Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials
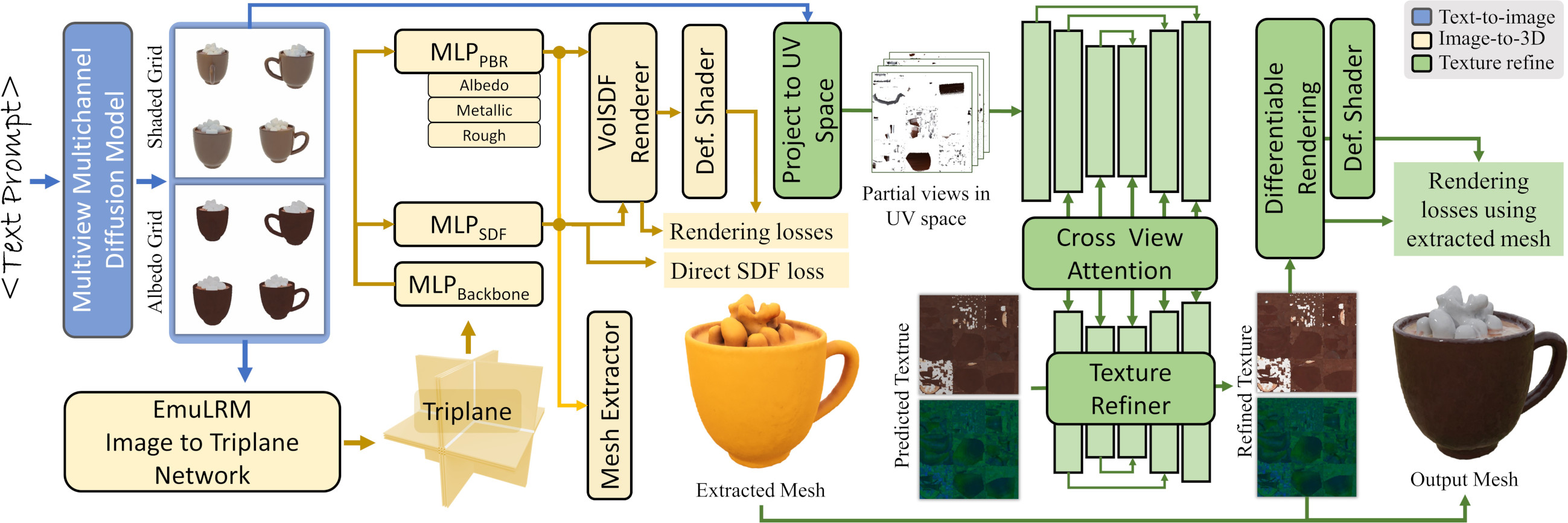
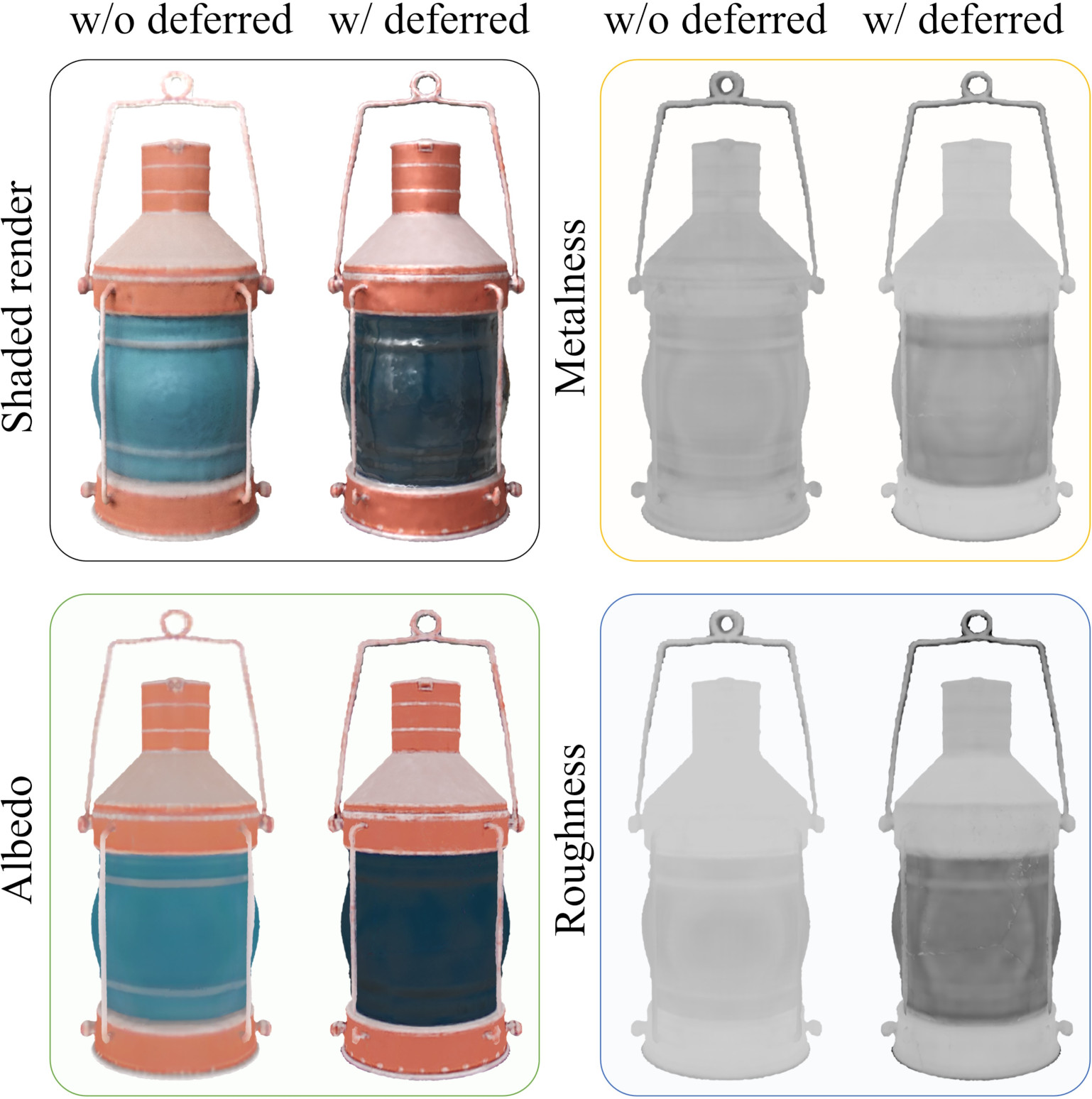
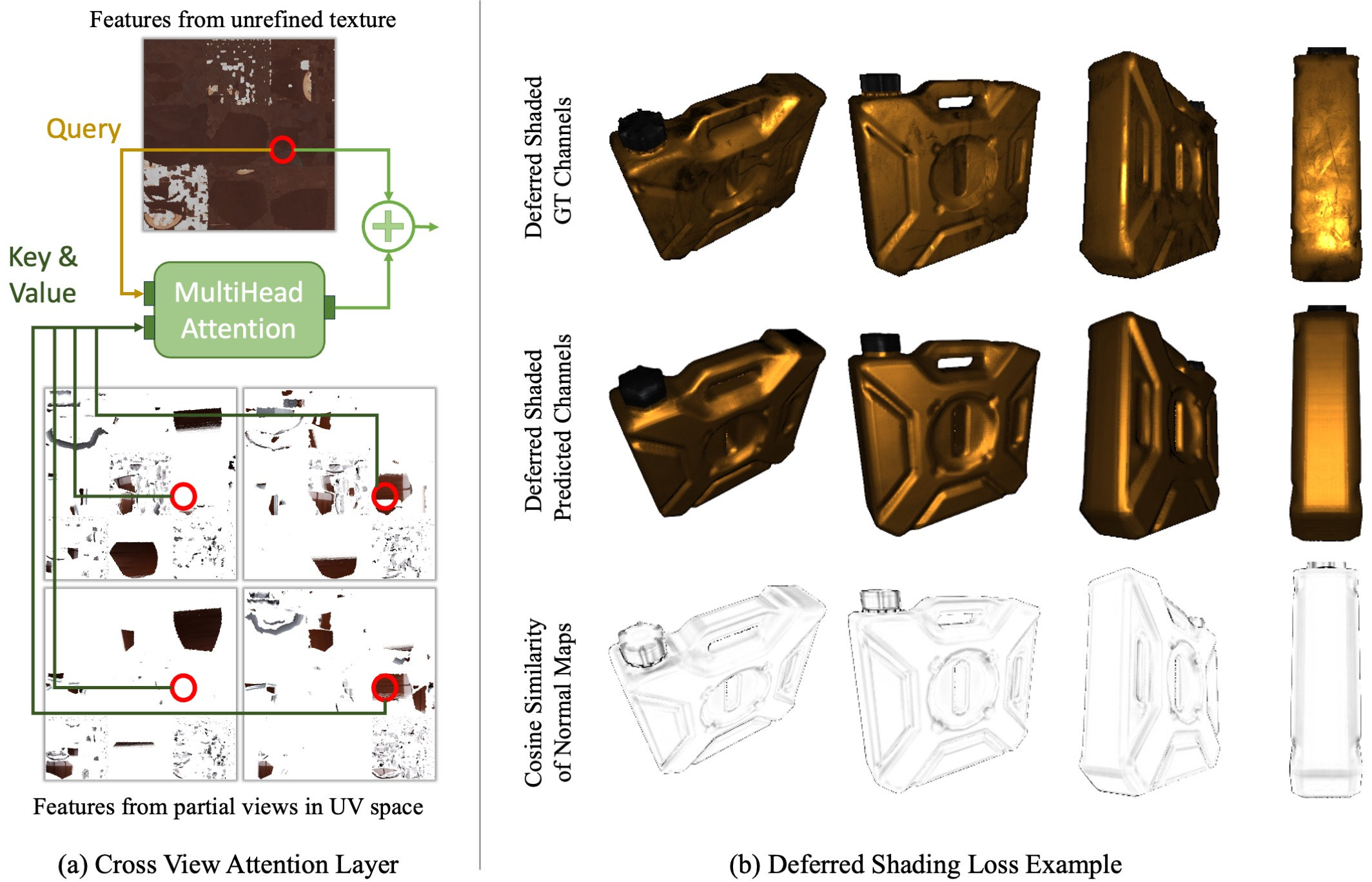
Abstract: We present Meta 3D AssetGen (AssetGen), a significant advancement in text-to-3D generation which produces faithful, high-quality meshes with texture and material control. Compared to works that bake shading in the 3D object's appearance, AssetGen outputs physically-based rendering (PBR) materials, supporting realistic relighting. AssetGen generates first several views of the object with factored shaded and albedo appearance channels, and then reconstructs colours, metalness and roughness in 3D, using a deferred shading loss