- The paper presents a training-free method using latent variable optimization to integrate visual prompts into MLLMs.
- It employs an energy function to modulate attention between visual and text tokens, boosting performance in object classification and OCR tasks.
- Results indicate robust out-of-domain generalization, with attention visualization validating enhanced focus on relevant visual regions.
ControlMLLM: Training-Free Visual Prompt Learning for Multimodal LLMs
Introduction
The paper "ControlMLLM: Training-Free Visual Prompt Learning for Multimodal LLMs" presents a novel strategy for integrating visual prompts into Multimodal LLMs (MLLMs) without relying on traditional training mechanisms. This approach leverages learnable latent variable optimization to adapt MLLMs for detailed visual reasoning tasks, showing significant enhancements in adaptability and performance, especially when processing out-of-domain inputs without retraining.
Methodology
The proposed method bypasses conventional training by utilizing attention mechanisms intrinsic to MLLMs. Attention serves as the primary conduit connecting visual tokens with text prompt tokens, thus influencing the output text. By adjusting visual tokens produced by the MLP during inference, the method modulates attention to reinforce associations with specific visual regions.
The architecture involves several key components:
- Latent Variable Optimization: A learnable latent variable, initialized to zero, is adjusted through backpropagation during inference. This variable augments visual tokens, allowing control over attention distributions between text tokens and visual referents.
- Energy Function: The optimization process employs an energy function that measures alignment between visual tokens and attention focus on specified regions. This energy function guides the optimization of latent variables to heighten attention responses in designated regions, enhancing model accuracy without traditional training burdens.
- Visual Prompt Types: The method accommodates various visual prompts, including boxes, masks, scribbles, and points (Figure 1). These enable the model to flexibly adapt to different types of referring expressions during inference, highlighting an advancement in the interpretability and control of MLLMs.
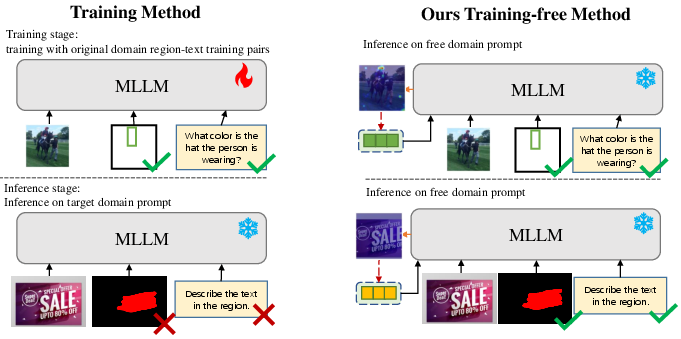
Figure 2: Comparison between the training method and our training-free method. The training method typically requires a large amount of in-domain data for training and cannot generalize to out-of-domain prompts. In contrast, our method can easily adapt to prompts from a new domain in a training-free manner.
The proposed method demonstrates enhanced performance in several tasks:
- Referring Object Classification: The model was evaluated on tasks involving object classification based on referential cues within images. The results show superiority in adaptively using box, mask, scribble, and point-based visual prompts compared to other methods.
- Generalization to Out-of-Domain Tasks: The method showcases robust out-of-domain generalization, as demonstrated by its ability to accurately recognize and classify text in scenes from distinct domains such as OCR tasks. This is critical for applications demanding flexibility and adaptability across diverse datasets and scenarios.
- Attention Visualization and Control: The paper provides visual evidence of improved attention control over tasks that involve nuanced visual reasoning, outperforming baseline models in redirecting focus to relevant visual inputs without loss of general language processing capabilities.
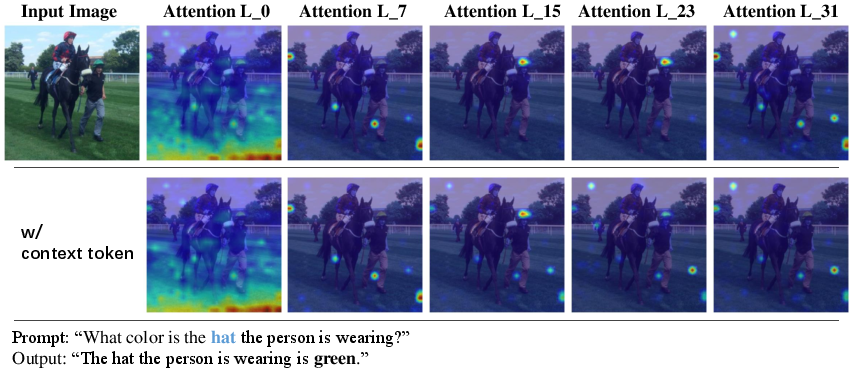
Figure 3: The attention maps in various layers of the MLLMs, with the numbers indicating the respective layer indices. The top line visualizes the attention between the prompt token ``hat'' and the visual tokens, while the bottom line visualizes the attention between the context token and the visual tokens.
Limitations and Future Work
While the training-free approach presents substantial advancements, it also introduces limitations such as excess inference overhead and dependency on pre-existing model capacities. Additionally, current implementations are confined to single-region visual prompts. Future work could expand to multi-region contexts and refine optimization strategies to further mitigate inference overhead.
Conclusion
The paper posits a significant leap towards efficient multimodal learning by eliminating the need for extensive retraining traditionally required by MLLMs to accommodate new data. The deployment of training-free methods that capitalize on latent variable optimization aligns well with real-world application scenarios that demand rapid adaptation and low computational cost. Moreover, the research suggests promising directions for refining attention and inference mechanisms beyond the scope of current AI capabilities, potentially leading to broader applications in adaptive, multimodal AI systems.

Figure 4: Manipulating attention with various methods: (a), (b), and (c) demonstrate the manipulation of the attention map by adding an adjustment coefficient η on the attention map in the first step during the model inference.