How to Measure the Intelligence of Large Language Models?
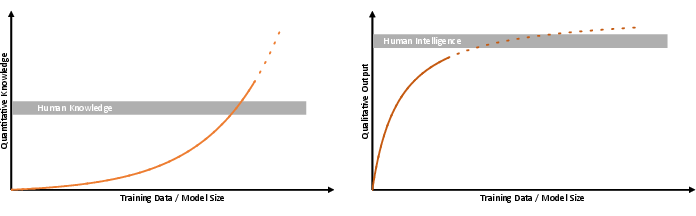
Abstract: With the release of ChatGPT and other LLMs the discussion about the intelligence, possibilities, and risks, of current and future models have seen large attention. This discussion included much debated scenarios about the imminent rise of so-called "super-human" AI, i.e., AI systems that are orders of magnitude smarter than humans. In the spirit of Alan Turing, there is no doubt that current state-of-the-art LLMs already pass his famous test. Moreover, current models outperform humans in several benchmark tests, so that publicly available LLMs have already become versatile companions that connect everyday life, industry and science. Despite their impressive capabilities, LLMs sometimes fail completely at tasks that are thought to be trivial for humans. In other cases, the trustworthiness of LLMs becomes much more elusive and difficult to evaluate. Taking the example of academia, LLMs are capable of writing convincing research articles on a given topic with only little input. Yet, the lack of trustworthiness in terms of factual consistency or the existence of persistent hallucinations in AI-generated text bodies has led to a range of restrictions for AI-based content in many scientific journals. In view of these observations, the question arises as to whether the same metrics that apply to human intelligence can also be applied to computational methods and has been discussed extensively. In fact, the choice of metrics has already been shown to dramatically influence assessments on potential intelligence emergence. Here, we argue that the intelligence of LLMs should not only be assessed by task-specific statistical metrics, but separately in terms of qualitative and quantitative measures.
- Managing extreme ai risks amid rapid progress. Science, page eadn0117, 2024.
- Towards artificial general intelligence via a multimodal foundation model. Nature Communications, 13(1):3094, 2022.
- Are emergent abilities of large language models a mirage? Advances in Neural Information Processing Systems, 36, 2024.
- Melanie Mitchell. How do we know how smart ai systems are?, 2023.
- People cannot distinguish gpt-4 from a human in a turing test. arXiv preprint arXiv:2405.08007, 2024.
- Artificial intelligence index report 2024. 2024.
- Nicola Jones. Ai now beats humans at basic tasks—new benchmarks are needed, says major report. Nature, 628(8009):700–701, 2024.
- Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. arXiv preprint arXiv:2104.08786, 2021.
- Pretraining data mixtures enable narrow model selection capabilities in transformer models. arXiv preprint arXiv:2311.00871, 2023.
- On the conversational persuasiveness of large language models: A randomized controlled trial. arXiv preprint arXiv:2403.14380, 2024.
- Chatbot arena: An open platform for evaluating llms by human preference. arXiv preprint arXiv:2403.04132, 2024.
- Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models. arXiv preprint arXiv:2406.02061, 2024.
- Dissociating language and thought in large language models. Trends in Cognitive Sciences, 2024.
- Reward is enough. Artificial Intelligence, 299:103535, 2021.
- The debate over understanding in ai’s large language models. Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.