for efficient supervision. It also uses a sign-distance function to represent 3D shape more reliably and introduces a corresponding loss for direct shape supervision. This is implemented using fused kernels for high memory efficiency. After mesh extraction, a texture refinement transformer operating in UV space significantly improves sharpness and details. AssetGen achieves 17% improvement in Chamfer Distance and 40% in LPIPS over the best concurrent work for few-view reconstruction, and a human preference of 72% over the best industry competitors of comparable speed, including those that support PBR. Project page with generated assets: https://assetgen.github.io
- Neural rgb-d surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6290–6301, June 2022.
- P. Beckmann and A. Spizzichino. The Scattering of Electromagnetic Waves from Rough Surfaces. Pergamon Press, 1963.
- NeRD: Neural Reflectance Decomposition from Image Collections. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- Neural-PIL: Neural Pre-Integrated Lighting for Reflectance Decomposition. arXiv preprint, 2021.
- Brent Burley. Physically-based shading at disney. Technical report, Disney, 2012.
- Lightplane: Highly-scalable components for neural 3d fields. arXiv, 2024.
- Efficient geometry-aware 3D generative adversarial networks. In Proc. CVPR, 2022.
- Generative novel view synthesis with 3D-aware diffusion models. arXiv.cs, abs/2304.02602, 2023.
