018.
- R. Klimoski and S. Mohammed. Team mental model: Construct or metaphor? Journal of management, 20(2):403–437, 1994.
- W. B. Knox and P. Stone. Interactively shaping agents via human reinforcement: The tamer framework. In Proceedings of the fifth international conference on Knowledge capture, pages 9–16, 2009.
- The lab streaming layer for synchronized multimodal recording. bioRxiv, pages 2024–02, 2024.
- N. Kumar and A. Jain. A deep learning based model to assist blind people in their navigation. J. Inf. Technol. Educ. Innov. Pract., 21:95–114, 2022.
- FIND: human-in-the-loop debugging deep text classifiers. CoRR, abs/2010.04987, 2020. URL https://arxiv.org/abs/2010.04987.
- Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015.
- Convergent actor critic by humans. In International Conference on Intelligent Robots and Systems, 2016.
- Rlhf-blender: A configurable interactive interface for learning from diverse human feedback. arXiv preprint arXiv:2308.04332, 2023.
- Using perceptual and cognitive explanations for enhanced human-agent team performance. In Engineering Psychology and Cognitive Ergonomics: 15th International Conference, EPCE 2018, Held as Part of HCI International 2018, Las Vegas, NV, USA, July 15-20, 2018, Proceedings 15, pages 204–214. Springer, 2018.
- Human-robot teaming for search and rescue. IEEE Pervasive Computing, 4(1):72–79, 2005.
- H. S. Nwana. Intelligent tutoring systems: an overview. Artificial Intelligence Review, 4(4):251–277, 1990.
- Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- Ancilia: Scalable intelligent video surveillance for the artificial intelligence of things. IEEE Internet of Things Journal, 2023.
- Ethics in human–ai teaming: principles and perspectives. AI and Ethics, 3(3):917–935, 2023.
- The science of teamwork: Progress, reflections, and the road ahead. American Psychologist, 73(4):593, 2018.
- D. Scharre. Sage: A test to detect signs of alzheimer’s and dementia. The Ohio State University Wexner Medical Center, 2014.
- Environment guided interactive reinforcement learning: Learning from binary feedback in high-dimensional robot task environments. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, pages 1726–1728, 2022.
- R. N. Shepard and J. Metzler. Mental rotation of three-dimensional objects. Science, 171(3972):701–703, 1971.
- R. C. Smith and P. Cheeseman. On the representation and estimation of spatial uncertainty. The international journal of Robotics Research, 5(4):56–68, 1986.
- Artificial intelligence for human flourishing–beyond principles for machine learning. Journal of Business Research, 124:374–388, 2021.
- Third eye: Exploring the affordances of third-person view in telepresence robots. In Social Robotics: 11th International Conference, ICSR 2019, Madrid, Spain, November 26–29, 2019, Proceedings 11, pages 707–716. Springer, 2019.
- Gymnasium, Mar. 2023. URL https://zenodo.org/record/8127025.
- USC Institute for Creative Technologies. Rapid integration & development environment (ride), 2024. URL https://ride.ict.usc.edu/. Accessed: 2024-05-27.
- Children’s representations of another person’s spatial perspective: Different strategies for different viewpoints? Journal of experimental child psychology, 153:57–73, 2017.
- Starcraft ii: A new challenge for reinforcement learning. arXiv preprint arXiv:1708.04782, 2017.
- Deep tamer: Interactive agent shaping in high-dimensional state spaces. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Perfection not required? human-ai partnerships in code translation. In 26th International Conference on Intelligent User Interfaces, pages 402–412, 2021.
- Fresh: Interactive reward shaping in high-dimensional state spaces using human feedback. arXiv preprint arXiv:2001.06781, 2020.
- Mastering visual continuous control: Improved data-augmented reinforcement learning. arXiv preprint arXiv:2107.09645, 2021.
- Local privacy protection classification based on human-centric computing. Human-centric computing and information sciences, 9(1):33, 2019.
- Uni-rlhf: Universal platform and benchmark suite for reinforcement learning with diverse human feedback. arXiv preprint arXiv:2402.02423, 2024.
- Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handbook of reinforcement learning and control, pages 321–384, 2021.
- J. Zhou and F. Chen. Towards trustworthy human-ai teaming under uncertainty. In IJCAI 2019 workshop on explainable AI (XAI), 2019.
- Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
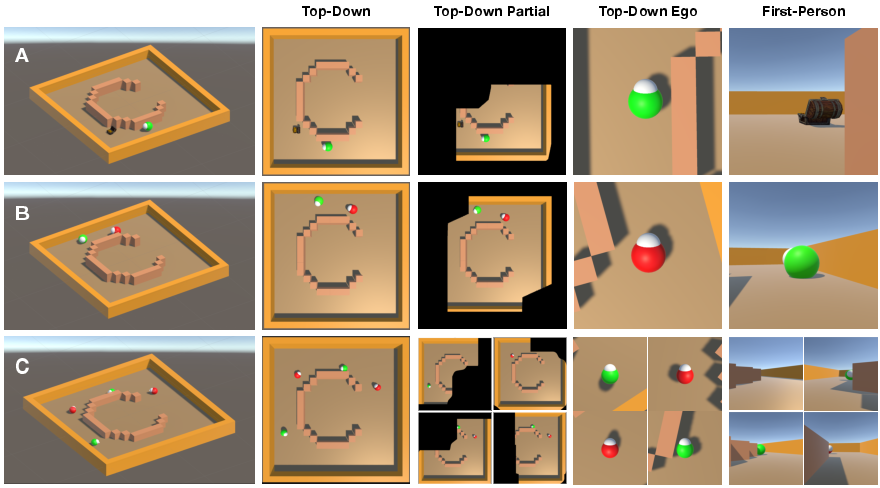
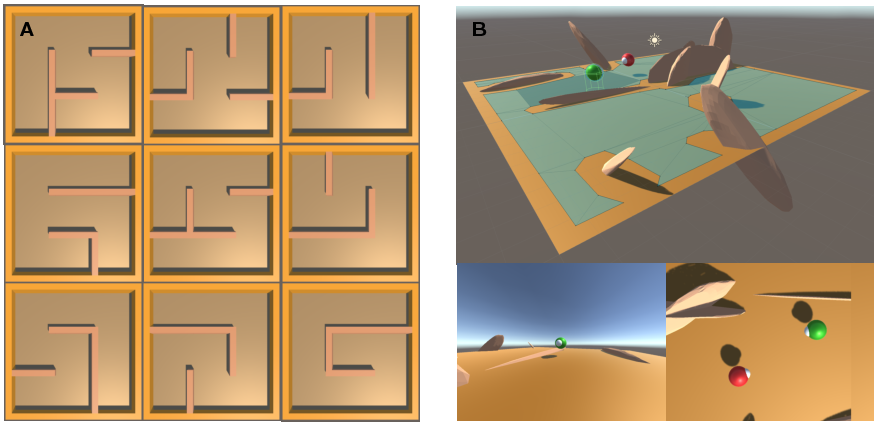
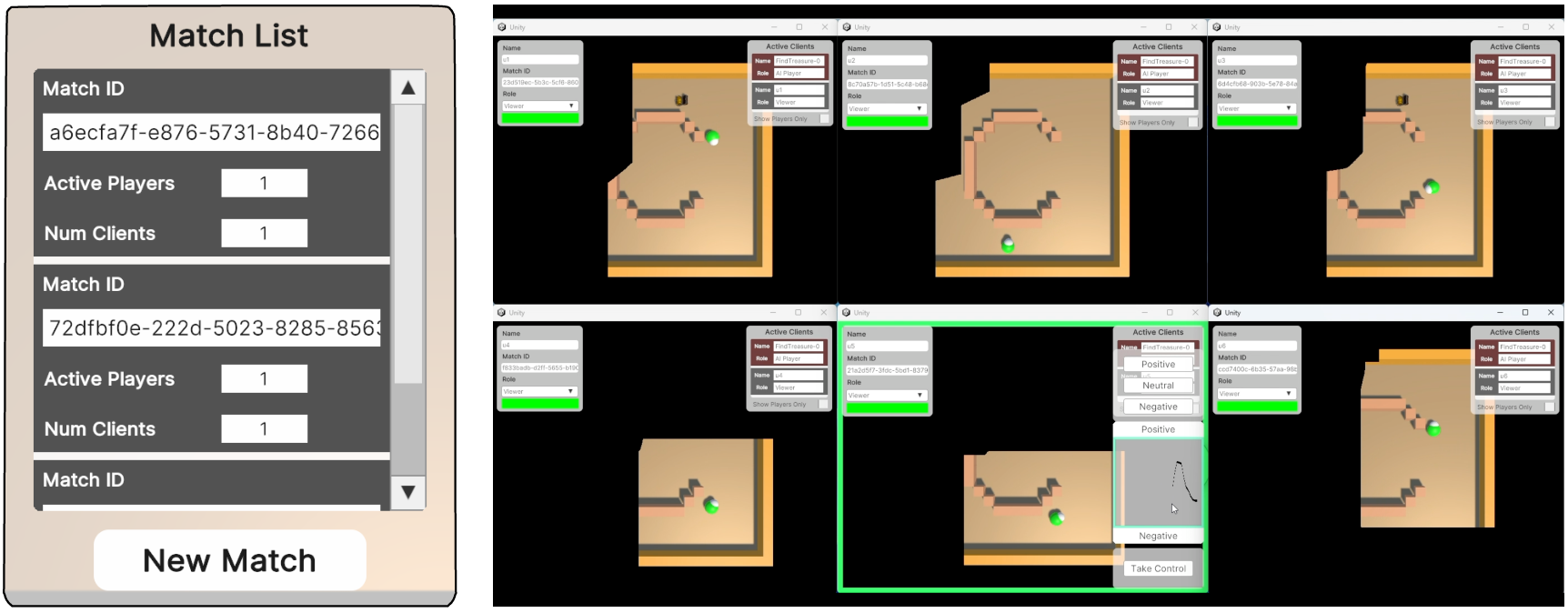
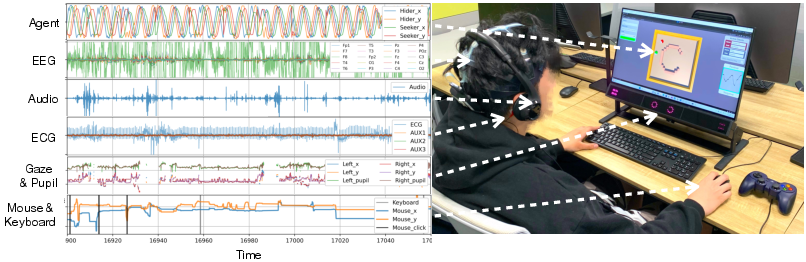
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.