- TensoRF: Tensorial radiance fields. In arXiv, 2022.
- Fantasia3D: Disentangling geometry and appearance for high-quality text-to-3D content creation: Disentangling geometry and appearance for high-quality text-to-3d content creation. arXiv.cs, abs/2303.13873, 2023.
- Cascade-Zero123: One image to highly consistent 3D with self-prompted nearby views. arXiv.cs, abs/2312.04424, 2023.
- Text-to-3D using Gaussian splatting. arXiv, (2309.16585), 2023.
- V3D: Video diffusion models are effective 3D generators. arXiv, 2403.06738, 2024.
- 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In Proc. ECCV, 2016.
- A reflectance model for computer graphics. In Doug Green, Tony Lucido, and Henry Fuchs, editors, Proc. SIGGRAPH, 1981.
- Emu: Enhancing image generation models using photogenic needles in a haystack. CoRR, abs/2309.15807, 2023.
- Improving neural implicit surfaces geometry with patch warping. In Proc. CVPR, 2022.
- An efficient method of triangulating equi-valued surfaces by using tetrahedral cells. IEICE TRANSACTIONS on Information and Systems, 74(1):214–224, 1991.
- Google Scanned Objects: A high-quality dataset of 3D scanned household items. In Proc. ICRA, 2022.
- Computer graphics - principles and practice, 3nd Edition. Addison-Wesley, 2013.
- Geo-Neus: Geometry-Consistent Neural Implicit Surfaces Learning for Multi-view Reconstruction. In NeurIPS, 2022.
- Learning deformable tetrahedral meshes for 3D reconstruction. In Proc. NeurIPS, 2020.
- CAT3D: Create Anything in 3D with Multi-View Diffusion Models. arXiv.cs, 2024.
- Differentiable Stereopsis: Meshes from multiple views using differentiable rendering. In CVPR, 2022.
- SuGaR: Surface-aligned Gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering. arXiv.cs, abs/2311.12775, 2023.
- 3DGen: Triplane latent diffusion for textured mesh generation. corr, abs/2303.05371, 2023.
- Shape, Light, and Material Decomposition from Images using Monte Carlo Rendering and Denoising. arXiv preprint, 2022.
- ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models. arXiv preprint, 2024.
- LRM: Large reconstruction model for single image to 3D. In Proc. ICLR, 2024.
- Dreamtime: An improved optimization strategy for text-to-3D content creation. CoRR, abs/2306.12422, 2023.
- Efficient-3Dim: Learning a generalizable single-image novel-view synthesizer in one day. arXiv, 2023.
- GaussianShader: 3D Gaussian splatting with shading functions for reflective surfaces. arXiv.cs, abs/2311.17977, 2023.
- Shape-E: Generating conditional 3D implicit functions. arXiv, 2023.
- Philip Torr Junlin Han, Filippos Kokkinos. Vfusion3d: Learning scalable 3d generative models from video diffusion models. arXiv preprint, 2024.
- Learning category-specific mesh reconstruction from image collections. In Proc. ECCV, 2018.
- HoloDiffusion: training a 3D diffusion model using 2D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- 3D gaussian splatting for real-time radiance field rendering. Proc. SIGGRAPH, 42(4), 2023.
- Multi-view image prompted multi-view diffusion for improved 3D generation. arXiv, 2404.17419, 2024.
- Adam: A method for stochastic optimization. Proc. ICLR, 2015.
- Instant3D: Fast text-to-3D with sparse-view generation and large reconstruction model. Proc. ICLR, 2024.
- GS-IR: 3D Gaussian splatting for inverse rendering. arXiv.cs, abs/2311.16473, 2023.
- Magic3D: High-resolution text-to-3D content creation. arXiv.cs, abs/2211.10440, 2022.
- One-2-3-45++: Fast single image to 3D objects with consistent multi-view generation and 3D diffusion. arXiv.cs, abs/2311.07885, 2023.
- One-2-3-45: Any single image to 3D mesh in 45 seconds without per-shape optimization. In Proc. NeurIPS, 2023.
- Zero-1-to-3: Zero-shot one image to 3D object. In Proc. ICCV, 2023.
- Soft rasterizer: A differentiable renderer for image-based 3D reasoning. arXiv.cs, abs/1904.01786, 2019.
- SyncDreamer: Generating multiview-consistent images from a single-view image. arXiv, (2309.03453), 2023.
- UniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation. arXiv preprint, 2023.
- Wonder3D: Single image to 3D using cross-domain diffusion. arXiv.cs, abs/2310.15008, 2023.
- ATT3D: amortized text-to-3D object synthesis. In Proc. ICCV, 2023.
- Scalable 3d captioning with pretrained models. arXiv preprint, 2023.
- IM-3D: Iterative multiview diffusion and reconstruction for high-quality 3D generation. arXiv preprint, (abs/2402.08682), 2024.
- RealFusion: 360 reconstruction of any object from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- HexaGen3D: Stablediffusion is just one step away from fast and diverse text-to-3D generation. arXiv, 2024.
- Occupancy Networks: Learning 3D Reconstruction in Function Space. In CVPR, 2019.
- NeRF: Representing scenes as neural radiance fields for view synthesis. In Proc. ECCV, 2020.
- Differentiable blocks world: Qualitative 3d decomposition by rendering primitives. abs/2307.05473, 2023.
- Share With Thy Neighbors: Single-View Reconstruction by Cross-Instance Consistency. In ECCV, 2022.
- DiffRF: Rendering-guided 3D radiance field diffusion. In Proc. CVPR, 2023.
- Instant neural graphics primitives with a multiresolution hash encoding. In Proc. SIGGRAPH, 2022.
- Extracting Triangular 3D Models, Materials, and Lighting From Images. In CVPR, 2022.
- Point-E: A system for generating 3D point clouds from complex prompts. arXiv.cs, abs/2212.08751, 2022.
- Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision. In CVPR, 2020.
- UNISURF: unifying neural implicit surfaces and radiance fields for multi-view reconstruction. arXiv.cs, abs/2104.10078, 2021.
- OpenAI. Triton: Open-source gpu programming for neural networks. https://github.com/triton-lang/triton.
- DreamFusion: Text-to-3D using 2D diffusion. In Proc. ICLR, 2023.
- Magic123: One image to high-quality 3D object generation using both 2D and 3D diffusion priors. arXiv.cs, abs/2306.17843, 2023.
- Richdreamer: A generalizable normal-depth diffusion model for detail richness in text-to-3D. arXiv.cs, abs/2311.16918, 2023.
- Accelerating 3d deep learning with pytorch3d. arXiv, 2020.
- Christophe Schlick. An inexpensive BRDF model for physically-based rendering. Comput. Graph. Forum, 13(3), 1994.
- Zero123++: a single image to consistent multi-view diffusion base model. arXiv.cs, abs/2310.15110, 2023.
- MVDream: Multi-view diffusion for 3D generation. In Proc. ICLR, 2024.
- 3D neural field generation using triplane diffusion. arXiv.cs, abs/2211.16677, 2022.
- MeshGPT: Generating triangle meshes with decoder-only transformers. arXiv.cs, abs/2311.15475, 2023.
- B. Smith. Geometrical shadowing of a random rough surface. IEEE Trans. on Antennas and Propagation, 15(5), 1967.
- DreamCraft3D: Hierarchical 3D generation with bootstrapped diffusion prior. arXiv.cs, abs/2310.16818, 2023.
- Viewset diffusion: (0-)image-conditioned 3D generative models from 2D data. In Proceedings of the International Conference on Computer Vision (ICCV), 2023.
- LGM: Large multi-view Gaussian model for high-resolution 3D content creation. arXiv, 2402.05054, 2024.
- DreamGaussian: Generative gaussian splatting for efficient 3D content creation. arXiv, (2309.16653), 2023.
- Make-It-3D: High-fidelity 3d creation from A single image with diffusion prior. arXiv.cs, abs/2303.14184, 2023.
- MVDiffusion++: A dense high-resolution multi-view diffusion model for single or sparse-view 3d object reconstruction. arXiv, 2402.12712, 2024.
- Luma Team. Luma genie 1.0. https://www.luma-ai.com/luma-genie-1-0/.
- Meshy Team. Meshy - AI 3D Model Generator with pbr materials— meshy.ai. https://www.meshy.ai/.
- TripoSR: fast 3D object reconstruction from a single image. 2403.02151, 2024.
- Theory for off-specular reflection from roughened surfaces. J. Opt. Soc. Am., 57(9), 1967.
- Llama 2: Open foundation and fine-tuned chat models, 7 2023.
- Attention is all you need. In NIPS, 2017.
- Microfacet models for refraction through rough surfaces. In Proc. Eurographics, 2007.
- Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation. In CVPR, 2023.
- NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv.cs, abs/2106.10689, 2021.
- ImageDream: Image-prompt multi-view diffusion for 3D generation. In Proc. ICLR, 2024.
- Rodin: A generative model for sculpting 3D digital avatars using diffusion. In Proc. CVPR, 2023.
- ProlificDreamer: High-fidelity and diverse text-to-3D generation with variational score distillation. arXiv.cs, abs/2305.16213, 2023.
- CRM: Single image to 3D textured mesh with convolutional reconstruction model. arXiv, (2403.05034), 2024.
- MeshLRM: large reconstruction model for high-quality mesh. arXiv, 2404.12385, 2024.
- Consistent123: Improve consistency for one image to 3D object synthesis. arXiv, 2023.
- ReconFusion: 3D Reconstruction with Diffusion Priors. arXiv preprint, 2023.
- Unsupervised learning of probably symmetric deformable 3D objects from images in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- LATTE3D: Large-scale amortized text-to-enhanced3D synthesis. In arXiv, 2024.
- NeRFactor: neural factorization of shape and reflectance under an unknown illumination. In Proc. SIGGRAPH, 2021.
- InstantMesh: efficient 3D mesh generation from a single image with sparse-view large reconstruction models. arXiv, 2404.07191, 2024.
- MATLABER: Material-Aware Text-to-3D via LAtent BRDF auto-EncodeR. arXiv preprint, 2023.
- GRM: Large gaussian reconstruction model for efficient 3D reconstruction and generation. arXiv, 2403.14621, 2024.
- DMV3D: Denoising multi-view diffusion using 3D large reconstruction model. In Proc. ICLR, 2024.
- ConsistNet: Enforcing 3D consistency for multi-view images diffusion. arXiv.cs, abs/2310.10343, 2023.
- DreamComposer: Controllable 3D object generation via multi-view conditions. arXiv.cs, abs/2312.03611, 2023.
- Volume rendering of neural implicit surfaces. arXiv.cs, abs/2106.12052, 2021.
- Multiview neural surface reconstruction by disentangling geometry and appearance. In Proc. NeurIPS, 2020.
- Mosaic-SDF for 3D generative models. arXiv.cs, abs/2312.09222, 2023.
- GaussianDreamer: Fast generation from text to 3D gaussian splatting with point cloud priors. arXiv.cs, abs/2310.08529, 2023.
- Jonathan Young. Xatlas: Mesh parameterization / uv unwrapping library, 2022. GitHub repository.
- HiFi-123: Towards high-fidelity one image to 3D content generation. arXiv.cs, abs/2310.06744, 2023.
- NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild. In NeurIPS, 2021.
- GS-LRM: large reconstruction model for 3D Gaussian splatting. arXiv, 2404.19702, 2024.
- PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting. arXiv preprint, 2021.
- The unreasonable effectiveness of deep features as a perceptual metric. In Proc. CVPR, pages 586–595, 2018.
- GALA3D: Towards text-to-3D complex scene generation via layout-guided generative gaussian splatting. arXiv.cs, abs/2402.07207, 2024.
- HiFA: High-fidelity text-to-3D with advanced diffusion guidance. CoRR, abs/2305.18766, 2023.
- Triplane meets Gaussian splatting: Fast and generalizable single-view 3D reconstruction with transformers. arXiv.cs, abs/2312.09147, 2023.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.